“Hadoopエンジニアは年収3000万円”――「DW 2.0」とDBエンジニアのキャリア、米国エンジニア事情:Database Expertイベントリポート(2/3 ページ)
“データウエアハウスの父”ビル・インモン氏が日本のデータベースエンジニアを前に講演、データの性質が変わってきたいま、データウエアハウスの次の形態としてインモン氏が示したのは「DW 2.0」。その根幹を支えるテクノロジを扱うスキルを持つエンジニアが、いま北米で“引く手あまた”だという話も。
ビッグデータをも取り込む“DW 2.0”とは?
このように、データウエアハウス誕生までの経緯と現状の運用、そして課題を整理したインモン氏は、データウエアハウスの次の進化に当たるものとして「Corporate Information Factory」という考え方を示した。
この考えを具現化するものとして、インモン氏は、現在のデータウエアハウスが受け持つデータに加え、非構造化データをも取り込んだ次世代のデータウエアハウスアーキテクチャ「DW 2.0」を推進しているという。
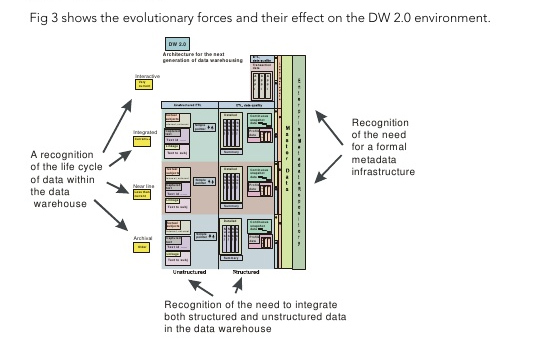
DW 2.0を簡単に整理すると、データの種類を大きく構造化データと非構造化データの二つに分け、さらに、データの生成、利用の頻度別に四つに分け、それぞれに最適なシステムを適用していくアプローチということができる。
構造化データはこれまでのトランザクションシステム(基幹系システム、RDBMSで管理される)のことを指す。非構造化データは、頻繁に生成されるテキストや画像データといった、いわゆるビッグデータのことだ。インモン氏は、ビッグデータを扱う具体的なシステムとして「Apache Hadoop(Hadoop)」を挙げており、実際のコンサルティングなどでも、Hadoopを用いたソリューションを提供しているという。
一方、データの生成、利用頻度の区分は、速い順に「Interactive(Very current)」「Integragted(Current++)」「Near Line(Less than current)」「Archival(Older)」に分けられる。より高速な処理が求められるものは、Hadoopなどの技術を用いることになる。
なお、これらシステムコンポーネント間を連携するためにメタデータを用いることもDW 2.0の特徴の一つだ。DW 2.0におけるメタデータは、データの明細、パラメーター、しきい値や統計値、ステータスコードなどで構成されるという。
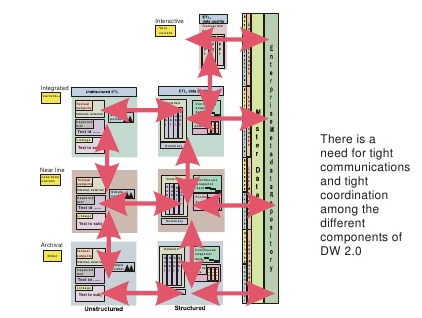
インモン氏が提唱するDW 2.0は、前述の旧来のデータウエアハウスが持っていた課題「設計/構築/利用/運用の難しさ」――運用を効率化するために周辺ツールと連携した複雑な設計、効率化のためのデータ格納方法検討の難しさを解消しつつ、非構造化データのような新しい種類のデータを取り込むものとして位置付けられる。
この講演の後で行われたQ&Aセッションでは会場から「結局のところ、データウエアハウスにはRDBMSとNoSQLのどちらが良いのか?」といった質問もあった。DW 2.0アーキテクチャという考え方は分かったとして、それを実現するのは、結局どのテクノロジなのだろうか?
インモン氏は「利用する状況によって変わるので、個別の技術に答えるのは難しい」としながらも、自身の経験から、「大規模なデータを格納する必要があるならテラデータ製品が向いていると考えます。中規模ならばオラクル製品がいい。とてつもなく大きなデータならば、HadoopをOracle DatabaseやSQL Serverなどのデータベース製品と組み合わせる方法が適しているといえるでしょう」と、経験上の指針を示してくれた。
Copyright © ITmedia, Inc. All Rights Reserved.