常に偵察にさらされるWebアプリケーション、脆弱性が見つかるまで:守りが薄いWebアプリケーション(2)(1/2 ページ)
当連載ではWebアプリケーションのセキュリティが置かれている状況と、サイバー攻撃について具体的なデータを示し、防御策を紹介している。前回はインターネットにはクリーンではないトラフィックが常にまん延していることを実証し、攻撃対象となる領域と、領域ごとの被害例について簡単に整理した。今回は、攻撃者の目線を交えて、Webアプリケーションが攻撃を受けるまでにたどるプロセスに沿って、順に解説していく。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
セキュリティ対策の効率を高めるために
いまWebセキュリティの世界で、攻撃者と防御する側、優位に立っているのはどちらか? 防御側が圧倒的に不利な状況にあるといえる。
インターネットに公開されているWebサイトはいつでも誰でもアクセス可能であり、さらに防御側と攻撃側は常に1対多の状況にある。防御側は限りあるリソースの中で、多数の攻撃に対応しなければならず、対処が手薄になる瞬間もあるだろう。
さらに防御側はどれか1カ所を守ればよいというわけではない。守るべき箇所は複数ある。その一方で攻撃側は、どこか1カ所を突破できれば成功だ。つまり、防御側は圧倒的に不利な状況にあるのだ。
不利な状況で戦うには、防御の効率と精度を高めることが必須であり、そのためには、攻撃の方法を理解した上で、防御を固めていくことが重要だと筆者は考えている。
情報漏えいを伴う深刻なインシデントは、たまたま攻撃が成功した結果なのではない。情報収集に始まる周到な手順を攻撃者が踏まえた結果、ほとんどが成功しているのだ。
一般に攻撃側は次のような流れで攻撃を進めている。順を追って詳しく解説していこう。
- 偵察行為(情報収集)
- 脆弱(ぜいじゃく)性の発見
- Webアプリケーションへの攻撃
偵察行為:攻撃者は有用な情報をどうやって手に入れているのか?
偵察行為では、攻撃を開始する前にターゲットについての情報収集をする。ここでは実にさまざまな方法で多くの情報を集めている。例えばサーバに対するポートスキャンや、Webサイトのスペックを調べるツールの利用、公開されている情報から何かの手掛かりになる情報を取得するといった手段だ。
ツールを使って、サーバやサービスの検出や識別ができれば、以下のような具体的な情報が明らかになる。
- 稼働しているサービスの名称
- 使用しているソフトウェアとバージョン
- 使用しているオペレーティングシステム
- サブディレクトリとパラメーター
- ファイル名、パス、データベースフィールド名
公開情報からも多くの手掛かりが得られる。例えば、Whoisの検索やDNS問い合わせからも、ドメインの登録者や企業の住所、メールアドレス、電話番号、担当者名、ドメインを登録しているレジストラなどの情報が得られる。
これだけでも十分有用な情報にはなり得る。加えて、さらなる情報を得るためのソーシャルエンジニアリング(※1)の情報源としても利用できてしまう。
※1 人の心理的な隙や行動のミスに付け込み、特定の行動を相手にとらせることで、個人情報や機密情報を詐取することをソーシャルエンジニアリングいう。
Googleの検索エンジンを悪用した情報収集もある。「Google Hacking」(もしくはGoogle Dorking)と呼ばれる手法だ。
Googleには通常のキーワード検索に加えて、いろいろな「オプション」が用意されている。例えば、「あるサーバプログラムに特徴的なディレクトリの名前」などを指定して検索できる。便利な機能だが、悪用すれば脆弱性が見つかっているプログラムを利用するサイトを“リストアップ”する目的にも役立ってしまう。
このように攻撃者は多様な手法を駆使してターゲットについての情報収集を進めていく。本来違う目的で使われるものではあるが、われわれにとって便利な機能は、攻撃者にとっても同じように便利なのである。
脆弱性の発見:脆弱性を見つけ出すアプリケーションの分析
脆弱性についても簡単におさらいをしておこう。Webアプリケーションの脆弱性は設定/設計ミスや、実装中の考慮漏れなどが原因だ。だが、関連するコードがあまりにも複雑であるため、いま動いているサービスに「100%脆弱性は存在しない」とは誰も言い切れないのが実情だ。悪用可能な脆弱性が見つかってしまえばそこがセキュリティホールとなる。
攻撃者は偵察行為で情報収集をした後に、攻撃対象のアプリケーションの分析を進め、具体的な脆弱性の特定を行っていく。どのような攻撃手段を持っているか、さらに攻撃の目的によって分析の対象は異なるものの、次のような観点で潜んでいる脆弱性を特定していく。
- 隠れたコンテンツの検出
- ユーザー入力のエントリーポイントの特定
- エントリーポイントの挙動の確認
- ページソースやURLからアプリケーションの内部構造と機能を確認
- セッションcookieの確認
- わざとエラーを出力させて、メッセージを確認
- ファイルのアップロード/ダウンロード機能の調査
代表的なWebアプリケーション攻撃であるXSS(クロスサイトスクリプティング)、SQLイジェクション、コマンドイジェクションといった攻撃は、Webページに設けたユーザーの入力フォームの脆弱性の悪用が原因の一つである。
入力値を検証していない、または入力検証の一部の不備によって任意のコードが実行されてしまう、このような脆弱性によって起こるケースが多い。
攻撃者は、ページ上のユーザー入力フィールドを特定し、URLやPOSTデータ、GETメソッドのクエリストリング、cookieなどの“エントリーポイント”に対し、アプリケーションが意図していないと考えられる値を入力して、反応を探っていく。例えば図1に挙げた文字は一般にリスクの高い動作を引き起こす特殊な文字として知られている。
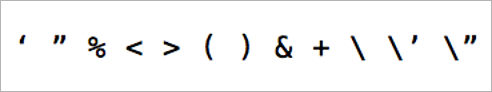 図1 リスクの高い動作を引き起こす特殊な文字の例
図1 リスクの高い動作を引き起こす特殊な文字の例これらの文字を含む文字列に対してアプリケーションが本来の動作をするかどうかを調べていく。そうではない動作が見つかった場合、それが脆弱性となる。いったん脆弱性が見つかれば、具体的な攻撃へとつながっていく。
Webアプリケーションが提供する機能とそれに対する攻撃手法を図2にまとめた。

例えば、「ログイン機能」の項目を見てみよう。ログインエラーが起こったときのメッセージが「未登録のユーザーIDです」と表示されるサイトをよく見掛ける。利用者に役立つメッセージだが、攻撃者はこれを逆手にとり、登録済みのユーザーIDのリストを作るために悪用する。
このような手法を防ぐには、「ユーザーIDまたはパスワードが間違っています」というように、エラーの原因が特定できないようなメッセージを出力しなければならない。
攻撃者は脆弱性スキャンツールやプロキシツール、botなどを使ってアプリケーションの分析を行い、悪用できる脆弱性の特定をした上で、攻撃を組み立てていくのである。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。