Loading
|
@IT|@IT自分戦略研究所|QA@IT|イベントカレンダー+ログ | |
|
Loading
|
| @IT > SPSS事例探求 第3回 慶應SFC編 |
| |
|
|
|
|
慶応義塾大学湘南藤沢キャンパス(以下、慶應SFC)では、2001年度後期(2001年9月〜2002年3月)から、SPSSの「Clementine 6.0」を使用したデータマイニングの講義を開始した。今回は、データマイニングの後期クラス(半期終了、全13回)が終了したばかりの担当教授、桑原 武夫氏(慶應義塾大学総合政策学部助教授)に、講義の内容や学生の反応、今後の課題について話をお聞きした。また、データマイニングの演習パートにおいて「Clementine」の操作指導を担当した、荒 和志氏(エス・ピー・エス・エス株式会社 ビジネスインテリジェンス事業部 プロフェッショナルサービスグループ セールスエンジニアマネージャ)にも操作指導を行った立場からの感想を伺った。
桑原氏がデータマイニングに取り組むきっかけとなったのは、驚くことに、ある学生からの熱心な提案だったという。 桑原氏の専門は「消費者研究」であり、多変量解析などの高度な統計解析手法を用いたデータ分析は最も得意とするところ。しかし当時は、「データマイニング? なにそれ……」と答えるほど、データマイニングに対する関心は低かったそうだ。 しかし、学生の粘り強い提案によって、ついには桑原氏自身、データマイニングの可能性に目覚め、ようやく2001年後期、「Clementine 6.0」を用いたデータマイニングのクラスを開講するに至ったという。 桑原氏の言葉によれば、「福沢諭吉先生に“半学半教”という言葉があります。これは教える者と学ぶ者という立場に徹することなく、互いに教え合い、学び合うという精神を説いているのですが、まさに“データマイニング”については、私が学生から教えてもらったというわけです」ということらしい。 実際に行われたカリキュラムは以下の通り。簡単に内容を紹介しておこう。
この講義は、データ分析に関して、ある一定以上の知識を有する学生のみに受講を許可しているそうだが、30名の応募者に対し、実際に受講を許されたのは20名ほどだという。データマイニングに対する興味・関心の高さと実際にそのための知識を有しているかどうかというところには、まだ少なからずギャップはあるようだ。 第1〜3回目までで、「Clementine」のセットアップと基本的な操作方法について学ぶ。SPSSでは、初学者のために「SPSSファーストキット」を用意しており、このキットを用いながら、基本操作方法を分かりやすく習得していくことができる。 第5回で、データマイニングの根底にある考え方を「KDD」(Knowledge Discovery and Data)概論という形で整理した後、第7〜12回で、実際のデータマイニングの4つのテクニックの講義と実習を行っている。各テクニックとも講義と演習が必ずペアになっているが、これは「学ぶ」(インプット)だけでなく、同時に「実践してみる」(アウトプット)という学習効果を狙ったものだそうだ。さらに、演習後のレポート作成(全4回)も課せられており、学生にとってはかなりハードなクラスだったようだ。
当初、基本的な統計解析を学ぶのがやっとの学生にとっては、データマイニングは“とても難しい、とっつきにくいもの”という印象があったようだ。しかし、今回の講義を終了した学生たちは、この講義を通じ、「データマイニングをとても身近に感じることができるようになった」という。「Clementine 6.0」では、自分がやりたい分析手順をビジュアルなモデルとして作成し、さまざまな分析テクニックを平易な操作で実行することができる。
桑原氏は「昨年の講義では、データマイニングの全体像を理解させ、“Clementine 6.0”を使うとおおよそどんなことができるのかを理解させるのが狙いでした。実際のところ“Clementine 6.0”は、データマイニングを行っていくうえで、いきなり難しい操作を覚える必要がなく、まずは必要最低限の操作から始めることができます。実際に目で見て仕組みを理解し、実際に触ってみて操作を覚える。それが1つできたら次のステップへと進む、という使い方ができるわけです。だからこそ、学生たちもデータマイニングに自信を持てるようになったのでしょう」と、初講義を終えた感想を述べている。 2002年度の前期クラスから、「非常勤講師」としてレクチャーの実習部分の講義を受け持つことが決定しているSPSSの荒氏は、桑原教授の講義に毎回同席し、「Clementine」の操作指導を行うなど、データマイニングの実習に取り組んでいる学生たちの姿を間近に見ており、「Clementine 6.0」の評判が良かったことにうれしさを隠し切れない様子だ。
桑原氏に今後の課題を伺ってみた。
実際にデータマイニングを行っている企業では、数十万、数百万件単位の大量データの分析をすることも珍しくはないだろう。しかし、慶應SFCのような教育の現場では、実際の企業のデータを入手することは当然不可能であり、似たようなサンプルデータを作成するしかない。だが、いかにも現実のビジネスで扱われるような質とボリュームをもつサンプルデータを作成するのはそう簡単なことではないらしい。
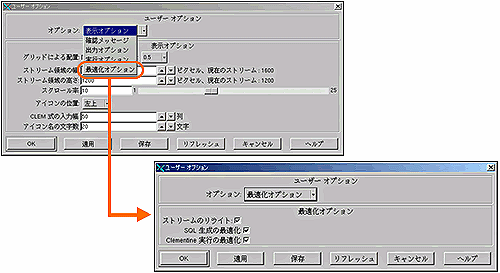
大量のデータを扱う場合には、当然のことながら分析処理スピードの低下が気になるところだが、2002年1月に登場した「Clementine 6.5」では、パフォーマンスの改善が実現されており、分析処理能力の向上が実現されている。つまり、より多くの操作処理をデータベースに戻すことで、スケーラビリティの向上が図られているということだ。具体的には、ストリーム実行中に、バックグラウンドで行われる高性能なノードの並べ替えを行うことで実現している(画面1)。 非常勤講師として、今後はさらに慶應SFCでのデータマイニング講座へのコミットメントを約束している荒氏は、
*注) ゴミデータの削除や分析の目的に応じて合成変数を作成するといったこと。合成変数の作成とは、例えば、売上金額と販売数のデータから、計算式を組んで「販売単価」という新しい変数を生み出すといったことを意味する と、今後はさらに実務レベルに近い、データの収集〜加工〜分析〜活用という分析サイクルにまで踏み込む講義内容を実現できるようサポートしていきたいとの意気込みを示してくれた。
産学協業のモデルの1つに、インターネットの世界で第一人者として知られる慶應義塾大学環境情報学部教授、村井 純氏が会長を努める「インターネットノード株式会社」がある。これは、IPv6技術とデバイスとしてマイクロノードを用いて、来るべきIPv6時代に向けた製品とサービスを開発している会社である(同社については、同社のWebサイトをご覧いただきたい。特に「教えてマイクロノード」というページは、IPv6時代にマイクロノードが拓く新しい生活が詳細に解説されているので、一度読んでおくと面白い)。 さて、そうしたIPv6時代において、地球上のあらゆる機器にIPアドレスを付与することができ、それらすべてがネットワークで接続されるようになると、そのネットワークに接続された機器からは365日、24時間データが送られてくるようになるわけだ。 IPv4時代とはけた違いに大量のデータが生み出され続けるということは、当然データ処理能力の向上が大きなテーマとなる。そして、単純に計算能力だけではなく、それらの膨大なデータをどのように扱い、どのように分析すれば、より有効に活用できるかといった、新たなマイニングツールの利用方法を開発していくことも、今後のデータマイニング分野における最大の研究テーマとなるだろう。ひいてはそれが、マイニングツールを使いこなすことができる“人材の育成”という大きなテーマにもつながっていくに違いない。 今回レポートしたように、慶應SFCにおけるデータマイニング教育への支援をはじめとした産学協業の橋渡し的なSPSSの取り組みは、これからのIPv6時代において、無限の広がりが期待されるデータマイニングの可能性を、着実に推進しているようだ。
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||