高負荷なのに片方のサーバにだけ余裕が……なぜ?:Linuxトラブルシューティング探偵団(1)(1/4 ページ)
NTTグループの各社で鳴らした俺たちLinuxトラブルシューティング探偵団は、各社で培ったOSS関連技術を手に、NTT OSSセンタに集められた。普段は基本的にNTTグループのみを相手に活動しているが、それだけで終わる俺たちじゃあない。今回からOSSを扱ってきて遭遇したトラブルを解決する過程を@ITで連載していくぜ。
ソースコードさえあればどんなトラブルでも解決する命知らず、不可能を可能にし、多くのバグを粉砕する、俺たちLinuxトラブルシューティング探偵団! 助けを借りたいときは、いつでもいってくれ!
OS:高田哲生
俺はリーダー、高田哲生。Linuxの達人。俺のようにソースコードレベルでOSを理解している人間でなければ、百戦錬磨のLinuxトラブルシューティング探偵団のリーダーは務まらん。
Web:福山義仁
俺は、福山義仁。Web技術の達人さ。ApacheのようなWebサーバからTomcat、JBossみたいなJava、アプリケーション技術まで、何でも問題を解決してみせるぜ。
DBMS:下垣徹
下垣徹。PostgreSQLの達人だ。開発からサポートまで何でもやってみせらぁ。でも某商用DBMSだけは勘弁な。
HA:田中 崇幸
よぉ! お待ちどう。俺さまこそHAエキスパート。Heartbeatを使ってクラスタを構成する腕は天下一品! HAが好きなんて奇人? 変人? だから何? HaHaHaHa!!
まずは手始めに、Webの達人、福山義仁が遭遇したトラブルを紹介するぜ! 最後まで読んで、ぜひ参考にしてくれ!
性能検証中に生じた「とある」トラブル
……というわけでこれから4回に分けて、Linuxをプラットフォームに、オープンソースソフトウェアを組み合わせて構築したシステムでよく突き当たるトラブルの症例とその解決プロセスを、NTT OSSセンタでの事例を基に紹介していきます。
最初に取り上げるトラブル例は、Webアプリケーションサーバでの問題です。Webサーバ「Apache」とアプリケーションサーバ「Tomcat」の間をつなぐモジュール「mod_jk」は、アプリケーションサーバに対して負荷分散(ロードバランス)を行う機能を備えています。しかし、筆者が経験したとある性能検証で、この負荷分散機能の振り分け方法が原因となり、2つのアプリケーションサーバ間で負荷のバランスがうまく取れないという事象に遭遇しました。
今回はこの事象を解析し、どのように解決したのかを説明していきたいと思います。
関連記事
- Webアプリの問題点を「見える化」する7つ道具(@IT Java Solution)
http://www.atmarkit.co.jp/fjava/rensai4/troublehacks01/troublehacks01_1.html - 肥え続けるTomcatと胃を痛めるトラブルハッカー(@IT Java Solution)
http://www.atmarkit.co.jp/fjava/rensai4/troublehacks08/troublehacks08_1.html - 低負荷なのにCPU使用率が100%?(@IT Java Solution)
http://www.atmarkit.co.jp/fjava/rensai2/webopt07/webopt07.html
同じシステム構成なのにCPU負荷に差が
このシステムは大規模なものだったため、クライアント数を徐々に増やし、高い負荷を掛けて検証を進めました。クライアント数を1万5000にまで増やしたところ、一見正常に動作するように見えながら、よくよく確認すると、エラーは出ていないものの、2つのアプリケーションサーバでCPU使用率に差が生じる結果になりました。
詳細に見ると、1万3000クライアントを超えたあたりから徐々に差が出ていることが見て取れます。これは1万3500クライアントの時点で約3%に広がり、限界性能である1万5000クライアント以降ではその差はさらに大きくなり、約15%の偏りが発生していました。
負荷分散をしているのにCPU使用率が偏ってしまっているということは、仮に今後アプリケーションサーバに非常に高い負荷が掛かるような状況になったとき、せっかく2台用意したアプリケーションサーバの能力を生かし切れないということを意味しています。
さて、この偏りはなぜ起こったのでしょうか? そして、偏りが起こらないようにするには、どのように対処したらよいのでしょうか? 以下、実際に調査した内容を基に説明していきましょう。
■標準的な構成でなぜか問題発生
この環境では、以下のソフトウェアを組み合わせ、標準的なWeb3層モデルを利用していました。
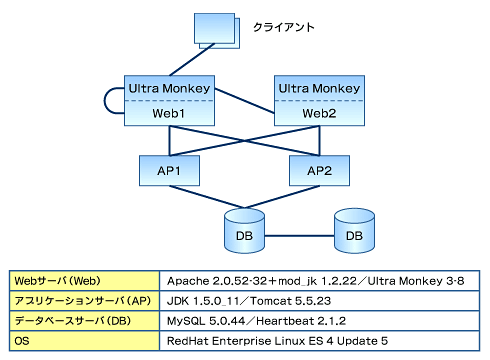 図1 テスト環境
図1 テスト環境この環境では、以下のような仕組みで冗長化を施しています。まず、Ultra Monkey(http://ultramonkey.jp/)がリクエストを振り分け、Webサーバの負荷分散を行っています。仮に片方のWebサーバがダウンしても、もう片方のWebサーバでサービスを継続することができます。
またそれぞれのWebサーバでは、mod_jkがアプリケーションサーバに対する負荷分散を行い、リクエストを振り分けます。ここでも、もしアプリケーションサーバがダウンしても、生きている方のアプリケーションサーバを利用してサービスを継続します。
さらに、データベースサーバがダウンした場合は、Heartbeat(注1)がアクティブ/スタンバイを切り替え、フェイルオーバーします。
注1:Heartbeat:HA(高可用性)クラスタを実現するための、オープンソースソフトウェアです。http://www.atmarkit.co.jp/flinux/index/indexfiles/heartbeatindex.htmlを参照。
■性能検証に利用できるツール
性能検証には、今回の検証用に作成したベンチマーク「TPC-W」(注2)を用います。負荷をかけるTPC-Wクライアントの実行制御に、オープンソースの「Apache JMeter」(http://jakarta.apache.org/jmeter/)を利用しました。
検証は、クライアント数1万3000から始まり、1万6000クライアントまで増加させました。各クライアントは、それぞれ平均7秒ごとにリクエストを送信するように設定しています。検証時間は40分で、これに加えてランプアップ(すべてのクライアントが立ち上がり、アクセスが平均化するまで)に要する20分を加えた計60分で行いました。
前述したとおり、7秒の思考遅延(連続したリクエストの間で発生する待機時間)があるので、それぞれの同時アクセス数は1857〜2286になります。この結果をWIPS(注3)で見ると、目標どおりの性能が出ている状態でした。
|
注2:TPC-W:TPC(Transaction Processing Performance Council)にて規定しているWebシステムベンチマーク標準です。http://www.tpc.org/tpcw/を参照。
注3:WIPS:Web Interaction Per Second。処理性能を示す指標の1つで、1秒間のWebインタラクション数を表します。
トラブル原因切り分けのステップ
この状況で、負荷の偏りの原因として考えられる要因はいくつかありました。
- mod_jkのロードバランスが設定どおりに行われていない
- ガベージコレクション(GC、後述)が発生してCPUに負荷が掛かっている
- Tomcat上で処理待ちのスレッドが発生して全体のパフォーマンスに影響を与えている
これらを確かめるために、「アクセスログの確認」「jstatによるGCの状況の確認」「スレッドダンプの取得」と順を追って追求してみましょう。
今回は性能検証なので、ログをはじめとする各種基本データは収集済みでした。収集した主な基本データは以下のようになります(サーバとクライアント共通)。
- CPU情報(user、sys、iowait)
- ContextSwitch情報
- Memory情報(free,userd,cached,swapused)
- Swap情報
- Network情報(NICごと)
- procs情報
- IO情報
アプリケーションサーバではさらに、以下のような情報を取得しています。
- jstat情報(GC情報、HeapMemory情報)
- Tomcat Resource情報(ResponseTime、Thread pool情報)
(他サーバについては割愛)
これらを詳しく調査することで、原因の切り分けを行っていきます。
■ThreadBusyの数に差が!
収集したデータの1つが、ThreadBusyであるスレッド数のグラフです。ThreadBusyとは、実際にTomcatがリクエストを受け付けて、処理中のスレッドのことを指します。
このグラフが示す数値が、「AP1」と「AP2」で大きく異なっていました。AP1では、maxThreadsの設定の限界である2000まで使用しているのに対し、AP2ではそこまで至らず、平均700程度にとどまっていました。
どうやらこれが原因のようですが、実際のところ、なぜThreadBusyのスレッド数に差が出てしまうのかが問題です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。