データ量を操る圧縮/展開を究めよう:コーディングに役立つ! アルゴリズムの基本(8)(4/5 ページ)
ハフマン符号の実装―1
それでは実装していきましょう。長くなるのでいくつかに分割しながら解説します。
先ほどのコードの29行目、「末尾2」のコメントの下の行に以下のコードを追加してください。
<script type="text/javascript">
Array.prototype.clone = function(){
return this.slice(0);
}
function HuffmanTree(data, is_compressed_data) {
if (is_compressed_data) {
this.setCompressedData(data);
} else {
this.data = data;
var char_counter = this.getCharCounter();
this.setHeaderData(char_counter);
this.setTreeData();
}
}
HuffmanTree.prototype.getCharCounter = function() {
var char_counter = new Array();
for (var i = 0; i < this.data.length; i++) {
var ch_num = this.data.charCodeAt(i);
if (char_counter[ch_num] == undefined) {
char_counter[ch_num] = 0;
}
char_counter[ch_num]++;
}
return char_counter;
}
<!-- 末尾3 -->
コードを解説していきます。
2〜4行目
汎用メソッドです。配列のコピーを行うメソッドです。
6〜15行目
ハフマン符号の木構造を表すクラスです。圧縮機能も持ちます。コンストラクタに渡されたデータが圧縮していないものであれば圧縮し、圧縮したものであれば復元します。
8行目
圧縮されたデータを受け取った場合は復元します。
11行目
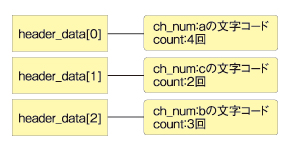
文字ごとの出現回数をカウントした表を作ります。データ構造は文字コードをキーとする配列になっています。
12行目
出現回数の表を、文字コード(ch_num)と出現回数(count)の組み合わせのデータに変換し、ヘッダデータとして保持します。
13行目
木構造を作成します。
17〜28行目
文字ごとの出現回数をカウントするメソッドです。
ハフマン符号の実装―2
引き続き実装していきます。次のコードは上のコードの続きです。29行目「末尾3」の下に続きます。
HuffmanTree.prototype.setHeaderData = function(char_counter) {
this.header_data = new Array();
for (var ch_num = 0; ch_num < char_counter.length; ch_num++) {
if (char_counter[ch_num] === undefined) { continue; }
var ch_count_data = { count:char_counter[ch_num], ch_num:ch_num };
this.header_data.push(ch_count_data);
}
}
Array.prototype.insert_count = function(value) {
for (var i = this.length-1; 0 <= i; i--) {
if (value.count < this[i].count) { break; }
this[i+1] = this[i];
}
this[i+1] = value;
}
HuffmanTree.prototype.setTreeData = function() {
var sort_data = this.header_data.clone();
sort_data.sort(function(a,b) { return b.count - a.count; });
while(true) {
var min1 = sort_data.pop();
var min2 = sort_data.pop();
if(min2 === undefined) {
this.tree_data = min1;
break;
}
var count = min1.count + min2.count;
var node = { count: count, left: min1, right: min2 };
sort_data.insert_count(node);
}
}
<!-- 末尾4 -->
1〜9行目
getCharCounter()で、作られたデータは文字コードをキーとする配列になっています。
char_counter[文字コード] =出現回数
これを文字コードと出現回数を持つオブジェクトに変換します。後で木構造を作るときに使うためです。
11〜17行目
出現回数の配列にオブジェクトを追加するメソッドです。出現回数が多い順にソートされている状態のときに、多い順が保たれるように追加します。
19〜35行目
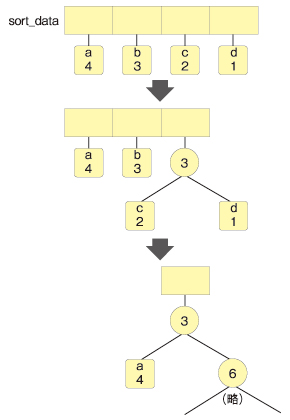
木構造を作成します。
20、21行目
ヘッダデータをコピーしてソートします。多い順にソートします。
23行目
ループを開始します。
24、25行目
配列からデータを取り出します。popは末尾からデータを取得して配列から削除するので、min1には一番出現回数が少ないもの、min2にはその次に出現回数が少ないものが入ります。
26〜29行目
ループの終わりですが、後で解説します。
31、32行目
出現回数を足して、木構造のノードを作成します。ノードは左側(left)が出現回数が少なく、右側(right)が出現回数が多いものになります。
33行目
sort_dataにノードを追加します。
setTreeDataのループでは、配列からデータを取得してノードを作成し、それを元の配列に入れていきます。そのため、ループ2週目以降は配列の中に文字のデータと木構造の両方が入り、徐々に木構造に追加されていく形になっています。
最終的には、木構造が1つだけ入った形になります。こうなったら木構造をインスタンス変数として保持し、ループを終了します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。