見落としがちな整数関連の脆弱性(前編):もいちど知りたい、セキュアコーディングの基本(4)(2/2 ページ)
符号エラー(signedness error)
符号エラーは、符号付き整数を符号なし整数として解釈したり、あるいはその逆に、符号なし整数を符号付き整数として解釈したりする場合に発生する問題です。
そもそもコンピュータの内部では、符号付き整数も符号なし整数も、単なるビット列として表現されており、データ自体には「符号付き」とか「符号なし」という概念はありません。signed int型の変数もunsigned int型の変数も、同じビット幅で表現される単なるビット列にすぎません。
 図5 符号エラーの原因
図5 符号エラーの原因違いは、これらの整数データを解釈する際、「符号付き整数」として扱うか、それとも「符号なし整数」として解釈するか、にあります。
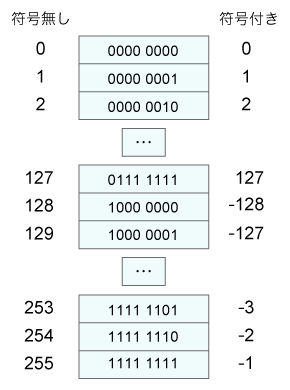 図6 解釈の違いによって異なる整数を示すことになる
図6 解釈の違いによって異なる整数を示すことになるそれでは実際に、符号エラーの実例を見てみましょう。
取り上げる脆弱性は2011年に見つかったlighttpdにおける符号エラーに関する脆弱性です(CVE-2011-4362)。lighttpdは、LinuxやWindowsで動作するオープンソースのWebサーバプログラムです。CVEには、脆弱性の概要が次のように書かれています。
Integer signedness error in the base64_decode function in the HTTP authentication functionality (http_auth.c) in lighttpd 1.4 before 1.4.30 and 1.5 before SVN revision 2806 allows remote attackers to cause a denial of service (segmentation fault) via crafted base64 input that triggers an out-of-bounds read with a negative index.
(訳)lighttpd バージョン1.4(1.4.30より前)とバージョン1.5(SVNのリビジョン2806より前)には、HTTP認証機能(http_auth.c)の中のbase64_decode関数に整数の符号エラーが存在する。攻撃者がネットワーク越しに、細工したbase64データをサーバに送信すると、負のインデックス値に基づく境界外メモリ読み込みが発生し、サーバはDoS状態に陥る(セグメンテーションフォルトが発生する)。
HTTPアクセス認証方式の1つであるBasic認証では、クライアントはサーバに対して、コロンで区切られたユーザーIDとパスワードの組をBase64エンコードし、エンコードされたBase64文字列をサーバに送信します。サーバは、受け取った文字列をBase64デコードし、ユーザーIDとパスワードを取り出します。
CVE-2011-4362の脆弱性は、Base64デコード処理を行うbase64_decode()関数に作り込まれてしまったものです。脆弱なコードは次のように書かれていました。
...
62 /* "A-Z a-z 0-9 + /" maps to 0-63 */
63 static const short base64_reverse_table[256] = {
64 /* 0 1 2 3 4 5 6 7 8 9 A B C D E F */
65 -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, /* 0x00 - 0x0F */
66 -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, /* 0x10 - 0x1F */
67 -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, /* 0x20 - 0x2F */
68 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, /* 0x30 - 0x3F */
...
81 };
...
84 static unsigned char * base64_decode(buffer *out, const char *in) {
85 unsigned char *result;
86 int ch, j = 0, k;
87 size_t i;
88
89 size_t in_len = strlen(in);
90
91 buffer_prepare_copy(out, in_len);
92
93 result = (unsigned char *)out->ptr;
94
95 ch = in[0];
96 /* run through the whole string, converting as we go */
97 for (i = 0; i < in_len; i++) {
98 ch = in[i];
...
104 ch = base64_reverse_table[ch];
...
142 }
問題は、
- 1文字ずつ取り出す(98行目)
- Base64変換テーブル(base64_reverse_table)を基に、Base64文字に対応するデータを取得する(104行目)
の2つの処理にありました。
1.の処理では、単なるchar型の文字データin[i]を、int型に変換しています。多くの処理系では、単なるcharは符号付き型であると解釈されます。したがって、in[i]の値が0x80以上である場合、つまり最上位ビットが立った値の場合、負のデータとして解釈され(符号拡張が行われ)、int型であるchは負の値を保持することになります。
2.の処理では、chの値をBase64変換テーブルを参照する際のインデックス値として用いています。したがって、chが負の値である場合、テーブル外のデータを参照してしまいます。
さて、1.の処理でin[i]の値が0x80になるケースはどのような場合でしょうか。Base64エンコーディングでは、データをUS-ASCII文字の64文字(A-Z、a-z、0-9、+、/とパディングのための=)に変換して表現します。ASCII文字は0x00から0x7Eの範囲で表現されるので、in[i]に0x80以上の値が入るということは、ASCII以外の文字が入力されるケースということになります。
Base64エンコーディングについて規定するRFC 4648 "The Base16, Base32, and Base64 DataEncodings"の3.3. Interpretation of Non-Alphabet Characters in Encoded Dataを見ると、そのようなケースについて次のように書かれています。
- エンコードされたデータには、データ破壊の結果や設計上の理由から、非アルファベット文字が含まれる場合がある
- 非アルファベット文字は、バッファオーバーフロー攻撃につながるような実装エラーを攻撃するために、攻撃者により送られてくることもある
- したがって、Base64でエンコードされたデータを解釈するとき、アルファベット以外の文字が含まれているデータは拒否しなくてはならない
Base64文字に非ASCII文字が含まれることを想定するならば、in[i]の値を符号なし整数として解釈すべきでした。このコードの修正は次のように行われています。
diff --git a/src/http_auth.c b/src/http_auth.c
index f2f86dd..33adf71 100644
--- a/src/http_auth.c
+++ b/src/http_auth.c
@@ -99,7 +99,7 @@ static unsigned char * base64_decode(buffer *out, const char *in) {
ch = in[0];
/* run through the whole string, converting as we go */
for (i = 0; i < in_len; i++) {
- ch = in[i];
+ ch = (unsigned char) in[i];
if (ch == '\0') break;
修正パッチでは、Base64エンコードされた文字を取り出してint型変数chに代入する際、unsigned charに明示的にキャストしています。こうすることで、char型からint型への代入変換時に符号拡張ではなくゼロ拡張が行われるようになり、変換テーブルの参照時に境界外読み込みが行われないようになっています。
ちなみに、この脆弱性に関しては、PoCコード(Proof-of-Conceptコード。エクスプロイトコードとも呼ばれる。脆弱性の存在を実証するためのコード)が、Exploit Databaseで公開されています。
Exploit Databaseは、脆弱性研究者やペネトレーションテストを行うセキュリティエンジニアのために、現在約2万件のPoCコードを無料で公開しています。脆弱性によっては、このようなPoCコードや、PoCコードをさらに洗練させたツール(やそのプラグインモジュール)が公開されることがあり、脆弱性が悪用されるリスクが高まることもあります。
プログラムのユーザーをセキュリティ上の被害から守るためには、脆弱性が発見された際に速やかに修正版を提供することが重要なのはもちろん、セキュアコーディングを実践し、脆弱性を作り込まないことでリスクを低減することも重要です。
今回は、整数に関する4つの脆弱性のうち、1.整数オーバーフロー(ラップアラウンド)と2. 符号エラーを見ました。次回は、3.切捨て、4.その他の問題を見ていきたいと思います。
参考文献
▼CVE-2012-4433: Multiple integer overflows in operations/external/ppm-load.c in GEGL(画像ファイルのライブラリに見つかった整数オーバーフローの別の典型例)
http://www.cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2012-4433
▼MISRA-C:2004には整数関連の規約がいくつか存在します。
10.1: The value of an expression of integer type shall not be implicitly converted to a different underlying type if: a) it is not a conversion to a wider integer type of the same signedness, or b) the expression is complex, or c) the expression is not constant and is a function argument, or d) the expression is not constant and is a return expression.
10.3: The value of a complex expression of integer type may only be cast to a type that is narrower and of the same signedness as the underlying type of the expression.
12.11 Evaluation of constant unsigned integer expressions should not lead to wrap-around.
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。