リソース制御でサービスレベルを確保せよ:実践! Xenで実現するサーバ統合(5)(3/3 ページ)
ネットワークリソースの制御
■帯域幅閾値
ゲストOSが送信、受信に利用できるネットワーク帯域幅の上限値です。このネットワークの帯域幅設定はかなり複雑で、単に上限を設定するだけでなく、余剰分の帯域を共有させるように設定したり、キューイングのアルゴリズムを変更できたりと、柔軟に設定できます。このため、その内容すべてはここではカバーし切れません。
そこで今回は、単純に、ゲストOSごとに帯域の上限値を設定する方法を紹介します。
Linux OSが提供する帯域幅制限の機能はインターフェイスごとに適用され、そのインターフェイスからのアウトバウンドトラフィックに対して働きます。従って、そのままではインバウンドトラフィックについては制御できません。しかし、Xenを用いた仮想化環境では、その内部ネットワーク構成をうまく利用することで、インバウンドトラフィックについても制限を設けることができます。
これを理解するためには、第1回で解説したXenの内部ネットワーク構造を思い出す必要があります。図5を参照してください。
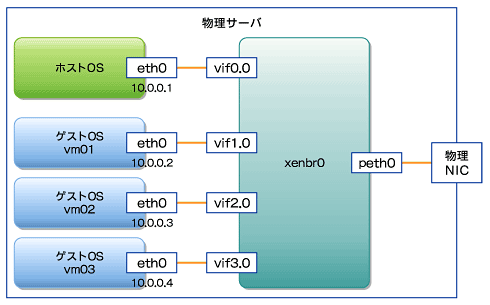 図5 Xenの内部ネットワーク構造
図5 Xenの内部ネットワーク構造ゲストOSが物理NICとつながるまでには、図5のように、「xenbr」と呼ばれる仮想ブリッジが介在しています。
ここでは、ゲストOS「vm01」について考えてみましょう。vm01からのアウトバンドトラフィックは、eth0のポイント、またはpeth0のポイントで制御できます。一般的にはゲストOS単位よりもホストOS側で設定する方が、より一元的に管理でき、管理性が高いと思われます。ここでも、peth0で制御を行うものとします。
一方、インバウンドトラフィックはvif1.0で制御できます。なぜならば、vm01のインバウンドトラフィックは、vif1.0にとってはアウトバウンドトラフィックだからです。このように、xenbrを巧みに利用して、アウトバウンドとインバウンド、両方のトラフィックを制御するわけです。
| 仮想マシン名 | 割り当て帯域幅 |
|---|---|
| vm01 | 500kbit/s |
| vm02 | 500kbit/s |
| vm03 | 1Mbit/s |
それでは実際の設定方法を見てみましょう。ここでは、要件として各ゲストOSに右のように帯域幅を割り当てたいとします。
まず、アウトバウンドトラフィックから見ていきます。帯域幅制御はXenが備える機能ではないので、CPUやメモリのように、ゲストOSの設定ファイルやxmコマンドによって設定することはできません。代わりに、tc(traffic control)コマンドを用いて設定していきます。これらの作業はすべてホストOS上で行います。
1. キューイング規則をpeth0に適用すると宣言
# tc qdisc add dev peth0 root handle 1:0 htb |
2. 各ゲストOS用のキューを作成
# tc class add dev peth0 parent 1:0 classid 1:1 htb rate 500kbit |
3. 到着したトラフィックをどのキューに振り分けるかのルールを作成
# tc filter add dev peth0 protocol ip parent 1:0 prio 1 u32 match ip src 10.0.0.2 flowid 1:1 |
このコマンドのパラメータや各オプションがどのように関係しているのか、文字だけで把握するのはなかなか難しいので、図で解説したいと思います。上記のコマンドと照らし合わせて確認してみてください。
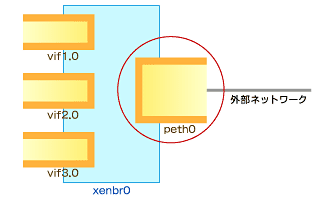 図6A キューイング規則をpeth0に適用すると宣言
図6A キューイング規則をpeth0に適用すると宣言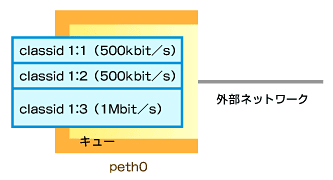 図6B 各ゲストOS用のキューを作成
図6B 各ゲストOS用のキューを作成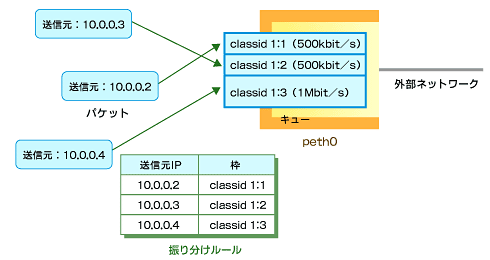 図6C 到着したトラフィックをどのキューに振り分けるかのルールを作成
図6C 到着したトラフィックをどのキューに振り分けるかのルールを作成■インバウンドトラフィックの制御
次に、インバウンドトラフィックを見ていきます。
1.キューイング規則を各vifに適用すると宣言
# tc class add dev vif1.0 parent 1:0 classid 1:1 htb rate 500kbit |
2.キューを作成
# tc class add dev vif1.0 parent 1:0 classid 1:1 htb rate 500kbit |
インバウンドトラフィックでは、キューイング規則をvifインターフェイスに適用します。vifインターフェイスは各ゲストOS専用のものとなっているため、アウトバウンドについて設定したときとは異なり、トラフィックをどのキューに振り分けるかというルールは必要ありません。
より正確にいえば、そもそもキューは各インターフェイスに対し、1つしか作成する必要がありません。よってインターフェイスに到着したトラフィックはその枠に自動的に振り分けられます。これも図で確認してみましょう。
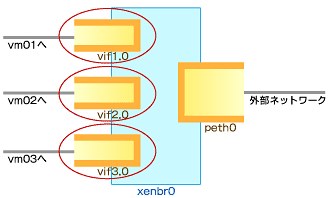 図7A キューイング規則を各vifに適用すると宣言
図7A キューイング規則を各vifに適用すると宣言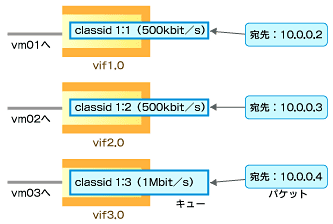 図7B キューを作成
図7B キューを作成ここで1つ注意しなければならない点があります。vifインターフェイスに割り当てられている番号は、各ゲストOSに静的に割り当てられるものではなく、起動するたびに変動します。
例えば、最初はvm01に「vif1.0」というインターフェイスが割り当てられていたとしても、ゲストOSを再起動するとvif1.0というインターフェイスは破棄され、新たにvif4.0というインターフェイスが作成されます(注)。
注: 新しく割り当てられる番号は、未使用の番号の中から最も若い番号が割り当てられます
従って、コマンドレベルでインターフェイスを指定して帯域幅制御の設定を行っていると、ゲストOSを再起動したタイミングで設定が外れてしまうことになります。これを回避するには、Xenのネットワークインターフェイス初期化スクリプトの中に、上記のtcコマンドを埋め込んでおく必要があります。該当のスクリプトは/etc/xen/scripts/vif-bridgeです。
具体的には、以下のように修正を加えることで、帯域幅制御の設定を永続化することができます。以下に、簡単なサンプルを掲載しておきますので参考にしてください。
... |
最後に、ゲストOS側で1つ設定を加える必要があります。
最近のネットワークカードにはTCP Offload Engineが備わっているものがあります。これはTSO(TCP Segment Offloading)というセグメンテーション処理をCPUではなくネットワークカードに委任することによってネットワークの性能を向上させたり、CPUをセグメンテーション処理から解放してCPU負荷を下げる機能を提供します。
ただし、今回のように帯域幅制御を行う場合、キューイングの実装(パケットスケジューラ)がこのTSOに対応していない可能性があります。キューイングの実装には今回ご紹介したHTB以外にもCBQやTBFなどさまざまな種類があります。残念ながら、今回取り上げたHTBについては、TSOに対応しているのかどうかを確認するには至りませんでした。
よって念のため、ゲストOSでこのTSOを無効にしておきます。具体的には、ゲストOS上で以下のようにコマンドを実行します。
# ethtool -K eth0 tso off |
eth0の部分は適宜、手元の環境で使用しているインターフェイス名に置き換えてください。
このように最後はリファレンス的な内容で、特にネットワークの帯域幅制御については少し濃い内容になってしまいましたが、本連載は今回で最終回となりました。この連載が、Xenによるサーバ仮想化を実践する際の参考となれば幸いです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。