第3次人工知能(AI)ブームにおける機械学習、そろそろ入門しよう!:まだ知らないエンジニアのための人工知能/機械学習概説
人工知能がブームになった歴史から、機械学習との関係、解決できる現実問題、話題のディープラーニングまで、AI&機械学習をまだ知らない人の疑問に答える基礎解説。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
ご注意:本記事は、@IT/Deep Insider編集部(デジタルアドバンテージ社)が「www.buildinsider.net」というサイトから、内容を改変することなく、そのまま「@IT」へと転載したものです。このため用字用語の統一ルールなどは@ITのそれとは一致しません。あらかじめご了承ください。
今、テレビニュースや新聞などを中心に、話題となっている人工知能。つい最近でも(2016年3月)、グーグルが開発した人工知能「AlphaGo(アルファ碁)」が世界最強の囲碁プレーヤーを破ったという報道がなされ、人工知能の進化を一般の人々に印象づけました。
このような状況の中、人工知能や、その基盤となっている機械学習に感心を寄せるエンジニアが増えています。本稿では、主にそういったエンジニア層に向けて、人工知能と機械学習の概要、機械学習が現実問題を解決するためのコツ、機械学習の手法として特に注目を集めている“ディープラーニング(Deep Learning)”の概要を、できるだけ簡潔に説明します。
実は、今のように一般社会で人工知能がブームになったのは初めてではなく、これまでの歴史の中で何度か同じようなことが起きています。人工知能ブームにおける機械学習の説明に入る前に、まずは各ブームの内容と、今回のブームとの違いを紹介します。
1. 第3次人工知能ブーム
1950年代に第1次人工知能ブームが起こりました。このころ、アラン・チューリングとクロード・シャノンというコンピューターの研究者が、「コンピューターにもチェスを指すことが可能で、原理的には世界チャンピオンにも勝てる」と言っていました。また、1956年に若手の研究者が集結したダートマス会議において、ジョン・マッカーシーという研究者によって人工知能(Artificial Intelligence: AI)という名前が産声を上げました。当時はチェスを指すコンピューター、数学の定理証明をするコンピューターが人工知能でした。
人工知能は1980年代に2回目のブームを迎えました。これが第2次人工知能ブームです。第2次人工知能ブームの2人の立役者は、「エキスパートシステム」と「第五世代コンピュータープロジェクト」でした。スタンフォード大の感染症診断治療支援エキスパートシステム(MYCIN)が現れ、このMYCINの診断の方が新米の医者よりも診断成績が良かったのです。この結果を背景に、日本においては、大手企業を中心に人工知能関連部署を新設しました。また、通産省が550億円をかけて行ったプロジェクト「第五世代コンピューター」は、多くの日本企業を巻き込み、世界規模の第2次人工知能ブームを築き上げました。
第2次人工知能ブーム中に「ニューラルネットワーク」が注目されました。ニューラルネットワークは、「人間の脳神経回路をまねすることによってデータを人間と同じように分類しよう」というアイデアに基づくアルゴリズムです。
人間の脳はニューロン(神経細胞)のネットワークで構成されていて、あるニューロンは他のニューロンとつながったシナプスから電気刺激をニューロン同士の結合の強さに応じて受け取り、その電気が一定以上たまると発火して、次のニューロンに電気刺激を伝えます。これをアルゴリズミックに表現すると、あるニューロンが他のニューロンから0か1の値を受け取り、その値に何らかの重みをかけて足し合わせるという計算をしていると表現できます。ここでいう重みというのは、ニューロン同士の結合の強さを表していると考えられます。受け取った値の合計がある一定の値(閾値)を超えると1になり、超えなければ0になります。そして、1の値になったニューロンは再び次のニューロンに値を受け渡していくのです。この一連の流れの中で肝となるのは重み付けで、人間のニューロンが学習によってシナプスの結合の強さを変化させるように、学習する過程で重み付けを変化させ、最適な値を出力するように調整することで、入力に対する出力の正解精度を高めていきます。
しかし当時のコンピューターの能力では、ニューラルネットワークで脳の神経回路の階層構造をまねようとしても、「入力」「中間」「出力」の3層程度しかシミュレーションできませんでした(図1参照)。それでもある程度複雑な関係を学習できることは知られていたので、さまざまな産業分野に適用されました。しかし、ニューラルネットワークには十分な可能性があることは分かりましたが、3層程度のシミュレーションしかできなかったため、より人間に近い、人間を超える性能を発揮するという視点からは限界にぶちあたってしまいました。
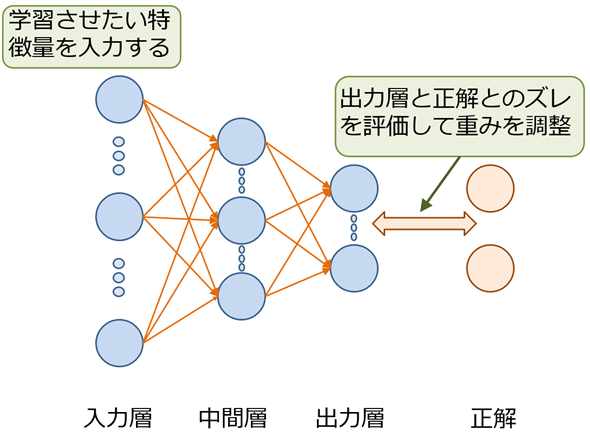 図1 ニューラルネットワークの概念図
図1 ニューラルネットワークの概念図 ところが、2000年代になると、コンピューターの性能向上と重みを決める学習アルゴリズムの工夫によって、ジェフリー・ヒントンという研究者が、ニューラルネットワークの階層を4層、5層と増やし、精度の高い機械学習の実現に成功しました。このニューラルネットワークの階層を4層、5層と増やしたネットワーク(図2参照)の学習を「ディープ・ラーニング(深層学習)」と呼びます。この「深層学習」の研究が、第3次人工知能ブームを引き起こしました。つまり、第3次人工知能ブームはニューラルネットワークの再発見なのです。
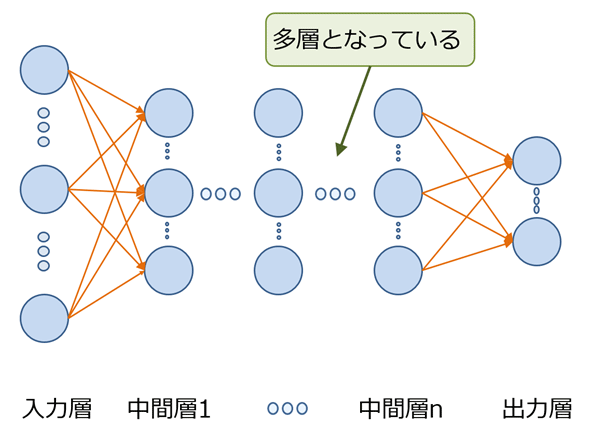 図2 深層学習のためのニューラルネットワーク
図2 深層学習のためのニューラルネットワーク 2. 人工知能と機械学習
さて、前節では第1次〜第3次の人工知能ブームについて述べてみましたが、それぞれのブームにおいて、人工知能と機械学習とはいったいどんな関係にあったのでしょうか。本節ではこれについてまとめます。なお、ここでは「機械学習とは、機械(コンピューター)に学習する能力を持たせる技術である」と定義しておきましょう。
1950年代に迎えた第1次人工知能ブームで、機械学習は注目されたのでしょうか。第1次人工知能ブームのころは、機械学習の重要性が指摘されたことはなかったでしょう。つまり、当時のチェスを指すコンピューター、数学の定理証明をするコンピューターには、機械学習は必要ではなかったのです。当時は、人間の経験した知識をコンピューターに搭載し、その知識を使ってどのように推論すればよいのかということだけに注目が集まっていました。
第2次人工知能ブームになると、「エキスパートシステム」の構築法もおおむね整理され、人間の経験知識をある形式で記述さえすれば、簡単な「エキスパートシステム」が構築できる状況になっていきました。そこで浮き彫りになってきた問題が、「人間の経験知識をコンピューターによっていかに簡単に獲得するか」という知識獲得の問題です。コンピューターによる知識獲得が機械学習の始まりだったのかもしれません。また、この第2次人工知能ブームでは、上述の通り、ニューラルネットワークも注目を集めました。第2次人工知能ブームは、機械学習の萌(ほう)芽(が)期だったと考えられます。この萌芽期の代表的な機械学習としては、ニューラルネットワークとその学習法である誤差逆伝搬法が挙げられます。
その後、人工知能は次の第3次ブームを待つことになりますが、機械学習は人工知能ブームとは別に、1990年代に成長期、2000年代に発展期を迎えることになります。1990年代の成長期には、サポートベクトルマシンを中心としたカーネル法やBagging、ブースティングを中心としたアンサンブル学習が機械学習として注目されました。また、機械学習の性能を評価する理論として有名な汎化誤差理論が注目され始めたのもこの成長期です。2000年代の発展期になると、高速・高性能なコンピューターが安価に手に入るようになり、変分ベイズ/Gibbsアルゴリズムを中心としたベイズモデルや転移学習、半教師有り学習などのさまざまな学習タスクが提案されました。第3次人工知能ブームの立役者でもあるディープラーニングが最初に提案されたのもこの発展期です。
第3次人工知能ブームと機械学習との関係は図3のように表されると思います。2000年までは「機械学習」と呼ばれていた研究が、ビッグデータと呼ばれる大量のデータを扱うようになって「人工知能」と呼ばれるようになり、第3次人工知能ブームを引き起こしていていると見ることができます。
 図3 2000年代の機械学習と人工知能
図3 2000年代の機械学習と人工知能 3. 機械学習と現実問題
ジェイソン・ブラウンリー(Jason Brownlee)が自身のWebサイトで、「Practical Machine Learning Problems」と題して、機械学習の応用例を紹介しています。それらは、
(1)スパム検知
(2)クレジットカード詐欺検知
(3)数字認識
(4)会話理解
(5)顔検出
(6)商品推薦
(7)医療診断
(8)株式取引
(9)顧客分割
(10)形状検出
の10例です。これらの応用例は、応用領域と考えることも可能で、それぞれの現実へ適用も見つけることができます。例えば会話理解は、iPhoneに搭載されているSiriで利用されています。また、商品推薦は、多くの方が利用しているAmazonのショッピングモールからの商品の推薦に利用されています。
私も機械学習の応用研究のいくつかに携わってきました。その応用研究の中で、私は主に、機械学習の設備診断への適用による診断性能の向上を目指した研究を行ってきました。例えば、配電柱腕金の再利用判定をコンピューターにさせる「パターン識別手法を用いた錆画像による腕金再利用判定法の性能評価」*1や、膨大な正常運転時のデータに基づき水力発電所における異常予兆の発見を支援する「水力発電所における異常予兆発見支援ツールの開発」*2がその一例です。
*1 電気学会論文誌C(電子・情報・システム部門誌)Vol. 125 (2005) No. 7 P 1049-1054
*2 電気学会論文誌D(産業応用部門誌)Vol. 131 (2011) No. 4 P 448-457
以下では、上記の機械学習10の応用例と、私が手がけてきた機械学習の応用研究から見えてくる機械学習が現実問題を解決するコツについて、私見を簡単に記載させていただきます。
- コツ(1): 相当量のデータの蓄積があることです。または、相当量のデータの収集蓄積が容易であることです。これは、機械学習の学習がデータに基づいて行われるためです。特に、人間が継続的に見るには耐えられないくらいの量のデータを見なければならないような問題に機械学習は向いています。
- コツ(2): 人間が問題解決しているが、問題解決する知識を定型文のような形式で表現することが難しい問題であることです。例えば数字認識では、人間は簡単に行っていますが、「6」と「0」をどのように違うと認識するのかを説明してくださいという問いには答えられないような状況を考えてもらえればよいと思います。
- コツ(3): 人間と同等あるいは人間よりも性能の高い識別、予測、検出性能などを、機械学習によってコンピューターが示せることです。逆に、人間による識別・予測・検出性能などの結果の方が機械によるそれよりも精度が高い場合には、「機械学習もまだまだだな」と評価される傾向があるようです。
2010年までは、これら3つのコツを満たした現実問題への機械学習の適用が、機械学習による現実問題への適用の成功例になっていたと考えられます。
4. 第3次人工知能ブームの勝者は?
第3次人工知能ブームの立役者は、ディープラーニングであることを多くの方が知っています。ディープラーニングは、猫を認識するために大量の猫の画像データからその中間層に、猫の輪郭、猫の大きさなどの特徴を自動的に獲得できることで有名になりました。また最近では(冒頭でも示したように)、グーグル・ディープマインド社が開発したディープラーニングを用いた「アルファ碁」が最強の李九段に4勝1敗で勝ち越したことで、ディープラーニングはさらに有名になりました。しかし、猫を認識するために、特徴量として猫の輪郭や猫の画像における大きさなどをニューラルネットワークがその中間層に獲得できるということは、1980年代に福島邦彦先生がネオコグニトロンで示していました。
では、なぜ今、第3次人工知能ブームは起こっているのでしょうか? それは1980年代に比べ、
- (1)技術発展によって、膨大な量のデータ(ビッグデータ)を収集蓄積できるネットワーク環境が整ったこと
- (2)百台のコンピューターを並列化するくらいで、ビッグデータを用いて中間層を多く持つニューラルネットワークの学習ができるくらいにコンピューターのスペックが上がってきたこと
の効果が大きいと考えられます。この2つの効果により、2000年代初めに現れ、あまり優秀な成績を出せなかったディープラーニングが2010年代には脚光を浴びる存在になれたのです。
この第3次人工知能ブームの中、全ての産業がディープラーニングの研究開発に今すぐ邁(まい)進(しん)する必要があるのでしょうか? 前掲の図3を見ると分かるように、第3次人工知能ブームにおいては、ディープラーニングをはじめとする機械学習には、ビッグデータが必要不可欠です。現在、ディープラーニングや人工知能研究に多額の投資を行っているGoogle、Baidu、Facebookはすでにビッグデータを収集・蓄積できる環境を有している企業です。第3次人工知能ブームの中、これらの企業が有するビッグデータとは異なるビッグデータを収集・蓄積できる環境を築いた産業が、このブームの勝者になるのではないでしょうか。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。