書籍や番組のレビューに含まれる「ネタバレ」をAIで検出? カリフォルニア大:これはネタバレ? それとも違う?
カリフォルニア大学サンディエゴ校の研究チームが、書籍やテレビ番組のオンラインレビュー投稿の中から“ネタバレ”を検出し、フラグを付けるAIベースのシステム「SpoilerNet」を開発した。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
カリフォルニア大学サンディエゴ校の研究チームが、書籍やテレビ番組のオンラインレビュー投稿の中から“ネタバレ”を検出し、フラグを付けるAI(人工知能)ベースのシステム「SpoilerNet」を開発、論文を発表した(SpoilerNetは、「ネタバレネット」の意)。Amazon.comに所属する研究者も参加した。
もうネタバレを見たくない
カリフォルニア大学サンディエゴ校のコンピュータ科学教授で、論文の著者の一人でもあるNdapa Nakashole氏は次のように述べている。
「ネタバレはインターネットのあらゆる場所に広がり、SNSでも非常にありふれている。私たちはネタバレから受ける苦痛を理解しており、それがいかに自分の体験を台無しにするかを理解している」
一部のWebサイトでは、自分の投稿に対して「ネタバレあり」を示すタグを手動で付けられるようにしている。だがそのようなサイトでもタグを付けない投稿者は少なくない。さらに、そもそもそのような仕組みがないWebサイトも多い。
そこで研究チームは、ネタバレの投稿を自動的に検出できるニューラルネットワークベースのAIシステム開発に乗り出した。レビューの投稿ごとにネタバレが含まれている確率を示すシステムだ。
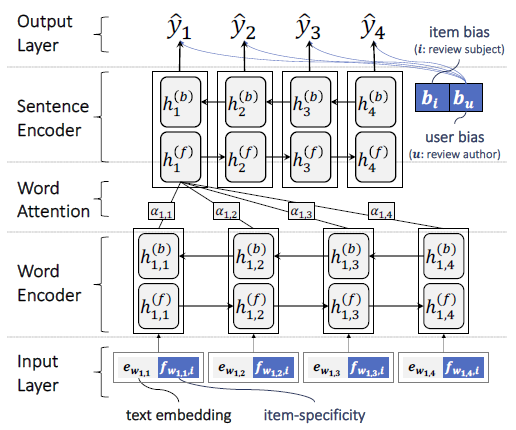 SpoilerNetのアーキテクチャ(
SpoilerNetのアーキテクチャ(開発に当たって「人々がネタバレ投稿をどのように書くのか」「どのような言語パターンや内容があれば、投稿がネタバレになるのか」を理論的に理解し、AIシステムに学習させる必要があったという。
ネタバレデータがない――では作ろう
研究チームはまず、ネタバレを含む文をまとめた大規模データセットを探したが、見つからなかった。そこで、書籍の感想やレビューを共有できるソーシャルネットワーキングサイト「Goodreads」から収集した。2万5475冊の書籍に対して、1万8892人が投稿した合計137万8033件の書籍レビュー投稿だ。文章の総数は1762万2655に及び、そのうち、3.22%にネタバレタグが付いていた。
 Goodreadsから得たレビューデータに対してSpoilerNetが下した判定の一例。右端にネタバレ確率が表示されている(
Goodreadsから得たレビューデータに対してSpoilerNetが下した判定の一例。右端にネタバレ確率が表示されている(カリフォルニア大学サンディエゴ校のコンピュータサイエンスで博士課程に在籍する学生で、論文の筆頭著者でもあるMengting Wan氏はこのデータセットについて次のように述べている。
「きめ細かくネタバレという注釈が付いた文をこれだけ大規模に収集したデータセットは、過去にないのではないか」
研究チームによると、ネタバレを含む文は多くの場合、レビューの文中の後半に集中している。だが、さまざまなユーザーがさまざまな基準でネタバレのタグを付けるので、このようなばらつきを踏まえてニューラルネットワークを慎重に調整する必要があった。
ある同一の単語の意味が文脈によって変わる場合にも注意しなければならない。例えば、「緑」という単語はレビューによっては、単純に色を指している。だが、重要な登場人物の名前を意味していたり、ネタバレのヒントになっていたりする場合もある。このような違いを特定し、理解する点が難しいという。
認識率はどこまで上がったか
SpoilerNetをトレーニングするため、まず、Goodreads上のレビューから約80%を取り出した。残りの約20%はトレーニング後のSpoilerNetの性能を測定するために使った。検証の結果、SpoilerNetは88.9〜91.9%の精度でネタバレを検出した。
同様に884のテレビ番組に対する1万6261件以上の単一の文からなるレビューを「TV Tropes」から収集した。トレーニングの結果、73.7〜80.3%の精度でネタバレを検出するようになった。
なお、誤判定した部分を検証してみると、特定の単語に引きずられていた。例えば「殺人」や「殺害」といった単語だ。
汎用ツールとして広がるか
Goodreadsデータセットは今後、ツイートなど、さまざまなコンテンツに含まれるネタバレを検出するアルゴリズムを鍛えるための強力なツールとして使われる見通しだ。
今後はネタバレを見ないでも済むようになるWebブラウザ用拡張機能として、SpoilerNetが使われていくかもしれないという。
研究チームは、2019年7月28日〜8月2日にイタリアのフィレンツェで開催される学術会議「Association for Computational Linguistics(ACL)」の年次総会において、SpoilerNetの研究開発について発表を行う予定だ。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。