BFF(Backends For Frontends)実践における3つのアンチパターンと、その回避策:マイクロサービス/API時代のフロントエンド開発(終)
マイクロサービス/API時代のフロントエンド開発に求められる技術の一つ、Backends For Frontends(BFF)について解説する連載。最終回は筆者の経験に基づいて、3つのBFFアンチパターンと、その回避策を紹介します。
実案件にBFFを複数回導入した筆者の経験に基づいて原因と回避策を解説
マイクロサービス/API時代のフロントエンド開発に求められる技術の一つ、Backends For Frontends(BFF)について解説する本連載「マイクロサービス/API時代のフロントエンド開発」。前回はBFFに関する5つのユースケースを紹介しました。
BFFはアーキテクチャのパターンの一種ですが、どんなときでも当てはまるものではありません。勘違いして導入してしまうと後悔の元になる可能性があります。筆者は実案件にBFFを複数回導入していますが、全ての案件でうまくいったわけではありません。むしろ新しいものを導入したことによって起きてしまった問題や、責任範囲が変わることで起きてしまったミスなどが発生しています。
そこで今回は、筆者の経験に基づいて下記3つのBFFアンチパターンを紹介します。アンチパターン名は筆者が考えたものです。便宜上分かりやすくするために名前を付けてます。
- コミュニケーションを不足させてしまう「スパースコミュニケーション」
- BFFに処理を寄せ過ぎてしまう「ファットフロント」
- 最後に一気に結合させてからリリースさせる「ビッグバンジョイント」
往々にしてアンチパターンの原因は、組織上の問題や、コミュニケーションの課題にありますが、筆者がそれらの問題を回避した方法についても解説します。
【アンチパターンその1】コミュニケーションを不足させてしまう「スパースコミュニケーション」
アーキテクチャを疎結合(スパース)にした結果、コミュニケーションも「疎(sparse)」になってしまう現象のことを「スパースコミュニケーション」と名付けています。この現象の原因としては、「報告、連絡、相談の軽視」「組織が異なることによるコミュニケーションコスト」などがあります。
BFFでアーキテクチャを疎結合にしたとしても、フロントエンドエンジニアとバックエンドエンジニアとの間でコミュニケーションをおろそかにしていいということにはなりません。多くの場合、コミュニケーションを取らずに作っても良いシステムにはならないのです。
APIの認識齟齬を減らしつつ、フロントエンドとバックエンドを同時に開発する
スパースコミュニケーションを直接回避する手段は「コミュニケーションを取る」以外にはありません。その一方で、技術によってAPIの認識齟齬(そご)を減らしていくことは可能です。
一つはフロントエンドもバックエンドも同じリポジトリにした上で、「Swagger」「Agreed」(後述)など、APIの仕様を一緒にソースコード内で管理してしまうことです。APIの仕様を変更するときは変更するためのプルリクエストも一緒に投げられるため、変更したことが開発者全体に連絡されるようになります。
Consumer Driven Contract
別な回避策として、APIの仕様がバックエンド内で全て固まり切ってからフロントエンドを実装することがあります。認識齟齬は生まれにくくなりますが、その一方で、フロントエンドの実装着手が遅くなります。
そのためリクルートテクノロジーズでは、フロントエンドとバックエンドの双方で同時に開発を進め、かつ、APIの認識齟齬を減らすために、「Consumer Driven Contract」という方法に取り組んでいます。
Consumer Driven Contractとは、APIの仕様をフロントエンドが主導して決めてしまうための方法です。「Consumer-Driven Contracts: A Service Evolution Pattern」に詳しい内容が記載されています。

従来手法では、上図の「Provider」であるバックエンド側がAPIの仕様を定義し、それに伴って「Consumer」であるフロントエンドがクライアントを作っていましたが、この関係を逆転し、ConsumerからAPIを定義します。具体的には、リクルートテクノロジーズが開発した「Agreed」を活用し、フロントエンドが主導してAPIの仕様を以下の要領で決めていきます。
最初にフロントエンドが投げたいHTTP Requestと受け取りたいHTTP Responseの定義を記述します、これを「Contract(契約)」と呼びます。その後、このContractを元にAPIのモックサーバを作ります。

ある程度開発が進むと、このContractが今度はバックエンドをテストするためのAPIクライアントになります。

こうすることで、ConsumerとProviderの両者がAPIの認識齟齬を減らす役割を担います。バックエンドが実装を変えたり、フロントエンドがAPIの要求仕様を変えたりした場合はAgreedを中心として変更が伝わります。テストが通らなくなったり、フロントエンドのコードが動作しなくなったりすることでお互いの変更にセンシティブになり、認識齟齬を減らすことが可能です。
もちろん、穴は幾つも存在するので、この方法を導入していたとしても、コミュニケーションは必須です。
詳細は「リクルートテクノロジーズのフロントエンド開発 2016」を参照してください。
【アンチパターンその2】BFFに処理を寄せ過ぎてしまう「ファットフロント」
これまでの連載で説明した通り、BFFサーバを立てることで、さまざまな処理をBFFに移譲させることができ、バックエンドでセッションなどを管理する必要はなくなります。しかしBFFは、あくまでもフロントエンドでWebページやユーザーインタフェース(UI)を作るためのサーバです。バックエンドから処理を移譲させ過ぎるとBFFの負荷が高まり、結果としてサービス全体の性能が悪化する可能性があります。
このような状況になってしまうことを「フロントエンドが太る」という意味で「ファットフロント」と呼んでいます。
実際に起きた問題で言えば、いわゆる「N+1問題」がBFFで発生してしまう現象が発生しました。検索などの一覧処理を行うAPIをシンプルにするあまり、一度の処理で表示に必要な情報を取得させず、「一覧処理(idのみをリストする処理)」と「詳細情報の取得処理(idから属性を取得する処理)」を分けてしまい、その結果複数回のリクエストを発行しないといけなくなる状況になってしまいました。
図にすると、下記のような状況です。ユーザー一覧画面を作成する際、「/users」に対して検索を実行し、その際にidのみのリストがJSONで返却されます。

次に、「/users/[id]」でid数分のリクエストを発行し、詳細を都度取得したという現象が起こりました。

これでは、APIを効率的に並列で実行できたとしても、BFFとバックエンド間で情報を取得するのに時間がかかり過ぎてしまいます。理想としては、最初から一覧情報の中に詳細情報が含まれている方が1回のAPIリクエストで必要な情報を取得でき、BFFに負荷がかかりません。
BFFとバックエンドの責任を明確にする
ファットフロントはBFFやバックエンドの責任が明確ではなく、理解が不足しているときに発生します。
繰り返しますが、BFFはUIのためのサーバであり、あくまで“表示”に関わる処理が主な役割です。それに対してバックエンドは「ドメインロジック」や「ビジネスロジック」と呼ばれる、UIに依存しない“コア”の機能を提供するのが主な仕事です。ファットフロントを防ぐには、この共通認識をまず持つことが重要です。
BFFの処理が増えていると感じたら、一度立ち止まってバックエンドのAPIを変更できないか検討した方がいいでしょう。
【アンチパターンその3】最後に一気に結合させる「ビッグバンジョイント」
BFFに限らず、APIとフロントエンドを並行開発する際にはお互いの認識齟齬を極力減らしていくことが重要です。そのため、先に述べたConsumer Driven Contractや、APIの仕様を同一のリポジトリで開発するといった方法を紹介しました。しかし、いくら減らしたつもりであっても、必ずどこかに齟齬やバグといった不確定な要素は存在します。
これらが発生するのが悪いわけではありません。発生するのを考慮せずにいきなりBFFとバックエンドをつないだり、しかもリリース間近に結合を行ったりするのが問題なのです。
「突然結合してもいきなりは動かない」と考えて余裕を持っておくことが重要です。
徐々にBFFとバックエンドを結合させる
筆者のグループでは、いきなり結合させるよりも定期的なタイミングで少しずつバックエンドと結合させるようにしています。未実装のAPIはMock(モック)を利用し、徐々に実装済みのバックエンドと結合する比率を上げていきます。

さらに言うと、この徐々に本物のバックエンドにつなげていく過程で齟齬やバグを早期に発見するようにしています。ただし、フロントエンドが未実装なところは画面上では確認できません。フロントエンドで未実装なところは確認が遅れてしまいますが、それも考慮し、齟齬やバグが発生した際の手戻りが多そうなものから先に手を付けるなどの工夫を施しています。
徐々に結合させるパターンであってもBFFとバックエンドの結合には時間がかかります。さらに、時間的なバッファーを設けておくことも検討するといいでしょう。
組織的な課題とアーキテクチャ設計には密な関係がある
このように、BFFの3つのアンチパターンとその回避方法を紹介しましたが、いかがでしたでしょうか。
アンチパターンの多くは、組織的な課題に根差すものです。そもそもBFFやマイクロサービスは組織の形に合わせてアーキテクチャを進化させた結果です。組織的な課題とアーキテクチャ設計には密な関係があります。
アーキテクチャそのものが組織の課題を直接解決するわけではありません。組織の課題を解決しやすくはするものの、解決するには組織内にいるメンバーが『コミュニケーションを取る』『BFFとバックエンドについて理解を深める』『スケジュールや進め方に工夫を施す』などを行って解決する必要があります。
「BFFを導入すれば組織課題が解決され、開発効率が向上する」と誤解して、何も考えずに導入したところで、課題は解決できません。
フロントエンド開発の未来
最後に、これまでの連載で話したことをまとめて、BFFにおけるフロントエンド開発の未来について予測できる範囲でお話しします。
BFFは、マイクロサービスというアーキテクチャによってフロントエンドに寄せられてしまった機能の一部をサーバとして切り出したパターンです。実際にやってみると、フロントエンドのエンジニアはブラウザの動きのことだけを追っていればいいというわけではなく、サーバサイドのCPUやメモリといったリソースの監視や、チューニング、HTTPプロトコルといった深い知識が求められます。
フロントエンドエンジニア/バックエンドエンジニアという区分けはありますが、共通で持つ必要のある知識は重なっていきます。「BFFはサーバだから」といってフロントエンドエンジニアはサーバの監視やチューニングに無関心ではいられません。一方で、バックエンドエンジニアは「BFFが自分の開発範囲ではなく、フロントエンドのコードが見慣れないから」といって敬遠してはいけません。サービスの品質を向上させるには、フロントエンドもバックエンドも変わりなく、両方が向き合う必要があります。
BFFが今後フロントエンドとバックエンドをつなぐ架け橋になっていくのか、それともBFFという概念自体が廃れるのかは分かりません。「技術は揺り戻しを繰り返しながら良くなっていく」という流れからすれば、一度マイクロサービスによって疎結合へと傾いた流れはまた密結合に戻ることが考えられます。この流れから言えば今後は、「フロントエンドとバックエンドの分離が広がる」というよりは「近づいていく」のではないかと考えられます。そのためには、フロントエンド/バックエンドの両方とも、お互いの知識を嫌がらずに受け入れていく必要があります。
BFFというアーキテクチャパターンは、フロントエンド/バックエンドをつなぐ架け橋になる技術であり、この流れを支えるアーキテクチャだと思っています。
関連記事
 5分で絶対に分かるAPI設計の考え方とポイント
5分で絶対に分かるAPI設計の考え方とポイント
API設計を学ぶべき背景と前提知識、外部APIと内部API、エンドポイント、レスポンスデータの設計やHTTPリクエストを送る際のポイントについて解説する。おまけでAPIドキュメント作成ツール4選も。 「サービスメッシュ」「Istio」って何? どう使える? どう役立つ?
「サービスメッシュ」「Istio」って何? どう使える? どう役立つ?
マイクロサービスに関わる人々の間で、「サービスメッシュ」「Istio」への注目が高まっている。これについて、Javaコミュニティーで広く知られる日本マイクロソフトのテクニカルエバンジェリスト、寺田佳央氏がデモを交え、分かりやすく説明した。寺田氏の説明を要約してお届けする。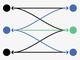 サービスメッシュを実現するオープンソースプラットフォーム「Istio」の正式版がリリース
サービスメッシュを実現するオープンソースプラットフォーム「Istio」の正式版がリリース
マイクロサービスの統合や、マイクロサービス間のトラフィックフロー管理などが可能なオープンソースプラットフォーム「Istio」がバージョン1.0に到達した。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。