XML文書の基本構造を詳しく見ていく:技術者のためのXML再入門(4)
今回からいよいよXML 1.0の文法を解説し、実際のXMLデータを作成する方法について解説していこう。XMLデータはXML宣言やDTD、XML本体などの複数の部分からなり、タグ名に使える文字なども決められている。さらに、XML文書を構成する要素の入れ子構造や、整形式XML文書など、XML文法の具体的な姿を詳しく見ていく。
本連載のこれまでの回では、XMLが注目される理由と、XMLを実際に動かすための関連技術について述べて、XMLを概観してきた。今回からはいよいよ本連載の本論に入る。まず、今回と次回は、W3C勧告となっているXML 1.0の文法規則を解説して、実際のXMLデータを作成する方法を学ぶことにする。なお、ここではW3CのXML規格書に基づいて解説を進めるので、XMLデータのことを、規格書の用語に合わせてXML文書と呼ぶことにする。また、XML規格書はDTDを使って規格を説明しているので、この記事もそれに倣う。ほかのスキーマ言語を使いたい読者は、DTDを別のスキーマ言語に置き換えながら読み進んでいただきたい。
XML文書の基本的な構成
まず、XML文書の基本的な構成から話を始めよう。以下のサンプルコードをご覧いただきたい。
 リスト1 XML文書の基本構成
リスト1 XML文書の基本構成リスト1から分かるとおり、XML文書は次の3つから構成されている。
- XML宣言
- DTD
- XML本体
XML文書の冒頭に現れるのがXML宣言(XML declaration)だ。XML宣言は、そのXML文書が準拠するXML規格のバージョンや使用する文字コードなどを宣言する。XML宣言は省略可能だ。
DTDは、XML文書のデータ構造をDTD文法に従って記述する。DTDは、リスト1のようにXML文書の中に含めてもよいし、外部ファイルにしておいて、XML文書の中から参照してもよい。DTDも省略可能だ。
タグ付けされた実際のデータは、XML文書の本体の部分に記述される。XMLの本体の部分には、少なくとも1つの要素が存在しなければならない。つまり、XMLの本体は省略できない。
整形式XML文書と検証済みXML文書
前項で述べたとおり、XML文書にDTDはなくてもよい。これは、DTDがあってもなくても、少なくともXMLの文法に従っていればXML文書と呼べるということだ。そうしたXML文書を整形式XML文書(well-formed XML document)と呼ぶ。
一方、XMLの文法に従うだけでなく、そのXML文書に関連付けられたDTDが定義するデータ構造にも従うXML文書を、検証済みXML文書(valid XML document:JIS規格では「妥当なXML文書」と呼んでいる)と呼ぶ。検証済みXML文書は、DTDとの照合チェックにも完全にパスする整形式XML文書といい換えることができる。
検証プロセッサと非検証プロセッサ
XML文書の構文解析を行うのはXMLプロセッサだ。特に、整形式XML文書かどうかだけをチェックするXMLプロセッサを非検証プロセッサ(non-validating XML processor)という。それに加えて、検証済みXML文書かどうかまでチェックするものを検証XMLプロセッサ(validating XML processor)という。もっとも実際のXMLプロセッサは、設定のオン/オフの切り替えによって、非検証XMLプロセッサとして使ったり、検証XMLプロセッサとして使ったりするのが普通だろう。
XMLの入門書を読まれた方や、XML入門セミナーを受講された方は、これらの言葉にすでになじみがあるだろう。そうした方々にも注意を促しておきたい点は、「非検証プロセッサであってもDTDを参照することがある」という点だ。
例えば、非検証プロセッサであっても、XML文書の解析中にDTDで定義されたデータをインクルードするよう指定された個所(後述するエンティティ参照)を見つけると、非検証プロセッサはそのDTDを見て、インクルードすべきデータもXML文法に適合しているかどうかをチェックする。さらに、DTDの中に属性を宣言した部分があると、非検証プロセッサは、XML文書内の属性にデフォルト値を設定したり、余分な空白を削除するといった属性値の正規化を行う。
非検証プロセッサとして整形式のチェックだけをしたつもりだったのに、DTDがらみの思わぬエラーが出たときには、上記のことを思い出していただきたい。
整形式XML文書の作成の仕方
では、以下にXML文法で出てくる用語や、XML文法の定めるタグ付けのルールを説明して、整形式XML文書の作成の仕方を示そう。リスト1で示したXMLの本体部分のデータ構造を図示すると、図1のようになる。
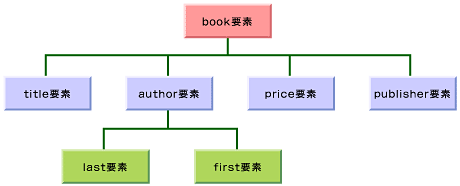 図1 リスト1に示したXML文書のデータ構造
図1 リスト1に示したXML文書のデータ構造XMLのデータモデルでは、XML文書をツリー構造としてとらえる。そして、ツリー全体を文書(document)、また本連載の第1回「XMLの注目される特徴とは何か」で述べたとおり、文書を構成する基本的なパーツを要素(element)と呼ぶ。図1では、title要素やauthor要素、last要素などが、ツリーを構成する個々のノードになっている。
これらの要素の関係は、親子関係になぞらえて呼ばれる。例えば、book要素は、title要素・author要素・price要素・publisher要素の「親要素」である、という。また、last要素・first要素は、author要素の「子要素」である、という。
XMLツリーのルート要素
特に、ツリーの最上位の要素(図1ではbook要素)をルート(root)、または文書要素(document element)という。整形式XML文書では、必ずルートは1つでなければならない。
ここでもう一つ注意しておきたいことがある。XMLツリーの特定の個所を指定する規格にXPathがあるが、そのデータモデルでは最上位要素のもう一つ上に文書全体を表現するノードがあると考え、それをルートノード(root node)と呼ぶ。また、XMLのAPI規格であるDOMのデータモデルでも、最上位要素に同様な親ノードがあると考え、それを文書オブジェクト(document object)と呼ぶ。単にルートというと、最上位要素のことを言っているのか、最上位要素の親ノードのことを言っているのか分かりにくい。そこで、XMLのデータモデルで考えるときには、最上位要素を「ルート要素」と呼ぶことによって、ルートノードや文書オブジェクトとの混同を避ける人もいる。
要素の表現の仕方
XMLは、開始タグと終了タグで要素の内容データを挟み込むことによって要素を表現する。HTMLやSGMLとは異なり、XMLでは終了タグの省略はできない。また、XMLは、タグ付けされた要素を入れ子構造で記述することによって、要素の包含関係を表現する。以下に正しい例と正しくない例を示す。
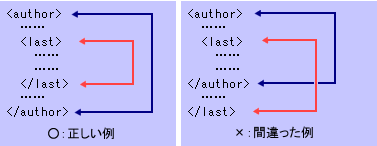 図2 入れ子構造になる例と、入れ子構造が崩れた例
図2 入れ子構造になる例と、入れ子構造が崩れた例ルート要素は最上位の要素なので、それ以外の要素はルート要素の開始タグと終了タグの間に挟み込まれることになる。
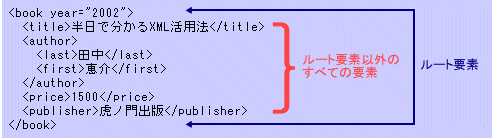 図3 ルート要素以外の要素は、ルート要素に包含される
図3 ルート要素以外の要素は、ルート要素に包含されるXMLデータの作成に慣れない人がよく犯すミスは、終了タグの付け忘れなどで、開始タグと終了タグが対応していないタグ付けを行ってしまうことだ。タグ付け作業に当たっては、この点を注意されたい。XML対応のエディタを使うのも、ミスを防ぐ方法の1つだ。
属性の表現の仕方
ある要素の特性や性質は、属性(attribute)として表現する。リスト2の場合、book要素がyear属性を持ち、その属性値は“2002”になっている。
<book year="2002">
要素は、複数の属性を持つことができるが、同じ属性を重複して指定できない。
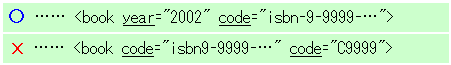 リスト3 同じ属性値は重複できない
リスト3 同じ属性値は重複できない要素で表現するか、属性で表現するか
要素の特性や性質は属性で表現すると述べたが、何を特性や性質とするかを決める絶対的な基準はない。例えば、リスト2のbook要素は、year(書籍の発行年)という情報を属性としてではなく子要素として表現してもよい。
<book> <year>2002</year> …… </book>
少なくとも、さらに下位構造に展開できそうな情報は、属性としてではなく子要素にした方がよいだろう。例えば次のようにしても文法的には間違いではない。
<book author="田中恵介">
しかし、著者名author要素は、将来、姓と名前に分けて管理したいときがくるかもしれないので、次のように表現してもよいだろう。
<book> <author>田中恵介</author> </book>
空要素
要素によっては、開始タグと終了タグに挟み込まれる内容がないものもある。それを空要素(empty element)と呼ぶ。空要素は、次のように記述できる。
<image></image>
あるいは、次のように簡略にした記述もできる。
<image/>
エンティティ参照と文字参照
XML文書内で何度も出てくる文字列は、変数として記述しておき、後から一括して変換する方がよい。また、大きな文書を手分けして作成する場合、章ごとに別々のXML文書にしておき、メインのXML文書がそれらを参照できれば便利だ。XMLでは、XML文書の一部になり得るデータをエンティティ(entity:実体)と呼ぶ。
エンティティは、別ファイルのXML文書であったり、DTDの中で宣言された文字列であったり、イメージデータファイルであったりする。XML形式で記述されていてXMLプロセッサの構文解析の対象になるようなエンティティは、解析対象エンティティという。章ごとに別ファイルに分けられたXML文書などがそれに当たる。一方、イメージデータのようにXMLプロセッサが手を加えないままアプリケーションに渡されるエンティティを、解析対象外エンティティという。
XML文書において、エンティティ参照はエンティティ名を“&”と“;”で囲んで記述する。例えば、“w3c”という名前のエンティティの内容が“World Wide Web Consortium”という文字列だったとすると、XMLプロセッサは、以下のように処理する。

あらかじめ定義されているエンティティ
あるエンティティ名がどんな内容を参照するかを定義するエンティティ宣言は、DTDで行う。ただし、次の表に示すエンティティはDTDで宣言しなくても使用できる。
| エンティティ名 | 内容 |
|---|---|
| lt | < |
| gt | > |
| amp | & |
| apos | ' |
| quot | " |
| 表1 あらかじめ定義されているエンティティ | |
要素の内容の中で記号“<”を使ってしまうと、XMLプロセッサはそれを要素の始まりと誤解してしまう。これを避けるため、エンティティ参照を使って以下のように記述する。
<p><という文字は記述の仕方で工夫が必要です。</p>
XMLプロセッサは、<という部分を“<”に相当する文字コードに置き換えて処理する。従って、XMLプロセッサからアプリケーションに渡される要素の内容は、「<という文字は記述の仕方で工夫が必要です。」になる。
文字参照
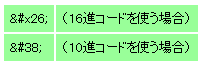
XMLでは、文字のコード番号を使って記述する文字参照(character reference)という方法も用意されている。ただし、同じ文字でも文字コードによってコード番号が異なる。そこで、文字参照に使う文字コードとしてISO/IE C10646を使うことになっている。“&”という文字を文字参照を使って記述すると、以下のようになる。
名前の付け方のルール
XMLではタグ名やエンティティ名を自由に決められるが、名前に使える文字や名前の先頭で使える文字には決まりがある。命名ルールを要領良くまとめた表を、筆者の同僚が書いた書籍『お気楽Q&A XML』(おおたじゅん著、IDGジャパン刊)から引用する。
| 先頭の文字 | Letterクラスの文字 _ (アンダースコア) :(コロン) |
|---|---|
| 2番目以降の文字 | Letterクラスの文字 Digitクラスの文字 Combining Characterクラスの文字 Extenderクラスの文字 _ (アンダースコア) :(コロン) . (ピリオド) - (ハイフン) |
| 表2 XMLで名前として使用できる文字 | |
上の表にでてくるLetterクラスなど、文字クラスの説明を表3に示す。
| Letterクラス | アルファベット、ひらがな、カタカナ、漢字 |
|---|---|
| Digitクラス | 数字 |
| Combining Characterクラス | アクセント記号など |
| Extenderクラス | 々、ー(カタカナの長音記号) |
| 表3 名前として使用できる文字クラスとそれに含まれる主な文字 | |
これらに従って、XMLで有効な名前の例を以下に示す。
この表を見ても分かるのとおり、XMLは名前に漢字を使ってよい。ただし、半角カタカナと全角数字は使えないことは覚えておいてほしい。また、“:”(コロン)も使えることになっているが、実際には、複数のDTDを使用できるようにする名前空間という手法でコロンを使用することになっているため、名前にコロンを含めるべきではない。
大文字と小文字を区別する
HTMLでは、タグ名やHTMLのキーワードは、大文字・小文字の別を気にせずに使うことができた。しかし、XMLでは、タグやエンティティなどの名前やキーワードを使用するに当たり、大文字・小文字を厳密に区別する必要がある。例えば、XMLプロセッサは、以下の要素を文法エラーにする。同じスペルであっても、開始タグ名は小文字で、終了タグ名は大文字で書かれているため、XMLプロセッサはタグ名が異なると判断するからだ。
<title>Digital Xpress</TITLE>
XML規格が定めているキーワードも厳密に大文字・小文字の区別をつけなければならない。XML文書の冒頭に出現するXML宣言がその例だ。

XML文書を作成するに当たり、XML規格書やXML解説書がキーワードを大文字で書いているか小文字で書いているかよく見て、そのとおりに書くようにしたい。
名前の先頭に“xml”という文字列がきてはいけない
XML文書で名前を使うに当たり、もう一つ注意すべき点は、“xml”が先頭にくる名前は予約されているということだ。これは、大文字であっても小文字であっても、“xml”で始まる要素名や属性名やほかの名前をユーザーが決めてはならないということだ。以下に、使ってはならない要素名の例を挙げる。

コメントとCDATAセクション
XML文書の中で、XMLプロセッサに解析させたくないところは、コメント(comment)またはCDATAセクション(CDATA section)にする。XMLのコメントは以下のように記述する。ただし、コメント文の中で「--」という文字列を入れてはならない。
<!-- ここはコメント文です。 -->
XMLプロセッサが、コメントの内容をアプリケーションに渡すかどうかは実装依存だ。一方、XMLのタグとして認識させたくないが、内容を確実にアプリケーションに渡したい場合、CDATAセクションを使うとよい。
<![CDATA[<p>この部分はタグと見なさないでください。</p>]]>
処理命令
XML文書の中にアプリケーションのための命令を入れたい場合、処理命令(processing instruction)を使う。例えば、ブラウザに改行を指示したい場合は、次のような記述になるだろう。
<?browser break ?>
XML規格のバージョンの宣言
XML宣言(XML declaration)は、XML文書の先頭に記述し、そのXML文書がどのバージョンのXML規格に従って記述されているかを宣言する。
<?xml version="1.0"?>
XML宣言において、“?”と“xml”の間に空白を入れてはならない。また、versionの宣言は省略できない。XML宣言には、versionの宣言以外に後述するencoding宣言とstandalone宣言を書けるが、versionの宣言は常に先頭にくる。
現在、W3Cの勧告になっているXML規格のバージョンは“1.0”だけだ。2001年12月にXMLのバージョン1.1(Blueberryという開発コード名がつけられた要求仕様に基づくXML文法)がW3Cから公開されたが、これはまだドラフトの段階だ。現時点において、実務で使うシステムはバージョン1.0のXMLを使うと考えてよいだろう。
XML文書の文字コードの宣言
XML宣言には、さらに符号化宣言(encoding declaration)を付け加えることがある。
<?xml version="1.0" encoding="shift_jis"?>
この宣言によって、XML文書がどんな文字コードを使って記述されているかを宣言する。上の例では、シフトJISを使用すると宣言している。文字コード名は、IANA(Internet Assigned Numbers Authority)で登録された名前を使うことになっている。IANAの文字コード名は、大文字・小文字の区別をしていないので、符号化宣言においても、コード名は大文字・小文字の別を問わない。

XML規格は、文字コード名としてIANAで登録される名前を使うといっているだけであり、それらをすべてサポートすると保証しているわけはないことを覚えておきたい。XML規格がXMLプロセッサに義務付けているのは、UTF-8とUTF-16のサポートだけだ。従って、シフトJISなどを使いたい場合、その文字コード体系をサポートしているかどうかXMLプロセッサの仕様を確認する必要がある。
encoding宣言が省略された場合、デフォルトは“UTF-8”または“UTF-16”だ。UTF-16で記述されたファイルの先頭(Byte Order Markという)は、必ずx'FEFF'となる。encoding宣言が省略されたとき、XMLプロセッサは、ファイルの先頭を見てUTF-8とUTF-16の区別を自動的に行う。
いうまでもないことだが、作成したXMLデータは、符号化宣言で指定した文字コードで保存しなければならない。また、encoding宣言を省略したなら、UTF-8またはUTF-16で保存しなければならない。
XMLを勉強している人が初めてXML文書を作成したときに犯しやすいミスだが、符号化宣言が省略されたXML文書を、シフトJISとかEUC-JPなど、自分の利用する環境で普通に使われる文字コードでファイルに保存する人がいる。そうすると、そのXML文書を処理するXMLプロセッサは、デフォルトであるUTF-8の文字コードが使用されているとみなして解析を始めるものの、XML宣言に続く最初の文字が理解できないため、いきなりエラーを出して終了することになる。読者の中でこうした失敗のある方はほとんどいないかもしれないが、念のため申し添える。
外部DTDの参照が必要かどうかの宣言
XML文書の中で属性のない要素として出現しているのに、実はその要素は、外部ファイルとして存在しているDTDの中で、デフォルト値付き属性を持つ要素として宣言されていることがある。この場合のように、XMLプロセッサからアプリケーションに渡されるXML文書の内容に違いを生じさせる情報が、XML文書の外部に存在するDTDに出現することがある。
あるXML文書に、そうした違いを生じさせる外部のDTDがあるかどうかを示す宣言をスタンドアロン文書宣言(standalone document declaration)と呼び、XML宣言の中に加えることができる。 スタンドアロン文書宣言を“yes”と宣言した場合、上で説明したような情報が存在する外部ファイルとしてのDTDはない、と宣言することになる。
<?xml version="1.0" standalone="yes" ?>
以下のXML宣言のようにスタンドアロン文書宣言が省略された場合、XMLプロセッサはスタンドアロン文書宣言が“no”と宣言されたとみなす。
<?xml version="1.0" ?>
ここで誤解してはならないのは、スタンドアロン文書宣言が外部のDTDを読み込むかどうかをXMLプロセッサに指示しているとは限らない点だ。例えば、検証XMLプロセッサは、XML文書の外部・内部を問わず、参照されているすべてのDTDを読み込んで、XML文書の妥当性をチェックする。これは、スタンドアロン文書宣言に関わりなく、検証XMLプロセッサが必ず行う処理だ。また、XML規格書によれば、非検証プロセッサは、XML文書の内部に存在するDTDを見ることまでは決められているが、外部に存在するDTDについては読んでも読まなくてもよいことになっている。どうするかは実装の問題だ。
では、スタンドアロン文書宣言は、どんな役に立つのか? 以下のことが考えられる。 まず、スタンドアロン文書宣言が“no”になっているXML文書を非検証プロセッサで処理する場合、非検証プロセッサからアプリケーションに渡されるXML文書を作成者の意図通りに解釈するためには、外部のDTDを読む込む機能を実装した非検証XMLプロセッサを使用すべきだと分かる。また、スタンドアロン文書宣言に“yes”と明示的に記述することによって、そのXML文書の作成者は、外部のDTDを参照しなくても作成者の意図通りに解釈できることを明示的に保証していると分かる。そうしたものを示すための宣言だといえる。
次回で扱う内容
今回は、整形式XML文書を作成するために必要なXMLの文法を、ポイントを絞って解説した。次回は、スキーマ記述言語としてこれまでよく使われてきたDTDの基本的な書き方を説明する。
更新履歴
- 2002/1/17 「外部DTDの参照が必要かどうかの宣言」の節の内容を変更しました
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。