マーケティング分析で使われるビッグデータ基盤をセキュリティ業務に応用した理由:セキュリティ組織にデータ民主化を――「次世代セキュリティDWH」大解剖(1)
マーケティング分析で用いられているデータ基盤サービスを活用した、リクルートの「次世代セキュリティDWH」の構築事例を中心に、最新のセキュリティログ基盤の動向を紹介する連載。初回は、その背景やきっかけ、考え方について解説する。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
リクルートのセキュリティオペレーションセンター(SOC)でセキュリティアーキテクトをしている日比野です。2019年に「セキュリティログ分析基盤活用入門」と題し、計3回の連載の中でセキュリティ業務におけるログの活用方法からセキュリティログ分析基盤のアーキテクチャ、求めるスキルセットや組織体制について具体的な内容に触れながら執筆しました。
前回の連載から約2年がたち、クラウドサービスもさらに充実しました。新たなビジネスの創造や付加価値の向上に直結するデジタルマーケティングの領域では、特にデータ分析関連のサービス、機械学習(ML)や人工知能(AI)などの技術を中心にデータ基盤がコモディティ化され始めてきた印象があります。
本連載は前回の続編的な位置付けとして、マーケティング分析で用いられているデータ基盤サービスを活用した「次世代セキュリティDWH(データウェアハウス)」の構築事例を中心に、最新のセキュリティログ基盤の動向を紹介します。
プロジェクトの概要
2021年6月から2.5カ月の開発期間を経て、クラウドサービスを活用した新たなログ基盤を構築しました。筆者は勝手に「次世代セキュリティDWH」と名乗っていますが、まずはどのようなプロジェクトなのかを簡単に説明します。
なぜ、新たなログ基盤を構築したのか
まず、本プロジェクトで構築したログ基盤はセキュリティアナリストが監視業務に利用するためのSIEM(Security Information and Event Management)ではありません。セキュリティ組織のエンジニアではない方々にも「ログ(というファクト)に基づいた意思決定を根付かせたい」という思いを形にするために、実験的に構築したシステムです。
今回構築したシステムの対象業務は、筆者が以前分類した「ログを利用するセキュリティ業務」のうち、ハンティング業務とフォレンジック業務の中間的な位置付けです(「ロジック開発業務」と呼ぶことにします)。
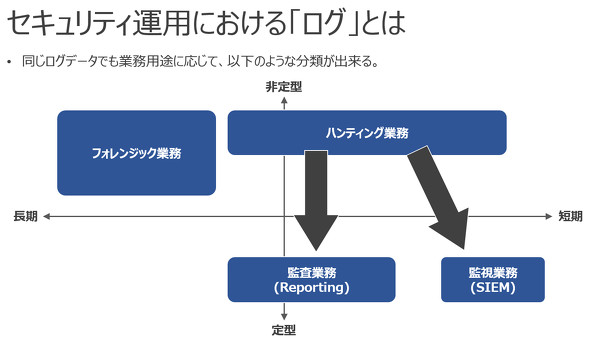 セキュリティ運用における「ログ」とは(記事「
セキュリティ運用における「ログ」とは(記事「ロジック開発業務ではハンティング業務やフォレンジック業務と同じく、必要なイベントをログから抽出するにはSQLやSPL(Search Processing Language)などのクエリ言語を用いて、複雑なクエリ構文を組むスキルが求められます。
今回の取り組みではクエリ言語習得のハードルを下げ、技術者以外でも自由にログを検索したり、ダッシュボードで可視化したりすることができる環境の提供を重要な要素としました。
ログに求められる環境変化
2020年以降のコロナ禍の影響を受け、企業の生産活動は大きく変化しています。その変化の一つとして業務を行う場所が挙げられ、テレワークに移行した企業が増えていると感じています。リクルートもそのうちの一社です。働く場所がオフィス外になることでこれまでのファイアウォールによる境界防御から新しいゼロトラストモデルによるセキュリティへの移行が必要になりました。
ログの果たす役割も変わってきており、オンプレミス環境の機器ログ(SyslogやCSVフォーマットなど)だけではなく、クラウドサービスのAPI経由のログも必要となるケースが増えてきており、ログ環境全体の再設計が必要になってきました。

扱うログの種類も増え、蓄積に必要なストレージの大容量化も予想されます。具体的にはAPI経由で取得するクラウドサービスのログはJSONフォーマットなので、CSVやTSVのフォーマットと比べると同じ内容のログでもフィールド名の分だけサイズが大きくなってしまいます。ストレージ圧縮が効くとはいえ、サイジングの考慮が必要です。
id timestamp ipaddress username version byte 1 2022-01-10T01:11:32 192.168.1.11 hibino 1 64 2 2022-01-10T02:12:26 192.168.2.31 hisashi 1 103
{
id: 1,
timestamp: "2022-01-10T01:11:32",
ipaddress: "192.168.1.11",
username: "hibino",
version: 1,
byte: 64
},
{
id: 2,
timestamp: "2022-01-10T02:12:26",
ipaddress: "192.168.2.31",
username: "hisashi",
version: 1,
byte: 103
}
既存の監視ロジックだけでは検知に対応し切れない可能性もあります。攻撃の進化に合わせて新たなロジックをアジャイル的に迅速に開発できる環境が必要になると考え、まずは2人体制で開発をスタートしました。
ログ基盤の抱える課題とは
これまで「Splunk」「Elastic Stack」を用いたSIEMの導入や運用改善のプロジェクトにおいて、テックリードのポジションを何度か経験しました。この2つの製品はよく比較されますが、成り立ちが大きく異なり、似て非なる製品です。それぞれに特徴があり、それぞれに強みと弱みがあると思っています。
セキュリティのユースケースでは、どちらもログ監視による脅威検知を主目的とした利用になります。監視業務で利用するログと同じものをハンティング業務やフォレンジック業務でも利用することが多く、SIEMで複数の異なる要件のログ業務を兼ねると、結果的にコストが高くなってしまうケースがあります。
これまでの経験を踏まえ、ログ基盤の抱える課題として、3つの観点で解説します。
- 運用維持コストにおける課題
- データ活用におけるスキル格差の課題
- DevOps人材確保における課題
運用維持コストにおける課題
従来のウオーターフォールによる開発手法でログ基盤を導入する場合、5年先を見越したサイジングが必要になります。しかし、年々新たな攻撃手法が見いだされたり、新たなソフトウェアの脆弱(ぜいじゃく)性が見つかったりする中、5年も先のログ要件を定義するのは困難です。
SIEMをはじめとするログ製品の課金体系は、だいたい「1日に取り込んだログ容量」または「サーバの台数」です。そのため、取得対象となるログ容量が想定以上に増えると導入時の見立てが外れてしまい、予算オーバーになってしまいます。
予算オーバーにならないように優先度の低いログを削ったり、ログの保持期間を短くしたり、導入した目的を果たせない状態にしてしまうケースも何度か目にしました。また拡張に必要なソフトウェアのライセンス料金が高いこと、クラスタへのサーバ追加作業には技術力と分散システムの運用経験を要することなどがログ基盤を運用維持する難易度を高めます。
Elastic Stackの場合、コアコンポーネントの「Elasticsearch」がDAS(Direct Attached Storage)でのSSD性能のストレージや多くのキャッシュメモリを要求します。これは、Elasticsearchがリアルタイム性に優れた全文検索エンジンであり、Elastic Stackはこのアーキテクチャをベースに作られていることに起因しています。
そのため、ソフトウェアのライセンス料金以外にインフラストラクチャにも意外とコストがかかります。仮にフォレンジック業務の用途を兼ねると年単位での保持が必要なので、このストレージコストが負担になります。
この課題に対応するために、Elasticでは「Hot-Warm-Cold」アーキテクチャを実装し、「Amazon S3」の安価なオブジェクトストレージに古いログを退避できるような仕組みを採用しました。Splunkでも同じ考え方でWarm領域のデータをS3やGoogle Cloudの「GCS(Google Cloud Storage)に格納できる「SmartStore」機能を提供しています。
クラウド環境のオブジェクトストレージを採用できる場合、大きなコスト削減を見込めます。しかし、これらのログ製品はログを蓄積するコンポーネントのストレージ領域にデータを格納しますが、コンピューティングリソースと密結合状態にあるので、常にサーバを稼働させておく必要があります。クラウド環境のサーバを常に稼働させておくことは従量課金でコストがかかってしまうので、この部分の運用維持コストを下げることが課題でした。

データ活用におけるスキル格差の課題
SIEMの監視ロジックを開発するには、SPL(Splunk専用のクエリ言語)やKQL(「Azure Sentinel」専用のクエリ言語)などの製品独自のクエリ言語と向き合うことになります。
Linuxの「grep」コマンドのようにパイプでクエリを数珠つなぎにして記述するものが多く、エンジニアが操作する前提になっています。製品独自の言語なので、有識者人材の確保が難しくスキル習得にそれなりの経験と学習時間が必要になります。
セキュリティでは、脆弱性が見つかってから攻撃が始まるまでのスピードが短くなっているので、インシデント対応時には、若手に「経験」と称して、実務に携わらせる時間の猶予がないのが現実です。結果的にスキル保有者に緊急性の高いクエリ開発の機会が集中してチームのスキル格差が出来上がってしまうことがあります。
対応者のスキル格差があると通称「熟練者の開発したクエリをレビューできない問題」が発生します。複雑な監視ロジックを読み解くには多くの知識が必要になります。クエリの可読性を高めることで解消できる部分もありますが、クエリの開発規約やレビュー方式の整備など、より一層熟練者にタスクが集中しがちになることがデータ活用における課題です。
DevOps人材確保における課題
昨今のログ基盤は、さまざまな要因により、導入時のシステム構成のまま運用できることは“まれ”です。その主な要因には、取得対象のログの仕様変更、新たな攻撃の判明による追加のログ取得などがあります。そのため、ログ基盤にはアジャイル開発手法が適していると思っていますが、そう簡単な話ではありません。
ログ基盤の運用にはインフラ運用管理者がアサインされる傾向がありますが、開発タスクも多く、手順書による定型的なオペレーションでは対応し切れません。データ基盤を支えるロールとして、「データエンジニア」という職種が新たに確立されつつありますが、データパイプラインの設計や継続的な基盤開発など多岐にわたるスキルセットが求められます。ログ基盤を含むデータ基盤の開発と運用に求められる技術スキルのハードルを下げることは、持続可能な安定運用をする上で非常に重要なポイントです。
課題解決の見立てとは
この5年間で大小問わずセキュリティインシデントなどをきっかけに何かしらのログ製品を導入し、CSRIT構築に取り組んでいるユーザー企業は増えてきたと感じています。ログ製品の導入効果を感じながらも、一方では継続的に運用するには課題があることも見えてきました。
これらの課題に対して、今回構築した「次世代セキュリティDWH」ではどのような見立てをしたのか最後に幾つか紹介します。
なぜ、クラウド型のDWHに目を付けたのか
なぜ、クラウド型のDWH、中でもGoogle Cloudに目を付けたのか。その決め手となったのは、2019年に開催された「Google Cloud Next '19 in Tokyo」でした。それまでもデータ分析基盤で「BigQuery」の圧倒的なクエリ性能や費用対効果の高さは理解していましたが、セキュリティのログ基盤として意識したことはありませんでした。
日本での展開を始めていた「Looker」の担当者からBigQueryと組み合わせてログ分析基盤として活用することのメリットを聞いた時に運用維持コストの課題に対する解決策の一つになるのではないかと感じたことを今でも覚えています。この日が検討のスタート地点になったと言っても過言ではありません。約2年かけてその可能性を模索し続けてきたことになります。
Google Cloudに目を付けた理由の1つ目は運用コストです。
SIEMのような常に分単位で監視クエリが必要になる使い方ではなく、インシデント対応のフォレンジック業務や新たな脅威をアドホックに分析するハンティング業務、月次などで作成する監査レポート業務では、BigQueryのようなクエリ課金のメリットが最大限に発揮され、頻繁に利用しないログデータを長期間保持することに向いているストレージ課金体系がマッチすると考えました。1GB当たり月額2セントなので、1TBでも2000円程度、さらに90日間更新がなければ保持コストは半額になります。
BigQueryはGoogle Cloud上で利用できるマネージドサービスです。そのため、サーバ管理などのインフラ運用にかかる負担が極小になります。フルスタックな技術要素になりがちなログ基盤運用において、インフラ領域の運用負荷を減らすことで必要なスキルの幅を抑えられると期待しました。BigQueryに限らず、今回採用したアーキテクチャは全てマネージドサービスで組んでいます。理由は同じで、インフラ運用にかかる負担を減らすことが主な目的です。
2つ目の理由は、BigQueryがSQLを使ってデータにアクセスするデータ基盤サービスであることです。
繰り返しになりますが、セキュリティのログ製品で使うクエリ言語はログ検索に特化した製品独自の言語で実装されています。その学習コストの高さを改めて課題として挙げておく一方で、Restful APIをベースとしたクエリしか扱えなかったElasticsearchなどのNoSQLデータベースにおいても、SQLでクエリできるインタフェースが用意されていたことを認識していました。そのため、SQLという言語は、自分が生きている間にはなくなることはないかもしれないという確信を持っていたことも大きな要因かもしれません。
SQLは「Oracle Database」「MySQL」「PostgreSQL」「Microsoft SQL Server」などの代表的なRDBMSで採用され、古くから利用されているクエリ言語です。Webアプリケーションの開発現場では必ずと言っていいほど利用されていますし、ITエンジニアの新人研修でも必須科目になっていることが多いです。そのSQLを扱うエンジニアですが、オンプレミス環境のRDBのパブリッククラウドへの移行が進むことでDBA(DataBase Administrator)の活躍の場が減ってしまう可能性を感じていました。そこで、SQLを使えるデータ分析基盤では、将来的なクエリ開発人材の確保に未来があるのではないかと考えました。
データ民主化を実現する「次世代BIツール」
BigQueryはデータウェアハウスサービスです。標準でWebベースのクエリエディタが付属していますが、クエリエディタでログを分析する難易度はかなり高いと思います。特に今回のコンセプトには「エンジニアではない方々にも気軽なログ分析環境を提供すること」があります。そこでエンジニアではない方々には、「次世代BI(Business Intelligence)ツール」と呼ばれているLookerに期待しました。
われわれが技術検証を開始した当時、LookerはまだGoogle Cloudの一部ではありませんでしたが、2020年2月にGoogle Cloudにジョインしています。BigQuery採用のきっかけになったLookerですが、非エンジニアのビジネスユーザー(マーケティング部の方々など)にもデータ分析できる環境を提供することで「データの民主化」を実現できると思っています。
Lookerに期待しているポイントは2つあります。
1つ目はLookMLによる「ロジックの共通化」です。これまで筆者が利用したBIツールでは、データベースに格納されたデータに対する加工処理や集計処理はグラフ単位で実行されていました。そのため、グラフの作成者のクエリスキルや経験によって、実行結果であるKPIに整合性が取れない問題が起きることがありました。
BIツールが表示してくれる結果の妥当性を証明することは労力のかかる作業です。しかし、Lookerでは事前に組織全体で共通化しておきたい分析ロジックをパーツ化しておき、グラフを生成するタイミングで(コードで)再利用できることが「次世代」の“ゆえん”だと感じています。セキュリティの監視ロジック開発を進めていく上でクエリスキルの属人化という課題を抱えていた私にとっては非常に強力な武器になると感じました。
2つ目のポイントは、直感的なUIです。これはElasticの「Kibana」を利用していた時に感じたことですが、分析開始時点でデータの中身がどうなっているのかを把握できているケースは“まれ”です。そのため、まずはデータの中身を調査するところから始まるわけですが、その分析者の導線に沿った画面になっているのが良いポイントだと思いました。「データカタログの作成が容易になっている」と言ってもいいでしょう。大量のデータの中から正しい意思決定をする上では非常に重要な要素です。
ローコードETLツールに期待したこと
ログ基盤の開発と運用の負担を減らす上でETL(データ抽出、変換/加工、書き出し)ツールは非常に重要なポイントです。データエンジニアにとって、さまざまなフォーマットのデータを1カ所に集める作業が全体の8割を占めていると言っても過言ではないと思います。
これまで「Splunk Forwarder」「Logstash」「Fluentd」を使い、ログデータを集めてきましたが、より学習コストが低く、運用性の高いツールはないものかと思っていたところでローコードETLサービスに出会いました。日本製のサービスでは、「trocco」「Reckoner」があります。
ローコードETLサービスには未知数の部分が多かったので、複数サービスで比較検討した上で技術検証をすることにしました。

次回は、実装方針とそのこだわりポイント
本稿では、なぜセキュリティのログ基盤にマーケティング分析などに利用されるデータ分析サービスを組み合わせて構築したのか、その背景やきっかけ、考え方について解説しました。
考え方について補足すると、2015年ごろに全文検索エンジンとして有名だったElasticsearchをELK Stackとして金融機関向けのセキュリティ監視システムに導入した時から筆者の考え方は変わっていません。
セキュリティに特化した製品は購入者のボリュームがデータ分析分野と比べると限定的になってしまいます。そのため、費用対効果が期待できない結果になってしまうケースがあります。利用者が多い、注目度の高い領域の技術をうまく横展開して応用することで費用対効果の高いソリューションの見立てができると考えていたので、今回も同じ考え方で応用してみたということです。
次回以降は、次世代セキュリティDWHの実装方針とそのこだわりポイント、得られた効果と今後の展望を紹介します。クラウド型の次世代SIEM/UEBA(User Behavior Analytics)サービスの動向やAI/ML技術を活用したセキュリティDWHの未来についても触れたいと考えています。お楽しみに。
筆者紹介
日比野 恒(ひびの ひさし)
株式会社リクルート リスクマネジメント本部 セキュリティ統括室 セキュリティオペレーションセンター ソリューションアーキテクトグループ所属
10年間、ITコンサルティング会社に在籍。セキュリティアーキテクトとして、主に金融機関や公共機関に対して、セキュリティ対策製品の提案導入、Elastic Stackを用いたセキュリティ脅威分析基盤の開発を推進。2019年から現職において、次期ログ基盤のアーキテクチャ設計やクラウドにおけるセキュリティ実装方式の検討を担当。
『Elastic Stack実践ガイド[Logstash/Beats編]』(インプレス刊)の著者。
公認情報システムセキュリティ専門家(CISSP)、公認情報システム監査人(CISA)、情報処理安全確保支援士(登録番号:000999)を保有。
関連記事
 セキュリティログ分析基盤におけるクラウド活用、組織体制、メンバー育成のポイント
セキュリティログ分析基盤におけるクラウド活用、組織体制、メンバー育成のポイント
セキュリティ業務における「ログ」と、その分析基盤の活用について解説する連載。最終回は、クラウド活用、組織体制、メンバー育成のポイントを紹介します。 SOCがSplunkログ基盤の移行先にAWSを検討したワケ
SOCがSplunkログ基盤の移行先にAWSを検討したワケ
リクルートのSOCによるログ基盤クラウド化検討プロジェクトの概要や失敗談、そこから得た学びを紹介する連載。初回は、背景や概要、AWSで検証した理由などについて。 なぜデータ基盤を作ったのか?「ゼクシィ縁結び・恋結び」で必要になった理由
なぜデータ基盤を作ったのか?「ゼクシィ縁結び・恋結び」で必要になった理由
「ゼクシィ縁結び・恋結び」の開発現場において、筆者が実際に行ったことを題材として、「データ基盤」の構築事例を紹介する連載。初回は、サービスの概要とデータ基盤が必要になった理由について。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。