Solaris ZFSの基本的な仕組みを知る:Solaris ZFS集中講座(1)(2/3 ページ)
2. 堅牢性
ZFSの強力な安全性と完全性は、トランザクションベースの書き込み時コピー(CoW:Copy on Write)、エンド・ツー・エンドのチェックサム、そしてサポートするRAIDレベルで説明できます。
トランザクションベースの書き込み時コピー(CoW)
図2に、ZFSファイルシステムのデータ構造と、書き込み時コピーの仕組みについて記します。

ZFSにおけるトップレベルの管理ブロックはuberblockと呼ばれます。uberblockから間接ブロックをたどると、データブロックに到達できます。ZFS における書き込みは、すべて図に示したような「書き込み時コピー」となり、データの上書きは行いません。
書き込みが行われる際には、まず既存データがコピーされ、コピーに対して変更が行われます。データをポイントする間接ブロックもまずコピーされ、そのコピーに対して変更が行われます。最後に、不可分な処理としてuberblockが更新されます。
書き込み時コピーはこの一連の操作で1トランザクションとなり、この操作の途中で障害が発生すると、変更前の状態に戻り、ファイルシステムとしての一貫性を損ねるようなことはありません。
このトランザクション処理は、データベースの概念と同様であり、ファイルシステムにデータベースの概念を適用して堅牢性を高めているといえます。
エンド・ツー・エンドのチェックサム
従来のファイルシステムでは、主にブロック単位でチェックサムが計算されていました。これでは、ブロックが誤った場所に書き込まれてしまうと、不具合を検出できません。ブロックの内容とチェックサムの値は合っているためです。
ZFSのチェックサムは、エンド・ツー・エンド、すなわち、ツリー全体にわたり、各ブロックのチェックサムを、その上位ブロックに格納するようになっています。これによって、ツリー全体のどの箇所にエラーが発生しても検出することが可能です。

エンド・ツー・エンドのチェックサム計算は、相応のCPU能力を必要とします。近年のCPU性能向上がこの技術の利用を可能にしたといえるでしょう。
チェックサム計算に基づきエラーが検出されると、ZFSは自動でデータの回復を行います。これは、個々のブロックの復旧だけでなく、RAIDボリュームの自己修復も含みます。
エンド・ツー・エンドのチェックサムを行っていないボリューム管理ソフトウェアやファイルシステムでは、例えばミラーボリュームの片方のドライブで誤ったブロックを読み込んでも、それが誤りであることを検出できずに不具合が発生します。
ZFSでは、上位ブロックが下位ブロックの誤りを検出すると、RAIDを構成するほかの物理ストレージから正しいと判断できるブロックを読み込み、誤りを修復します。
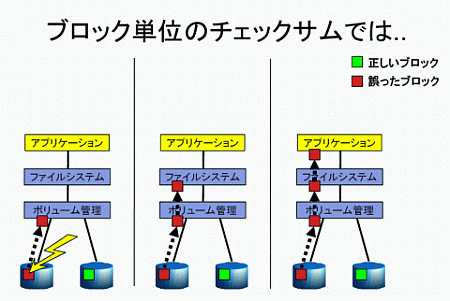
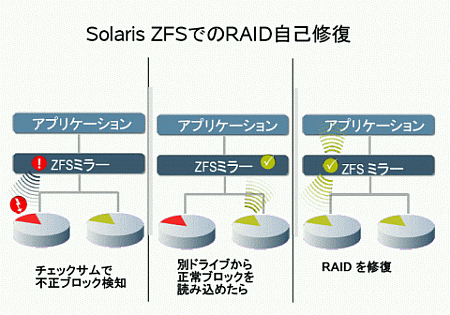 図4 ブロック単位のチェックサムとZFSでのRAID自己修復
図4 ブロック単位のチェックサムとZFSでのRAID自己修復サポートするRAIDレベル
ZFSでは、RAID 0(ストライプ)、RAID 1(ミラー)に加えて、RAID 5の拡張である RAID-Z(シングルパリティ)と、RAID 6の拡張である RAID-Z2(ダブルパリティ)を使用できます。
RAID 5/6ではその仕組み上、RAID 5/6書き込みホールと呼ばれる問題がありました。これは、すべてのストライプとパリティが書き込み終わる前に障害が発生した場合、パリティとデータの不整合が発生するという問題です。ハードウェアRAIDではバッテリバックアップされたキャッシュメモリを使用することなどでこの問題に対処していますが、価格要件を満たせない場合があります。
RAID-Z/Z2では、書き込みのサイズに応じてストライプ幅を自動調整し、必ず書き込みがストライプ全体に及ぶようにします。小さなサイズの書き込みに対しては、ストライプ全体に書き込みが及ぶサイズとなるようまとめられます。
書き込みはトランザクションとして扱われるので、書き込みが途中で中断されている状態は起こりません。
ストライプ幅自動調整と書き込み時コピーの両技術によって、ストライプ全体への書き込みが完了しているか起きていないかのどちらかの状態しか存在せず、RAID 5/6の場合のような書き込みホールは発生しません。
ZFS はソフトウェアのみで RAID 5/6書き込みホールを解消する世界初の技術で、安価なストレージデバイスでも高信頼性を実現します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。