
構造体のメンバーをビットに割り当てる
構造体には1バイトの大きさを持つchar型のメンバーを含むことができますが、ビットフィールドを使うとより小さなデータを表現することもできます。ビットフィールドは構造体のメンバー宣言に続けて、“:”(コロン)とビット幅を指定することで宣言します。
struct bunrui {
unsigned int mousho_bi : 1; // 猛暑日
unsigned int manatsu_bi : 1; // 真夏日
unsigned int natsu_bi : 1; // 夏日
unsigned int fuyu_bi : 1; // 冬日
unsigned int mafuyu_bi : 1; // 真冬日
unsigned int nettai_ya : 1; // 熱帯夜
};
ビットフィールドの宣言で使用できる型は_Bool、signed int、unsigned intです。この例ではunsigned intを使っていて、その日が猛暑日であったかどうかなどを1ビットで表せるようにしてあります。ビットフィールドのメンバーへのアクセスは、ビットフィールドではない構造体のメンバーと同じように “.”演算子を利用します。
PleiadesやVisual C++の環境では、unsigned int型のオブジェクトは32ビットの大きさを持ちます。しかしビットフィールドとして宣言した場合には、そのビット幅分だけの大きさが隙間なく用意されます。つまりこの6つのビットは並んで用意されます。
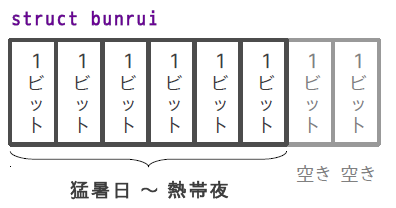
ここでは1ビット幅のビットフィールドしか使用しませんでしたが、宣言に利用した型の大きさまでは宣言に利用できますので、必要であれば10ビットや20ビットといったフィールドを宣言することもできます。
ただしビットフィールドの記述方法や動作は処理系ごとに異なる部分が多いため、使用するときにはコンパイラーのマニュアルを確認してください。
現代のコンピューターでは効率を多少上げることよりも、ソースコードの書きやすさや読みやすさを優先したほうが良い場合が多くなっています。ですから、扱いづらいビットフィールドをあえて使う必要はありません。システム プログラムのようにビット単位での処理をした方が明らかに合理的であるようなときに使うこととして、それ以外の場合にはこういうものがあるという程度に覚えておけば問題ないでしょう。
構造体や配列の大きさを知る
オブジェクトの大きさを得るためにはsizeof演算子を使いました。同じように構造体や配列の大きさを得ることができます。
// struct kisho => 20 (環境により異なる)
printf("struct kisho => %d\n", sizeof(struct kisho));
// kion => 192 (環境により異なる)
printf("kion => %d\n", sizeof(kion));
// kisho_day => 480 (環境により異なる)
printf("kisho_day => %d\n", sizeof(kisho_day));
構造体ではパディングが追加されることがあるためサイズは環境によって変わりますが、sizeof演算子はパディングも含めた大きさを返します。構造体のメンバーの大きさもsizeofで得ることができます。ただしビットフィールドに対しては使えません。
また、配列全体の大きさだけではなく、配列の要素数を得たいときもあります。要素数は、配列全体の大きさを、要素1つ分の大きさで割ると得られます。
// kion => 24
printf("kion => %d\n", sizeof(kion) / sizeof(kion[0]));
C99以前は、配列を宣言するときに指定できる要素数は、定数だけでした。つまり、変数を指定することができません。つまりそれは、コンパイル時に配列の大きさが決まるということです。
C99で導入された可変長配列を使うと、宣言時に変数が使えるようになり、プログラムの実行時に大きさを決めることができるようになります。つまり、「int a; /* a の値を変更 */ int b[a];」といったことが可能になります。
大変便利なように思われるかもしれませんが、これまでのCプログラミングと考え方が異なるためか、現時点ではあまり使われていないようです。慣れるまではこの機能のことは忘れて、配列は固定長で扱うと考えておいたほうがいいでしょう。
関係する整数定数をまとめて宣言する列挙型
気象データに天気を追加してみましょう。とりあえず、晴れ、曇り、雨の3種類を扱えるようにしたいとして、どのように実装すればよいでしょうか。単純に考えると、整数型を用意しておいて、晴れ=1、曇り=2、雨=3 として値を入れておいたらどうか、という案が考えられます。
この案は良い方法ですが、「晴れとは1である」というルールを覚えておくのが大変です。また、ソースコード上に1という数値が登場した場合、それが天気の晴れを意味するのか、あるいは別の意味を持つ1という値なのか、区別するのが難しくなります。
このようなときには列挙型を使って、整数の値に名前をつけます。
enum tenki {
HARE = 1, // 晴れ
KUMORI = 2, // 曇り
AME = 3 // 雨
};
こうしておくと、enum tenkiという新しい型が作られ、そこにはHARE、KUMORI、AMEという値を入れることができるようになります。enumで新たに作られる型(例ではenum tenki)を“列挙型”、新たに作られた値(例ではHAREなど)を“列挙定数”と呼びます。
enum tenki t; // enum tenki型のオブジェクトを宣言した。 t = HARE; // そして今日は晴れである。
HAREという値は、実際にはint型を持つ1という整数値と同じですから、「t = 1」と書くこともできます。しかしながら「t = 1」と「t = HARE」を比べた場合、後者のほうが「晴れ」という天気を扱っているということがはっきり分かりますので、より良いソースコードと言えます。
なお、列挙定数の宣言で使用する “=”(イコール)は省略できます。省略すると、その直前の列挙定数に1を加えたものになります。先頭の列挙定数の“=”を省略すると、その値は0になります。
列挙定数として宣言された値は、実際にはint型のオブジェクトとして処理されます。本文中でも説明したとおり、enum tenki型のオブジェクトtに対して、「t = HARE」はもちろん、「t = 1」という式も正しいということになります。
これはつまり、列挙定数を整数型のオブジェクトに代入することが可能ということです。つまりint型のオブジェクトaに対して「a = HARE」ということが可能であるということです。
ただしこれが文法上許されているとしても、分かりやすいコードであるかどうかとは別の問題です。可能な限り宣言に利用した列挙型のオブジェクトを定義して、そこに列挙定数を入れるというコードが良いでしょう。
構造体や配列の値を初期化する
charやintなどの型と同じように、構造体や配列も宣言と同時に初期化することができます。
// 気象データの構造体を宣言と同時に初期化します。
struct kisho {
double kion; // 気温
double shitsudo; // 湿度
unsigned int kousuiryo; // 降水量
} k = {
18.0,
60.0
};
// 気温を宣言と同時に初期化します。
double kion[24] = { 20.0, 19.1, 18.2 };
構造体の初期化では、宣言したメンバーの宣言順に値を並べて書くことで、それぞれのメンバーに値を入れることができます。 この例では、気象データkのkionには18.0、shitsudoに60.0が入ります。配列kionも同じように、配列の先頭要素kion[0]から指定した値が順に入ります。さらに、値が指定されていない部分は0に初期化されます。つまり気象データkのkousuiryoと、気温kionの4つ目以降の要素(kion[3]以降)には0が入ります。
さらにchar型の配列については文字列リテラル(ダブルクォートで囲った文字列)で初期化することもできます。
char str1[] = "abc";
// このコードは次と同じ。
// char str1[] = { 'a', 'b', 'c', '\0' };
このようなやり方での初期化は便利でよく使われますし、初期化以外のところにも書けるのですが、残念ながら関数の実引数のところでは使えません。
// 気象データを引数に受け取る関数。
void func(struct kisho k) { /* ... */ }
int main(void) {
// 気温18.0、湿度60.0の気象データを渡したいが、次のようには書けない。
func( { 18.0, 60.0 } ); // エラー!
// 次のように書く必要がある。
struct kisho k = { 18.0, 60.0 };
func(k); // OK!
return EXIT_SUCCESS;
}
文字列リテラルを用いたchar型配列の初期化についても、同じやり方で関数に配列を渡すことはできません。実引数として構造体を渡したいときには、構造体の変数を宣言し、その値を指定してから渡す必要があります。
そこでC99からの新機能として、複合リテラルが使えるようになりました。複合リテラルを使うと構造体や配列の値を素直に記述することができます。
func( (struct kisho){ 18.0, 60.0 } ); // C99ではOK!
func呼び出しの実引数が複合リテラルです。(){}という記述は、これ全体で複合リテラル演算子と言います。()の中には型の名前を、{}の中は値を書きます。{}の中は、先ほどの初期化と同じ書き方ができますので、素直に理解できるかと思います。ここでは構造体を例にしましたが、配列でも同じように書くことができます。
さらにC99からは、要素指示子付きの初期化という方法も追加されています。これは初期化の時に、宣言の並びに関係なく指定した要素の値のみ初期化する方法です。
// 気象データ構造体kの湿度だけ値を指定する。残りのメンバーの値は0。
struct kisho k = { .shitsudo = 60.0 };
// 気温kionの2つ目と3つ目の要素だけ値を指定する。残りの要素の値は0。
double kion[24] = { [1] = 20.0, [2] = 18.2 };
複合リテラルと要素指示子付きの初期化は組み合わせて使うこともできます。活躍できる場面は多いと思いますので、C99が使える環境であればぜひ使ってみてください。
今回学んだこと
- 構造体を使うと、複数の型を含む新しい型を作ることができます
- 配列を使うと、ひとつの型のオブジェクトがたくさん集まったデータを扱えます
- 共用体を使うと、重なりあった新しい型を作ることができます
- ビットフィールドを使うと、構造体のメンバーの大きさをビット単位で指定することができます
- 構造体や配列を宣言と同時に初期化することができます
- C99以降では構造体や配列の初期化に複合リテラルや要素指示子付きの初期化が使えます
2/2 |
| Index | |
| 派生型でもっと便利にデータを扱う | |
| Page1 構造体は他のデータ型を含むことができる 共用体は重なりあったデータを表現する 配列は同じ型のオブジェクトを複数まとめて扱う | |
| Page2 構造体のメンバーをビットに割り当てる 構造体や配列の大きさを知る 関係する整数定数をまとめて宣言する列挙型 構造体や配列の値を初期化する 今回学んだこと | |
| Coding Edgeお勧め記事 |
| いまさらアルゴリズムを学ぶ意味 コーディングに役立つ! アルゴリズムの基本(1) コンピュータに「3の倍数と3の付く数字」を判断させるにはどうしたらいいか。発想力を鍛えよう |
|
| Zope 3の魅力に迫る Zope 3とは何ぞや?(1) Pythonで書かれたWebアプリケーションフレームワーク「Zope 3」。ほかのソフトウェアとは一体何が違っているのか? |
|
| 貧弱環境プログラミングのススメ 柴田 淳のコーディング天国 高性能なIT機器に囲まれた環境でコンピュータの動作原理に触れることは可能だろうか。貧弱なPC上にビットマップの直線をどうやって引く? |
|
| Haskellプログラミングの楽しみ方 のんびりHaskell(1) 関数型言語に分類されるHaskell。C言語などの手続き型言語とまったく異なるプログラミングの世界に踏み出してみよう |
|
| ちょっと変わったLisp入門 Gaucheでメタプログラミング(1) Lispの一種であるScheme。いくつかある処理系の中でも気軽にスクリプトを書けるGaucheでLispの世界を体験してみよう |
|
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
||
注目のテーマ




Coding Edge 記事ランキング
- 失われゆく「COBOL」技術、レガシーコードとの向き合い方をGitHubが解説
- CTC、COBOLコードをJavaに自動変換する「re:Modern」を提供開始
- 安全なクラウド上の「Claude Code」をブラウザから利用できる「Claude Code on the web」が登場
- PHP開発者の58%が「別の言語に移行しない」と回答、する場合の代替言語は?
- 安全性を保つならやっぱりサンドボックス AIエージェントから“外部ツールを安全に使う”ための仕組みを提供開始
- AIならPMやデザイナーでもボタンの色を変更できる プロダクトチーム向け開発支援ツール「Matter」発表
- 「MCPはAPIではない」――Dockerが解説するAIエージェント開発のベストプラクティスとは
- 「Visual Studio Code」と「Ollama」で簡単に始められる、安心・安全なローカルAI活用術
- RAGを使ってAIの回答精度を向上させる一連の流れを、Spring AIで理解する
- VBAでファイル名や拡張子を取得する方法、特殊フォルダを取得する方法
- 失われゆく「COBOL」技術、レガシーコードとの向き合い方をGitHubが解説
- 無料で「Cursor」を学べる公式学習コースをAnysphereが公開
- PHP開発者の58%が「別の言語に移行しない」と回答、する場合の代替言語は?
- 「VS Code」と「Copilot」でローカルAIモデルを活用 Microsoftがガイドを解説
- 安全なクラウド上の「Claude Code」をブラウザから利用できる「Claude Code on the web」が登場
- OpenAIが「Codex」を正式リリース、Slack連携やSDKで開発効率を加速
- RAGを使ってAIの回答精度を向上させる一連の流れを、Spring AIで理解する
- AIマルチエージェント開発を加速する「Microsoft Agent Framework」 Microsoftが発表
- Google、AIコーディングエージェント「Jules」をCLIから操作できる「Jules Tools」公開 インストール方法や利用例を解説
- ローコードの醍醐味、カスタマイズ開発のメリットとリスクを考える――kintone API、スペースの基本

