Lesson 2 機械学習やディープラーニングには、どんな手法があるの?:機械学習&ディープラーニング入門(概要編)(2/3 ページ)
3つの代表的な学習方法

学習にもやり方がいくつかあって、代表的なものが次の3つになるよ。ちなみにこれ以外にも半教師あり学習(Semi-Supervised Learning)というのもあるけど、これはまだ覚えなくていいと思う。
- 教師あり学習(Supervised Learning): 正解が決まっているトレーニングデータを使って学習し、過去の正解にできるだけ近似(回帰/分類)する入出力パターンのモデルを構築すること
- 教師なし学習(Unsupervised Learning): 正解が決まっていないトレーニングデータを使って学習し、クラスタリングや次元削減によって本質的なデータ構造のモデルを構築すること
- 強化学習(Reinforcement Learning): プログラムの行動に対するフィードバック(報酬・罰)をトレーニングデータとして使って学習し、次に最も取るべき行動方針のモデルを構築すること

……、あーあー……何言ってるのか全く分からないよ。まずは、最初の教師あり学習を身近な例で教えてよ。
教師あり学習

例えば動物の写真を見て「犬か」「猫か」を判断する問題があるとするよね。子供の場合、両親から「これはワンワンですよ」「これはニャンニャンですよ」などと教えられながら、犬と猫の区別を学んでいく。これと同じように教師あり学習では、動物の写真ごとに「これは犬です」「これは猫です」などの正解ラベル(labels=教師データ:labeled training data)と一致するかをフィードバックされながら、犬と猫の区別を学んでいくということよ(図5)。


名前のとおり、教師がいるときの学習ということだね。

先ほど「フィードバック」と言ったのは、学術的には「ネットワークに誤差信号を戻す」という意味で、バックプロパゲーション(Backpropagation、誤差逆伝播)と呼ばれているよ。

バックプロパゲーション、長いけど覚えた! あと、回帰とか分類とか言ってたけど、これは何なの?
回帰は「連続的なデータ」の問題を、分類は「離散的なデータ」の問題を解決するために使うよ。
回帰

連続的なデータ?
例えばマナブは毎日体重計に乗っているよね。1日1日ちょっとずつ値が変わりながら体重の線が推移していくでしょ。こういう点々にフィットする線を引いていける(=学習できる)のが連続的なデータ(図6)。ちなみにこの場合、正解ラベル(教師データ)は、次の日の体重になる。他には、毎日の温度とか、株価の推移とか、そういうものが例として挙げられるよ。
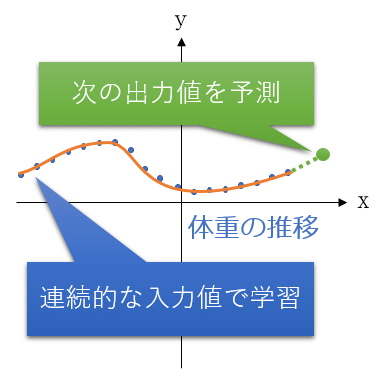 図6 連続的なデータによる回帰の例
図6 連続的なデータによる回帰の例 なるほど。確かに毎日、体重が減っていっていれば、今日の体重から連続した翌日の体重はこれくらい減っていると予測できるね。じゃあ離散的なデータは?
分類
例えばさっきの犬・猫の分類判断がまさにそれ。動物の顔の特徴(耳・目・鼻・口など)を何らかの方法で数値化してグラフ上に点としてプロットすると、これは体重のように綺麗に連続するデータとはならないで、ばらばらの点になってしまうのよね。写真に対する正解ラベル(「これは犬です」「これは猫です」)は分かっているので、「犬の点の集まり」と「猫の点の集まり」があれば、その集まりの中間に線を引いていける(=学習できる)よね。そうやって線で区分けされるのが離散的なデータ(図7)。他には、手書きで書いた数字画像を0〜9の数値に分類するとか、そういうものが例として挙げられるよ。
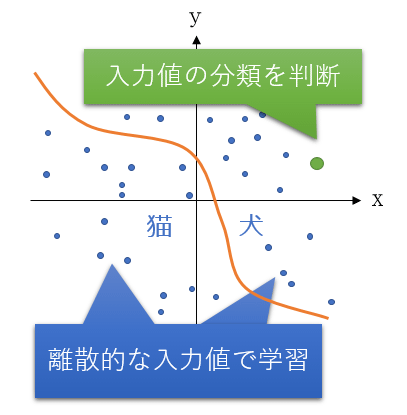 図7 離散的なデータによる分類の例
図7 離散的なデータによる分類の例 
新しいデータを与えたときに、その点が「犬側に入るか」「猫側に入るか」が予想(判断)できるということか。何となく分かった。
「次の値を予測する、もしくは分類を予想(判断)する」というのがポイントで、これが教師あり学習の目的となっているわけ。回帰と分類の用途を学術的な言葉でまとめると、次のようになるよ。
- 回帰(regression): 連続する入力値に対する次の値を予測し、その結果を出力したい場合に使う
- 分類(classification): 離散的な入力値を、事前に定義された複数のクラスに分類し、その結果を出力したい場合に使う
教師なし学習も具体的な例をお願い。
教師なし学習
これは先ほどの教師あり学習の分類に似ているけど、違うから注意して聞いてね。例えば点が散らばっていて、「これを2つのグループに分けてください」と言ったときに、人間だったら「この辺とこの辺はグループになっている」と判断して枠線を引ける(=学習できる)よね(図8)。機械学習でも、同じように枠線を引いてデータを複数のグループに分割していくのよ。このときの分割には、教師あり学習の場合と違って、正解があるわけではないというのがポイントね。分割に対する正解ラベルはない(つまり教師データがない)ので、「教師なし学習」と言われているの。
 図8 離散的なデータによるクラスタリングの例(教師なし学習)
図8 離散的なデータによるクラスタリングの例(教師なし学習) クラスタリング
「複数のグループに分割する」って言われても、うまくイメージできないなぁ……。
例を挙げるなら、商品の購買者データ(年齢、性別、居住地など)を基に顧客を無理やりいくつかのグループに分けるとか、が考えられるね。このように複数のグループ(=クラスター)に分割することは「クラスタリング」と呼ばれているの。
何のためにクラスタリングするの?
例えばグループ内のある人が買った商品は、同じグループ内の別の人も購入する可能性が高いなどの傾向が分かれば、その商品を同じグループ内の別の人々にもお勧めするなどの活用方法が考えられるよね。回帰や分類と同じように、クラスタリングの用途を学術的な言葉でまとめておくと、次のようになるよ。
- クラスタリング(clustering): 入力値を、事前に定義されていないグループに分割したい場合に使う
じゃあ、「教師なし学習=クラスタリングの問題を解決する方法」と覚えとけばいいの?
次元削減
いや、それだけでなく、例えばデータの圧縮や可視化を行うための「次元削減(Dimensionality Reduction)」などにも、教師なし学習はよく使われているのよね。次元削減については、後で出てくる「オートエンコーダー」のところで詳しく説明するね。クラスタリングや次元削減に共通するのは、「データの背後に存在する本質的な構造を抽出している」ということ。これがポイントで、教師なし学習の目的となっているわけ。
ふうん。それじゃぁ最後の強化学習も具体的にお願い。
強化学習
例えば「運転する」「ゲームで対戦する」というような、ある目的に対して望ましい行動をさせたいプログラムを作るときに使う学習方法だね。要するに、行動方針を学習するってこと。どうやって学習するのかというと、ダイナミックに変化する環境下において、プログラムが何かしらの行動を起こしたときに、それが「良かったか」「悪かったか」というフィードバックを与えられることで学習を実現しているの。
あれ? フィードバックと言えば、教師あり学習だったよね?
教師あり学習のフィードバックは正解ラベル(教師データ)だったけど、強化学習のフィードバックは報酬(rewards)もしくは罰(penalty)という点が全く違うわね。これによって、正解の出力をそのまま学習するのではなく、長期的に見て価値(=報酬の合計)が最大化する行動を「望ましい行動」として学習していくことになるの。

やっぱよく分からないなぁ。身近な例で言ってよ。
例えば犬のしつけを考えてみて。「お手」と言ったら、「飼主の手の上に犬自身の手を乗せる」のが、本来の望ましい行動になるよね。しつけでお手をできるようにさせたいなら、たまたまでも「お手」と言ったときに「手を乗せる」ことがあったら犬を褒めてあげる。これが報酬。ちなみに、それ以外の行動を取ったときは怒るなら、それは罰になるね。この報酬(や罰)を重ねることで、「お手」という言葉に対して「手を乗せればよいのだ」という行動パターンを学び、報酬が最大になるのが「望ましい行動なのだ」と学習していけるというわけ。
“望ましい行動”
ところでさっき、教師あり学習/教師なし学習が解決できる問題として「回帰」「分類」/「クラスタリング」「次元削減」という用語が出てきたけど、強化学習が解決できる問題は何て言うの?

強化学習については、ひと言で表現する用語はないと思う。強いて言葉にするなら「望ましい行動」の問題になるけど、伝わりにくいから「強化学習」としか言い様がないわね。
ディープラーニングと学習方法
テレビでは、「今のディープラーニングによるAIは、自ら学習できるからスゴイ」と言ってた。これは何学習のことになるの?
話題になった囲碁のAlphaGoあたりを指して言ってるんだと思うけど、それは強化学習のことだろうね。囲碁で最終的に勝利するための行動を、自己対戦を繰り返すことなどで学習しているので、そういう言い方になるんだと思う。
それなら、ディープラーニングは強化学習を使うことが一番多いの?
いえいえ、教師あり学習の方が多いわね。例えば画像の犬/猫の判定だったり、音声の日本語/英語の判定だったり。他には自然言語だったら、直前の入力単語に対して、次に来るべき単語は何かとか。そういった分類問題や回帰問題の解決のために、ディープラーニングはよく使われているという印象を私は持っているわ。
もしかして強化学習ってあまりうまくいってないの?
確かに強化学習は、教師あり学習などよりも、なかなか成果を出しにくい難しい技術という側面はあると思うわ。だけど大きな成功事例もあって、例えば2017年11月に発表された「AlphaGo Zero」は、教師となるプロ棋士との対局データがない状態から、強化学習のみで学習を行った結果、以前のAlphaGoに全勝できるほど強くなったんだよ。他にはグーグル傘下のDeepMind社の成果で、「Atari 2600」という昔のゲーム機のゲームプレイを強化学習したら人間を上回るスコアを記録できた、という論文が科学雑誌『nature』で2015年2月に掲載されているわね。

やっぱ強化学習ってめっちゃスゴイやん!
強化学習は自動運転でも重要な学習方法として研究されているので、今後さらに発展していく分野なのは間違いないわ。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。