コンピュータはどうやって言葉を認識しているのか? 自然言語処理(NLP)を基礎から解説:センター英語を例に分かる、自然言語処理入門(1)
センター試験を例に、自然言語処理の基礎を解説する本連載。第1回はコンピュータが言葉を認識するための手法について。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
自然言語処理(NLP)を用いた読解タスクにおいて、人間の性能をAIが上回るケースが増えてきていることを皆さんはご存じでしょうか? 自然言語処理という言葉自体がメジャーというわけではないため、そもそも自然言語処理で何ができるの? という方も多いと思います。
そんな方でも、日常生活で一度は「Google翻訳」などの機械翻訳を利用したことがあると思います。また、Appleの「Siri」やスマートスピーカーの「Alexa」のようなバーチャルアシスタントは、音声認識や自然言語処理の技術で成り立っているため、近年の自然言語処理はすでに普及しているのです。
本連載は、以下の3部構成になっています。
- 自然言語処理とはどのようなものなのか
- 自然言語処理の一連の流れ
- センター試験英語の読解問題にチャレンジ
この連載で扱うのは、難しい自然言語処理技術のほんの一部分になります。「自然言語処理って何に使えるの?」というエンジニアの方、「自然言語処理って言葉を初めて聞いた!」という初学者の方、そんな方もこの連載を読み終わるころには、「自然言語処理を使うとこんなことができるんだ!」「自分でもやってみたい!」というレベルまで到達していただくことを目標にしていますので、ぜひ読み進めてください。
人間の性能を超えた自然言語処理の事例紹介
自然言語処理を利用することでどんな問題が解けるのかを説明するために、AIが人間の性能を超えた例を紹介します。自然言語処理モデルの性能を測るためには、性能評価用の公開データセットを利用する必要があります。
例えば、読解問題のベンチマークとして一般的に使われる「Stanford Question Answering Dataset2.0」(SQuAD2.0)というデータセットを用いることで、読解問題に使用できる自然言語処理モデルの性能を評価する際の指標にすることができます。SQuAD2.0とは、Wikipedia記事に対して提起された質問と解答で構成された読解タスク集です。これを用いることで、読解問題に使用できる自然言語処理モデルの性能を評価することができます。SQuAD2.0のデータ形式を以下に示します。
Paragraph:
In meteorology, precipitation is any product of the condensation of atmospheric water vapor that falls under gravity.
The main forms of pre-cipitation include drizzle, rain, sleet, snow, graupel and hail...
Precipitation forms as smaller droplets coalesce via collision with other raindrops or ice crystals within a cloud.
Short, intense periods of rain in scattered locations are called “showers”.
Question1: What causes precipitation to fall?
Answer1: gravity
Question2: What is another main form of precipitation besides drizzle, rain, snow, sleet, and hail?
Answer2: graupel
Question3: Where do water droplets collide with ice crystals to form precipitation?
Answer3: within a cloud
気象学では、降水とは、重力の影響を受けて大気中の水蒸気が凝縮したものです。
降水の主な形態には、霧雨、雨、みぞれ、雪、あられ、ひょうなどがあります。
降水は、雲の中の他の雨滴や氷の結晶との衝突によって、小さな液滴が合体するときに形成されます。
点在する複数地点で起こる短時間の激しい雨は、「にわか雨」と呼ばれます。
降水が発生する原因は何ですか
重力
霧雨、雨、みぞれ、雪、ひょう以外の降水の主な形態は何ですか
あられ
水滴はどこで氷の結晶と衝突して降水を形成しますか
雲の中
SQuAD2.0を用いて性能を測定したところ、人間の正解率が86.831%に対して、Googleが開発した自然言語処理モデルである「ALBERT」を用いて同じタスクを解かせたところ、正解率が89.731%という人間を上回るスコアをたたき出しました。
また、大学入試センター試験で高得点をマークすることを目的とした「ロボットは東大に入れるのか」(通称、東ロボ)プロジェクトにおいて、2019年英語筆記本試験で200点満点中185点(偏差値64.1)と高い成績を残しています。
自然言語処理技術の発展によって、身の回りに存在するさまざまな自然言語処理タスクにおいて、人間よりも高い性能が出せるようになりました。そのため、今後よりいっそう自然言語処理技術の実用化が進むと予想されます。では、実際にどんなところで自然言語処理技術が利用されているかを、次の章で見てみましょう。
自然言語処理の活用事例
自然言語処理が世の中で使用されている例として、Google翻訳でその技術を活用している機械翻訳や、チャットツールを用いた自動応答システムでの利用を目的としたAIチャットbotが挙げられます。
筆者が所属するNTTテクノクロスでは、NTT研究所の音声認識技術やテキスト解析技術を活用しているコンタクトセンター向けソリューション「ForeSight Voice Mining」を提供しています。
ここで利用されている音声認識では、入力した音声の特徴量を得るために音響分析を行い、得られた音声の特徴量をテキストに変換します。そのテキスト変換には自然言語処理の技術が使われており、音声認識の精度に大きく影響します。チャットbotで広く知られるようになった音声認識にも、実は自然言語処理技術が深く関わっているのです。
コンピュータはどうやって言葉を認識するのか
人間は文章や単語の意味を理解する際に、しばしば会話の中から使い方を学んだり、辞書を引いたりすることでその意味を理解しています。コンピュータは会話をすることはなく、単語を一つも理解できないので辞書を読むこともできません。では、コンピュータはどうやって文章や単語の意味を理解しているのでしょうか。
単語のベクトル化
コンピュータが内部的に0と1の膨大な組み合わせで処理を行う計算機だということは、多くの方がご存じだと思います。テキストをコンピュータに入力する際、テキストのままだとコンピュータが計算する際に扱いにくいため、テキストをベクトル化(数値化)する必要があります。ここではベクトル化について簡単な例で紹介するために、ある4つの文書を用意します。
| 文書 | テキスト |
|---|---|
| D1 | Dogs are cute. |
| D2 | Cats are cute. |
| D3 | dogs are cool. |
| D4 | cats are cool. |
文書に含まれているテキストに対して、そのままベクトル化をすることも可能です。しかし、テキストに含まれる単語には冗長さが含まれているため、このままベクトル化するのは効率的ではありません。例えば、「Dogs」と「dogs」は同じ意味でも、単語表記(表層形)は異なります。また、句読点は文の区切りを表す記号であり、句読点自体は意味を持ちません。
そのため、効率的にテキストをベクトル化するためには、テキストに対して小文字化や句読点削除といった正規化処理を行う必要があります。先ほどの文書に含まれるテキストに正規化処理を行うと以下のようになります。
| 文書 | 正規化済みテキスト |
|---|---|
| D1 | dogs are cute |
| D2 | cats are cute |
| D3 | dogs are cool |
| D4 | cats are cool |
この全ての文書を使って作成されるコーパス(※)は、5つの単語(dogs、are、cute、cats、cool)から成り立ちます。この単語に対して0と1で構成されたIDを割り振ることで、コーパスに含まれる文章は5つの0と1の組み合わせ(5次元)で表現できます。例として、dogs=[10000]、is=[01000]、cute=[00100]、cats=[00010]、cool=[00001]と定義した場合は、以下の表のようにテキストがベクトル化されます。
(※)自然言語処理のモデル学習や評価などに使用される大規模なテキストデータ
| 文書 | ベクトル化テキスト |
|---|---|
| D1 | [[10000] [01000] [00100]] |
| D2 | [[00010] [01000] [00100]] |
| D3 | [[10000] [01000] [00001]] |
| D4 | [[00010] [01000] [00001]] |
テキストに含まれる単語をベクトル化することで、テキストを自然言語処理モデルで入力可能な情報として利用できるようになります。しかし、この意味のないIDを単語に割り当てる方法では、単語の区別ができるようになっただけで、単語の意味を表現できていません。そこで、次の章では単語の意味を含んだベクトルを作成するために、単語分散表現について解説します。
単語分散表現
先ほどの例では、単語をベクトル化してコンピュータが扱いやすいデータ形式に変換することができました。しかし、単語に意味のないIDを設定しただけでは、単語の意味を表現することは困難です。そこで、単語の意味をベクトル形式で表現するために、単語分散表現というものを利用します。
単語分散表現とは、分布類似度と分布仮説に基づいた、単語の意味を比較的低次元のベクトルで表現したものです。単語分散表現を用いることで、単語の意味を柔軟に表現することが可能になります。
では、なぜ単語分散表現を利用すると単語の意味をベクトル化できるのでしょうか。それについて説明するために、単語分断表現の根拠となっている分布類似度と分布仮説という2つの前提について説明します。
まず分布類似度とは、単語同士がどのくらい似ているかを表す数値です。では、その似ている度合いはどうやって定義しているのでしょうか。ここで重要になるのは、単語の意味が、その単語が出現する文脈から理解できるという考え方です。
「My daughter has a dog.」というテキストを例に解説します。このテキストの「has」という単語(以下、中心単語)を予測するには、中心単語の周辺にある単語(以下、周辺単語)を利用します。

ここでのhasは「持っている」ではなく「飼っている」という意味の方が、より文脈的に適切です。単語の意味は複数存在し、その意味は文脈によって相対的に決められるのです。
続いて分布仮説とは、似たような文脈に出現する単語は似たような意味を持つという仮説です。例えば「dogs are cute.」と「cats are cute.」での「dogs」と「cats」は、同じような文脈で使われるため、この2単語は分布仮説に基づくと、強い相関性があると見なせます。
この分布類似度と分布仮説に基づいて、大量のコーパスから単語分散表現を学習することで、各単語の意味を最もよく表現できている単語分散表現を獲得することができます。有名な例ですが、単語分散表現を用いることで以下の計算をすることが可能です。
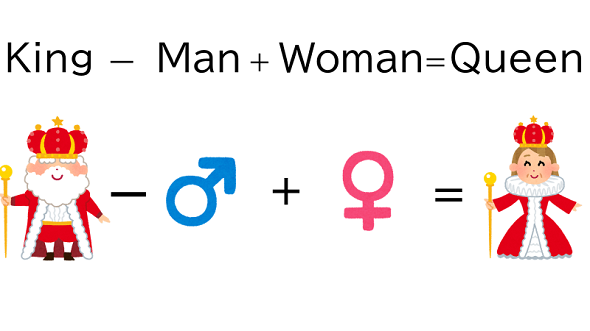
この例では、王様を表す「King」から男性のベクトル成分を引き、女性のベクトル成分を加えることで、女王を表す「Queen」の単語分散表現を計算しています。
これを数学的に解説するために、簡易的に二次元で表現した図を用いて説明します。「King」と「Queen」の関係性の違いは、「Man」と「Woman」の関係性の違いと同じもの(性別という違いによって区別されている点で同じ)です。この単語同士の関係性は、図のベクトルの「向き」で表現されており、実際に2本の矢印は同じ方向を向いています。
この関係性を数式にすると以下の式で表すことができます。

また、上記の式を変形すると以下の形になります。
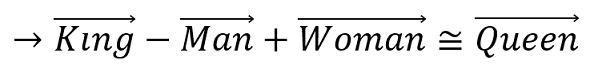
つまり、最初の例は直感的にも正しいだけでなく、きちんと数学的に正しい計算だったのです。

まとめると、単語分散表現とは、分布類似度と分布仮説に基づいた、単語の意味を効率的にベクトルで表現したものです。単語分散表現を用いることで、単語の意味を柔軟に表現することが可能になります。
文書間距離を用いたセンター試験における未知語語義推定問題
単語分散表現を用いることで、単語の意味を表現することができました。単語分散表現を利用することで、さまざまな自然言語処理モデルが開発されています。本章ではシンプルに単語分散表現のみを使ってセンター試験問題の未知語語義推定問題を解く方法を紹介します。
未知語語義推定問題とは、問題文、解答指示文、選択肢から構成されています。例として2013年度センター試験英語(筆記)本試験大問3Aの問2を以下に示します。

この問題では、問題文中の単語「epitome」に線が引かれています。下線部は大学受験生の語彙(ごい)レベルを大きく超えているため、受験生は問題文全体と選択肢からその単語を推測して解答することになります。
今回は、この問題を先ほどの単語分散表現を用いて解答する手法を紹介します。
具体的には、単語分散表現を用いて、下線部の単語と選択肢の内積を計算し、最も類似度が高いものを正解として選択します。どうしてこんな計算が可能になるかというと、単語分散表現が分布仮説に基づいているからです。イメージを付けるために単語分散表現を用いた内積の計算例を以下に示します。

この手法では、下線部の単語と選択肢が似た意味ならば、近しいベクトル空間に配置されているため、類似度が高くなるという根拠に基づいています。
もちろん、この手法でもある程度は解けるのですが、それはあくまで本来知らないはずの下線部の単語をコンピュータが知っていることが前提であり、コンピュータにとって有利のカンニング的手法といえます。また、下線部の単語と選択肢以外の情報は学習していないため、もし問題文に答え、または答えのヒントがある場合はこの手法では解くことが難しいのです。
単語分散表現のみを使って解けるのは、該当の単語および短い文章を読めば解けるような簡単な問題である場合が多いです。一方、文章全体を読んで解答するような問題は、文脈との関係を理解する必要があるため、コンピュータにとって難易度の高い問題といえます。そのため、単語同士や文脈の関係性についても学習して文章の意味を理解させる必要があります。次回は、単語間の関係性を学習させる自然言語処理における代表的なモデルについて解説します。
関連リンク
SQuAD2.0 - SQuAD - the Stanford Question Answering Dataset
著者紹介
河田 尚孝(カワタ ナオタカ)

ソフトウェア開発企業のNTTテクノクロスで、深層学習モデルを用いた新規ソリューションの検討・開発業務に従事。
NTTテクノクロスは音声認識および自然言語処理技術を用いた製品である「ForeSight Voice Mining」を提供しており、筆者自身も音声音響・画像映像・自然言語といったマルチメディアを統合的に扱いより高度な推論を実現する次世代メディア処理AIを搭載した「SpeechRec」の開発業務に取り組んでいる。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。