PyTorchで畳み込みオートエンコーダーを作ってみよう:作って試そう! ディープラーニング工作室(2/2 ページ)
学習
では学習を行いましょう。といっても、そのコードはいつも通りです。
net = AutoEncoder2(enc, dec)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
EPOCHS = 100
output_and_label, losses = train(net, criterion, optimizer, EPOCHS, trainloader)
学習が終わるまでには1時間弱かかりました(CPUのみを使用)。エポック数は100ですが、前回の100エポックの学習であまりデキがよくなかったヤツでも1時間半かかったことを考えると速度面ではかなりよいものといえるでしょう。
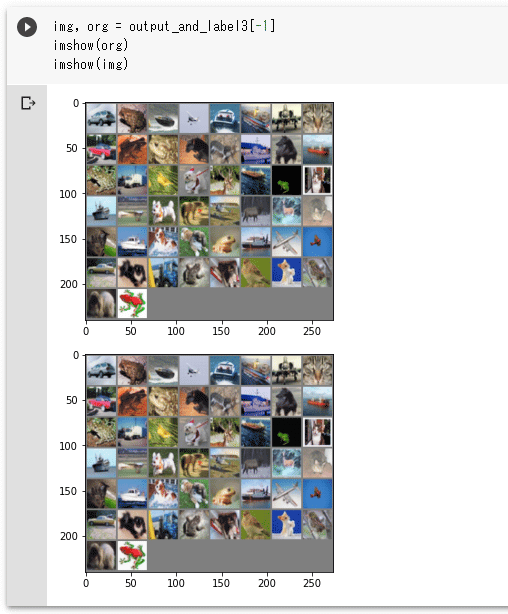
でも、問題はどんな画像が復元されるかです。
img, org = output_and_label[-1]
imshow(org)
imshow(img)
どんな結果になったでしょう。
 実行結果
実行結果うーむ。全般にもやが掛かったようになっているのが気になります。復元度合いも正直これではいいとも悪いともいえません。ちなみにテストローダーから読み込んだ元画像、100エポックの学習を終えた時点のモデルに元画像を入力した結果、同じモデルでもう200エポックを学習させたものによる結果を以下に示します。
 画像比較
画像比較100エポックのものも、300エポックのものもさほど変わらない結果となってしまいました。記事には掲載していませんが、追加で200エポックの学習をしている間に、損失が下がらなくなっていたので、実は予想できる事態だったのですが、ハッキリと結果が出るとがっかりするところではありますね。
では、どうすれば改善できるでしょうか。少し考えてみます。
チャネル数とカーネルサイズを大きくしてみる
CNNには畳み込みやプーリングによって、画像の特徴を抽出するという機能があります。ということは、チャネル数(カーネル数)を増やしたり、カーネルサイズを大きくしたりすることで、表現力が向上するのではないでしょうか。最後にこれを試してみることにします。
本来、実験においては「変化させる要素は1つだけ」というのが鉄則なのですが(そうでなければ、結果に変化をもたらしたのが何かを特定できません)、筆者もいい加減面倒になってきたので、チャネル数とカーネルサイズをまとめて増やしてしまうことにしました。
enc2 = torch.nn.Sequential(
torch.nn.Conv2d(3, 16, kernel_size=4, padding=1, stride=2),
torch.nn.ReLU(),
torch.nn.Conv2d(16, 32, kernel_size=4, padding=1, stride=2),
torch.nn.ReLU()
)
dec2 = torch.nn.Sequential(
torch.nn.ConvTranspose2d(32, 16, kernel_size=4, stride=2, padding=1),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(16, 3, kernel_size=4, stride=2, padding=1),
torch.nn.Tanh()
)
先のコードとの大きな違いは、もちろんConv2dクラスでチャネル数を増やした点です。1つ目のConv2dクラスのインスタンス生成では、出力チャネル数を「16」から「32」に増やしました。2つ目でも「8」から「16」に増やしています。カーネルサイズも「4」としました。これにより重みやバイアスはかなり増えるでしょうが、その分、このモデルの表現力も向上するはずですし、入力データを次元削減した後は依然として8×8×8=512次元のデータ量となっています。
加えて、MaxPool2dクラスを使わないようにもしてみました(その分、Conv2dクラスのインスタンス生成でstrideパラメーターを指定して、データ量が削減されるようにしています)。畳み込み層の数も増やしたかったのですが、ここではヤメておきましょう。
このコードを先ほどと同様にして、学習させた後に、得られた画像は次のようになります。
 実行結果
実行結果素晴らしいものが出てきました。3つのモデルによる画像復元の比較画像も以下に示します。
 比較画像
比較画像このモデルは100エポックを学習しただけのもので、かかったのは50分ほどでした(体感では、最初のニューラルネットワークよりも若干早く学習が終わっています)。ということは、チャネル数を増やし、カーネルサイズも大きくすることで、かなりの精度で画像を復元できる畳み込みオートエンコーダーを前回よりも短時間で学習させることができたということです(幾つかの要素を変化させたため、どれが精度の向上や学習の高速化にどれだけ貢献しているのかは不明です)。
しかし、短時間で学習を終わらせるにはまた別の方法があります。そこで、次回はその方法について学んでみたいと思います。では、最後に、いつものコードを一覧しておきましょう。
いつものコード
以下に各種モジュールのインポート、学習を行うコードをまとめたtrain関数、データセットとデータローダーの定義、オートエンコーダーを実装するAutoEncoder2クラスの定義などのコードを示します(畳み込みを行うために、train関数の内容が前回とは少し変わっていますが、説明は省略します)。
import torch
from torch import nn
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
from torchvision.datasets import CIFAR10
import numpy as np
import matplotlib.pyplot as plt
def imshow(img):
img = torchvision.utils.make_grid(img)
img = img / 2 + 0.5
npimg = img.detach().numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
def train(net, criterion, optimizer, epochs, trainloader):
losses = []
output_and_label = []
for epoch in range(1, epochs+1):
print(f'epoch: {epoch}, ', end='')
running_loss = 0.0
for counter, (img, _) in enumerate(trainloader, 1):
optimizer.zero_grad()
output = net(img)
loss = criterion(output, img)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / counter
losses.append(avg_loss)
print('loss:', avg_loss)
output_and_label.append((output, img))
print('finished')
return output_and_label, losses
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = CIFAR10('./data', train=True, transform=transform, download=True)
testset = CIFAR10('./data', train=False, transform=transform, download=True)
batch_size = 50
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)
testloader = DataLoader(testset, batch_size=batch_size // 10, shuffle=False)
class AutoEncoder2(torch.nn.Module):
def __init__(self, enc, dec):
super().__init__()
self.enc = enc
self.dec = dec
def forward(self, x):
x = self.enc(x)
x = self.dec(x)
return x
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。