JavaプログラムからAzureのデータを扱ってみよう
ここでは、サンプルプログラムを通してWindows Azure4jの使い方を見ていきます。
AzureStorageへの接続とテーブルの作成
アカウントの設定とテーブル作成は、次のように記述します。
// アカウント設定
StorageAccountInfo account = new StorageAccountInfo(
URI.create("table.core.windows.net"),
false,
"test234", // account name
"h7CH1BiwQuwGejOK7EbxFhheSRLF6CXdUekazgiE23MAwb3B/4QfxPe77DhpuFUL7IAubtN+oFsc6f2G/bo1vg==" // primary access key
);
TableStorage ts = TableStorage.create(account);// TableStorageへ接続
CloudTable table = ts.getWindowsAzureTable("testtable");// AzureTableへ接続
//テーブルが存在しない場合、作成
if(!table.doesTableExist()){
table.createTable();
}
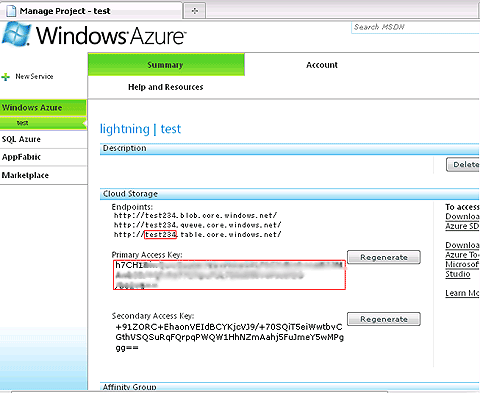
ここでは、Azure Storage作成時のアカウント名をtest234に、アクセスキーが「h7CH1...1vg==」の例です。ストレージ上に'testtable'という名前のテーブルを作成します。
アカウント名とアクセスキーは、Windows Azureポータルの各リソースの詳細画面から確認できます。図8の例で示すと、エンドポイントのURLのホスト名とPrimary Access Keyを指定します。
エンティティクラスの定義
Azure Tableは、Entity Attribute Value形式でデータを格納しますが、WindowsAzure4jを利用すると、格納するエンティティの型を定義できます。
エンティティの型定義を行うことにより、テーブル内のデータモデルの一貫性を保てます。ユーザー情報として名前、年齢、住所、電話番号を持つエンティティの例をリスト1に示します。
リスト1 エンティティの定義(UserEntity.java)
エンティティは、TableStorageEntityクラスを継承して作成します。コンストラクタでは、下記のようにパーティションキーとRowキーを指定します。
public UserEntity(String partitionKey, String rowKey){
super(partitionKey, rowKey);
}
Azure Tableでは、各データは「パーティション」と呼ばれる領域に分割して保存されます。1パーティションのデータは1サーバ内に格納されるので、頻繁にアクセスされるデータ同士は1パーティション内に格納しておくといいでしょう。
Rowキーは、パーティション内で一意に識別されるIDを指定します。パーティションキーとRowキーは、2つの組み合わせで一意のデータとして識別されます。異なるパーティションでは、Rowキーが同じでも別のデータとして扱われます。
後は、settter/getterを付与したプロパティ定義すれば、データモデルになります。
定義したエンティティは、下記のように記述してテーブルにモデルとして設定します。
// エンティティクラスをセット
table.setModelClass(UserEntity.class);
エンティティのインサート
エンティティのインサート例を示すと、次のようになります。
//バッチ処理の開始
table.startBatch();
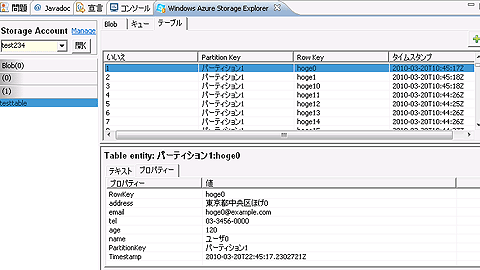
for(int i=0;i<10;i++){
UserEntity e = new UserEntity("パーティション1","hoge"+i);
e.setName("ユーザ"+i);
e.setEmail("hoge"+i+"@example.com");
e.setAge(i%20+20);
e.setTel("03-3456-000"+i);
e.setAddress("東京都中央区ほげ"+i);
table.insertEntity(e);
}
// バッチ処理の実行
table.executeBatch();
TableのinsertEntityメソッドでデータを挿入します。上記のstartBatch()とexecuteBatch()は必ずしも必要ではありませんが、複数のデータ処理を行う場合は付けておいた方がいいでしょう。
Azure Tableでは、デフォルトでは1データアクセスごとにAzure Tableへデータを書き込みにいきますが、バッチを利用すれば複数のSQLをまとめて実行でき、高速に実行できます。環境にも左右されると思いますが、筆者の環境では約30倍の差が出ました。
検索
テーブル内のデータを取得するには、次のようにQueryクラスを利用して行います。
List<TableStorageEntity> list = table.retrieveEntities(Query.select().lt("age", "30").top(3));
JPAやHibernateのクライテリアのように、オブジェクトの組み合わせで検索条件を指定します。検索条件の詳細は、「QueryクラスのAPI」をお読みください。
上記のAPIの中で、where句が使えそうですが、WindowsAzure4jのwhere句は、SQLのwhere句と異なり、Azure Tableのフィルタ処理のための検索条件を指定します。
例えば、ageが30以上のエンティティの検索は、次のようになります。
List<TableStorageEntity> list = table.retrieveEntities(Query.select().lt("age", "30").top(3));
where句の検索条件の詳細は、「Windows AzureデータストレージTableサービス」をご覧ください。
アップデート
検索で取得したオブジェクトの内容を変更して、テーブルへ反映させるには、テーブルクラスのupdateEntityメソッドを使います。
table.updateEntity(e);
削除
エンティティをテーブルから削除するには、CloudTableクラスのdeleteEntityメソッドを使います。
table.deleteEntity(e);
アップデートと削除も、インサートと同じくバッチを利用して実行すると、実行が速くなります。
コラム WindowsAzure4jのログのデフォルト設定は、ちょっとうざい
WindowsAzure4jのデフォルトのログの設定では、デバッグモードで詳細なログを出力するようになっていて、ちょっとうざいです。次のように記述したlog4j.propertiesをおいて、ログを減らしておくといいでしょう。
log4j.rootLogger=info, stdout
log4j.addivity.org.apache = true
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
さらに、Tomcatからも使えるらしい
本稿では、Windows Azure4jを利用して、Windows AzureのAzure TableをJavaから操作する方法を紹介しました。本稿で紹介したコードのサンプルは、こちらからダウンロード(azuretest.zip)できるので、確認してみてください。
ほかにも、Hosted Serviceと「Windows Azure Tomcat Solution Accelerator」を利用すると、Windows AzureのHosted Service上でTomcatを動作できようになり、Webアプリケーションをクラウド上で公開できるようになります。興味がある人はぜひチャレンジしてみてはいかがでしょうか。
編集部より:Windows Azureを含むクラウドコンピューティングに興味を持った読者は下記インデックスページをご確認ください。随時更新中で、クラウド・コンピューティングの最新情報も分かります。
- exe/dmgしか知らない人のためのインストール/パッケージ管理/ビルドの基礎知識
- これでGitも怖くない! GUIでのバージョン管理が無料でできるSourceTreeの7つの特徴とは
- DevOps時代の開発者のためのOSSクラウド運用管理ツール5選まとめ
- GitHubはリアルRPG? そして、ソーシャルコーディングへ
- ついにメジャーバージョンUP! Eclipse 4.2の新機能7選
- いまアツいアジャイルプロジェクト管理ツール9選+Pivotal Tracker入門
- Git管理の神ツール「Gitolite」なら、ここまでできる!
- Java開発者が知らないと損するPaaSクラウド8選
- Eclipse 3.7 Indigo公開、e4、Orion、そしてクラウドへ
- AWSの自由自在なPaaS「Elastic Beanstalk」とは
- Ant使いでもMavenのライブラリ管理ができるIvyとは
- 「Hudson」改め「Jenkins」で始めるCI(継続的インテグレーション)入門
- Bazaarでござ〜る。猿でもできる分散バージョン管理“超”入門
- Review Boardならコードレビューを効率良くできる!
- Team Foundation ServerでJava開発は大丈夫か?
- コード探知機「Sonar」でプロジェクトの深海を探れ!
- 単体テストを“神速”化するQuick JUnitとMockito
- Java EE 6/Tomcat 7/Gitに対応したEclipse 3.6
- AzureのストレージをJavaで扱えるWindowsAzure4j
- 究極の問題解析ツール、逆コンパイラJD-Eclipseとは
- AWS ToolkitでTomcatクラスタをAmazon EC2上に楽々構築
- DB設計の神ツール「ERMaster」なら、ここまでできる
- Webのバグを燃やしまくるFirebugと、そのアドオン7選
- Googlerも使っているIntelliJ IDEAのOSS版を試す
- JUnit/FindBugs/PMDなどを総観できるQALab/Limy
- ブラウザを選ばずWebテストを自動化するSelenium
- Eclipse 3.5 Galileoの「実に面白い」新機能とは
- App Engine/AptanaなどJavaクラウド4つを徹底比較
- Aptanaなら開発環境とクラウドの連携が超お手軽!
- 分散バージョン管理Git/Mercurial/Bazaar徹底比較
- SubversionとTracでファイル管理の“迷宮”から脱出
- Trac Lightningで始めるチケット式開発「電撃」入門
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
- クラウド技術入門
クラウド・コンピューティング技術。そのすべては、ここにある