
連載 XMLツールでプログラミング(2)
DOMによるXML文書の操作
XML文書はある構造に従って作成されている。この構造を持つために、コンピュータで柔軟に扱うことができるわけだ。XML Parserは、XML文書が正しい構造を持つかを検証し、XML文書に対する操作を行うAPIを提供している。XML文書を操作するために不可欠の存在だ。
赤木伸
日本オラクル株式会社
2000/8/25
今回は、実際にXML文書を読み込んだり、データを操作したりするためのツールを説明していく。例えば、XML文書の中の<title>という要素の内容(データ)を取り出して、それを表示するアプリケーションを作りたい場合どうすればいいのだろうか。XML文書のファイルを読み込み、文字列を頭から取り出していき、<title>という文字列を見つけ出せばいいのかもしれないが、そのためのコードが大変複雑になってしまうのは容易に想像できる。そこで登場するのがXML Parserである。
XML Parserは、XML文書を読み込み、そのXML文書の構造を解析(パース)してくれる。例えば、開始タグ(<title>)と終了タグ(</title>)がちゃんと対応しているか、といったことや、要素がちゃんと入れ子になっているかなど、XML文書が整形式かどうかをチェックする。また、DTDによる妥当性のチェックもする。もし、XML文書が整形式でなかったり、妥当でない場合は、Parserがエラーを通知してくれるわけだ。
XML文書の構造に問題がなければ、XML ParserはXML文書をそのまま読み込む。アプリケーション開発者はXML Parserが提供する標準的なAPIを利用して、読み込まれたXML文書に簡単にアクセスできる。このXML文書へアクセスするための代表的な2つのAPIは、DOM(Document Object Model)とSAX(Simple API for XML)である。今回は、このXML Parserの使い方について解説しよう。
| DOM(Document Object Model)を使う |
XML文書は、開始タグに対応した終了タグが必ず存在し、これらがネストされた構造をしている。この構造から、XML文書は、タグとその間のデータをそれぞれノードとしたツリーと見なすことができる。例えば、以下のようなXML文書があったとする。
Book.xml<?xml version="1.0" encoding="Shift_JIS"
?> |
このXML文書の各タグとデータを1つのノードとしてツリーにしたものが、次の図になる。
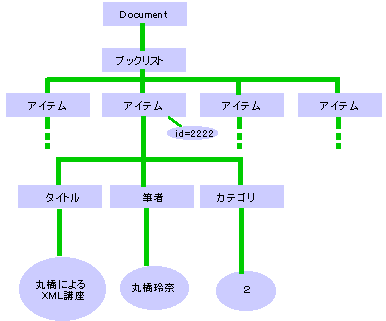 |
| XML文書をツリー構造で表現したもの(一部省略) |
アプリケーション開発者は、このツリーの1つ1つのノードに直接アクセスし、さまざまな処理を行うコードを書くことになる。この際、このツリーにアクセスするための標準的なインターフェースの1つがDOM(Document Object Model)である(そのため、ツリーを「DOMツリー」と呼ぶこともある)。このDOM APIを利用することによって、XML文書内のデータの検索や、要素や属性の追加および削除などができる。
さっそくDOMを利用したサンプルを見ていくのだが、そこで使用するのがOracle XML Parserである。Oracle XML Parserは、Oracle XML Developer's Kit(XDK)を構成するコンポーネントの1つである。現在、DOM(Level 1)がW3Cの勧告となっているが、Oracle XML ParserはこのDOM(Level 1)に準拠している。さらに、Oracle XML Parserでは、XML文書の一部分を出力したり、名前空間の情報を取り出したり、XPathで指定したノードを取り出したりといった拡張もされている。ここでは、Oracle XML Parser for Javaを利用したJavaのコードでDOMの例を2つほど見てみる。
下記のコードでは、先ほどの「Book.xml」を読み込み、「id」という属性が「22222」である「アイテム」という要素(つまり、「<アイテム id="22222">…</アイテム>」)を探し、その子供の要素である「タイトル」、「筆者」、「カテゴリ」という要素の内容を出力している。
最初に標準的なAPIを用いたサンプルを示し、次にOracle XML Parser独自のAPIを用いたサンプルを示す。
標準のDOM APIを利用したサンプル(抜粋)// パーサーをインスタンス化 |
リストの全部を記すと長くなるため、上記では主要な部分だけ抜粋してある。リスト全体はBookByRegDOM.javaを参照してほしい。では、処理の内容を見ていこう。
- DOM APIを利用してそれぞれのノードの操作を行う前にまずしなくてはいけないのが、DOMParserのインスタンス化とXML文書のパース(解析)である。
- その後、DOMのDocumentインタフェースを実装したDocumentを取り出す。このDocumentは、ツリーのルートとなっている。ツリーのルートは、「ブックリスト」要素のように思えるが、そうではなく、文書全体を表すDocumentがルートにあるのである。このDocumentの最初の要素が「ブックリスト」要素になるわけである。
- getElementsByTagName()メソッドによって、すべての「アイテム」要素をNodeListオブジェクトとして取り出し、変数nlにセットする。
- NodeListから一つずつNodeを取り出し、Elementにキャストして変数eにセットする。このeには、それぞれの「アイテム」要素がセットされる。そして、「id」属性が指定した値、つまり“22222”であったら、「id」、「タイトル」、「筆者」、「カテゴリ」の内容を取り出し、表示する。
- 「アイテム」要素eから「タイトル」要素の内容を取り出すのは少々複雑である。それは、まず「アイテム」要素の子ノードの中から「タイトル」を取得し、さらに「タイトル」要素の子ノードとしてテキストノードを取得し、その値を取り出す必要があるからである。つまり、「タイトル」要素の内容は、「アイテム」要素から見ると孫に当たるノードに格納されている。「タイトル」、「筆者」、「カテゴリ」の各要素ごとに同じ処理が必要なので、getElementContent()メソッドを作成し、その中でこの処理を行っている。ここでは、読み込んだXML文書の構造をあらかじめ把握していると仮定して、例えば「タイトル」要素には子供の要素はなく、文字データしか含まれていないのを知っていると仮定して、
Node n = nl.item(0);
のようにしてしまっている。
このコードを実行すると以下のような結果が出力される。
F:\Oracle\JDeveloper 3.1.1\java1.2\jre\bin>java BookByDOM |
DOMを使うことで、XML文書に対して任意の操作ができることを分かってもらえただろうか。
| オラクルの拡張DOMを使ってみる |
せっかくオラクルのXML Parserを利用しているのだから、次にオラクル独自の拡張DOM APIを利用したサンプルコードを紹介しよう。標準のDOM APIよりも簡潔に表現できる。
オラクルの拡張DOM APIを利用したサンプル(抜粋)// パーサーをインスタンス化 |
ここでも上記のリストでは主要な部分だけを抜粋した。全体のリストは、BookByDOM.javaを参照してほしい。処理内容は次のようになる。
- 途中までは同じだが、Documentを取り出す代わりにDOMのDocumentインターフェイスを実装したXMLDocumentを取り出している。
- 次に、selectNodes()というメソッドで、
「//アイテム[@id = 22222]」
というXPathで指定されたノードをNodeListオブジェクトとして取り出し、変数nlにセットする。このXPathは、「アイテムという要素で属性「id」の値が「22222」であるもの」を指定している。例えば、これをXML文書のルートからの絶対パスを指定して、さらに「アイテム」要素の子供の「カテゴリ」要素で値が「1」より大きいものノードをすべて取り出したい場合は、
「/ブックリスト/アイテム[カテゴリ > 1]」
と変えればよい。
- このNodeListには、複数のノードが含まれる可能性があるので、1つずつノードを取り出し変数eにセットする。この際、XMLElementにキャストしている。このXMLElementはDOMのElementインターフェースを実装したものだが、この後で拡張メソッドを使用するためにキャストが必要なのである。
- その後、各XMLElementごとにまずgetAttribute()メソッドで「id」属性の値を取り出し、指定したvalueOf()メソッドで「タイトル」、「筆者」、「カテゴリ」の要素の内容(データ)を取り出し、出力している。
| ツリーがメモリに展開されるのがDOM |
Oracleの拡張APIを利用すると、処理はずいぶん楽になるが、標準APIやオラクルの拡張APIのどちらを使うにせよ、DOMを利用してXML Parserの提供するメソッドで容易にXML文書を取り込み、操作することができる。
DOMを利用した場合、一度パース(解析)し、XML文書の構造全体を表すツリーがメモリ上に生成される。その上で、そのツリーに対して各処理が行われていく。つまり、DOMによる処理では、XML文書のサイズに合わせてメモリ占有量も大きくなってしまい、当然それに伴って処理が遅くなってしまう可能性がある。
では、サイズの大きなXML文書を扱う場合はどうしたらいいだろうか。それは、XML文書の構造を表すツリーを生成してそれに対して処理をしていくのではなく、1つひとつのノードを読んでいくタイミングで処理する、つまり要素の開始や終了といったイベントが発生するたびに処理をしていくことである。そのようなイベント駆動型のAPIの一つにSAX(Simple API for XML)がある。次回はこのSAXについて説明する。
■関連記事
- 連載「XSQLプログラミング入門」(XML eXpert eXchangeフォーラム)
| Index | |
| 連載 XMLツールでプログラミング | |
| (1)Javaで利用するXML開発ツール Oracle XML Developer's Kit(XDK)の紹介 |
|
| (2)DOMによるXML文書の操作 DOM APIを使ったプログラムの基礎 |
|
| (3)
SAXによるXML文書の操作 SAX APIを使ったXML文書操作の基礎と実践 |
|
| (4)
Javaで文書作成クラスを生成する DTDを元に、XML文書を作成するJavaクラスを作る |
|
| (5)
OracleからXML文書を出力する データベースへの問い合わせ結果をXML文書にする |
|
- QAフレームワーク:仕様ガイドラインが勧告に昇格 (2005/10/21)
データベースの急速なXML対応に後押しされてか、9月に入って「XQuery」や「XPath」に関係したドラフトが一気に11本も更新された - XML勧告を記述するXMLspecとは何か (2005/10/12)
「XML 1.0勧告」はXMLspec DTDで記述され、XSLTによって生成されている。これはXMLが本当に役立っている具体的な証である - 文字符号化方式にまつわるジレンマ (2005/9/13)
文字符号化方式(UTF-8、シフトJISなど)を自動検出するには、ニワトリと卵の関係にあるジレンマを解消する仕組みが必要となる - XMLキー管理仕様(XKMS 2.0)が勧告に昇格 (2005/8/16)
セキュリティ関連のXML仕様に進展あり。また、日本発の新しいXMLソフトウェアアーキテクチャ「xfy technology」の詳細も紹介する
|
|





