Hadoopによるテキストマイニングの精度を上げる2つのアルゴリズム:テキストマイニングで始める実践Hadoop活用(最終回)(3/3 ページ)
ロジスティック回帰の重みの更新
尤度関数は掛け算の形で扱いにくいので、次のような関数を考えます。
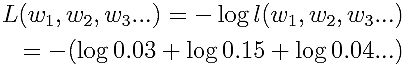
対数を取ったので、掛け算ではなく、足し合わせればよくなります。さらにマイナスをしているので、この関数をなるべく小さくするような重みを求めていけばいいことになります。
ここで、前回の記事を思い出してください。前回は損失関数をなるべく小さくするようにだんだんと重みを更新していきました。今回も同じく、
をなるべく小さくするのが目的です。つまり、この
は損失関数といえます。
ということは、前回と同じように、この損失関数の微分を取って、だんだんと重みを更新していけばよいのです。
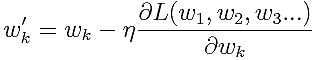
カテゴリ「k」の重み
を更新する式で、損失関数を
で微分したものを古い重みから引いています。
はカテゴリごとの重みでしたので、この式1つでは、あるカテゴリ「k」の重みしか更新しないことに注意してください。実際は、カテゴリ数分の式で、別々に重みを更新していくことになります。
この、
を計算すると、以下のようになります。
前回とほとんど同じシンプルな式になります。違いは
の部分だけです。
は1つ前の★マークの式で、0〜1の確率値を取るように補正しています。この式でそれぞれのカテゴリごとに別々に重みを更新すれば、その重みを使って、それぞれのカテゴリごとの確率を推定できるようになるわけです。
ロジスティック回帰のMapReduceプログラムの作成
では、ロジスティック回帰のMapReduceプログラムを作成していきましょう。今回はカテゴリごとの複数の重みを推定しなければならないので、今までのプログラムを少し変更する必要があります。
Mapper側
まずはMapperから作成していきましょう。
1 public class MultiClassLogisticRegressionMapper
2 extends Mapper<VIntWritable, MapWritable, VIntWritable, MapWritable> {
3 private <MapVIntWritable, MapWritable> weightMap = new <HashMapVIntWritable, MapWritable>();
4 private int classNum = 20;
5 private int classWidth = 5;
6 private double stepSize = 0.001;
7
8 @Override
9 public void setup(Context context) throws IOException, InterruptedException {
10 Configuration conf = context.getConfiguration();
11 stepSize = conf.getFloat("sgm.step.size", (float) stepSize);
12 classNum = conf.getInt("class.num", classNum);
13 classWidth = conf.getInt("class.width", classWidth);
14 String weightFile = conf.get("weight.file");
15 if (weightFile == null) {
16 for (int i = 0; i < classNum; i++) {
17 weightMap.put(new VIntWritable(i), new MapWritable());
18 }
19 } else {
20 FileSystem fs = FileSystem.get(conf);
21 SequenceFile.Reader reader = new SequenceFile.Reader(fs, new Path(weightFile), conf);
22 try {
23 VIntWritable key = new VIntWritable();
24 MapWritable value = new MapWritable();
25 while (reader.next(key, value)) {
26 weightMap.put(new VIntWritable(key.get()), new MapWritable(value));
27 }
28 } finally {
29 reader.close();
30 }
31 }
32 }
33 @Override
34 public void map(VIntWritable key, MapWritable value, Context context)
35 throws IOException, InterruptedException {
36 int b = key.get();
37 value.put(new Text(CommonUtil.BIAS_KEY), new VIntWritable(1));
38 double[] y = new double[weightMap.size()];
39 double ySum = 0;
40 double wxMax = 0;
41 for (VIntWritable cat : weightMap.keySet()) {
42 double wx = DiscriminantFunctionAlgorithm.predict(value,weightMap.get(cat));
43 y[cat.get()] = wx;
44 wxMax = Math.max(wxMax, wx);
45 }
46 for (VIntWritable cat : weightMap.keySet()) {
47 double yk = Math.exp(y[cat.get()] - wxMax);
48 y[cat.get()] = yk;
49 ySum += yk;
50 }
51 for (VIntWritable cat : weightMap.keySet()) {
52 MapWritable weightMapPerCat = weightMap.get(cat);
53 int catInt = cat.get();
54 int bk = ((int) b / classWidth == catInt) ? 1 : 0;
55 double prob = y[catInt] / ySum;
56 for (Entry<Writable, Writable> entry : value.entrySet()) {
57 Text word = (Text) entry.getKey();
58 int x = ((VIntWritable) entry.getValue()).get();
59 DoubleWritable weightWritable = (DoubleWritable) weightMapPerCat.get(word);
60 double diffWeight = -stepSize * (prob - bk) * x;
61 if (weightWritable == null) {
62 weightMapPerCat.put(word, new DoubleWritable(diffWeight));
63 } else {
64 double w = weightWritable.get() + diffWeight;
65 weightWritable.set(w);
66 }
67 }
68 }
69 }
70 @Override
71 public void cleanup(Context context)
72 throws IOException,InterruptedException {
73 for (VIntWritable key : weightMap.keySet()) {
74 MapWritable value = weightMap.get(key);
75 context.write(key, value);
76 }
77 }
78 }
11行目は刻み幅
を設定しています。12行目は、カテゴリの数、13行目で年齢をカテゴリに区切る幅を設定しています。例えば、100歳までの年齢で、5歳ごとにカテゴリに分ける場合は、classNumが20、classWidthが5になります。0〜4歳、5〜9歳、10〜14歳といったようなカテゴリに分けるということです。
14〜31行目では、重みのファイルを「weightMap」に読み込み、なければ、初期化します。weightMapの「key」はカテゴリの番号、「value」が重みベクトルです。
36行目は正解の寿命を取得、37行目でバイアスキーを設定しています。
38〜50行目では、
の分子と分母を計算しています。分子の「exp(wx)」は、配列「y」にカテゴリごとに格納します。分母の和は「ySum」に設定しています。
注意してほしいのは、「exp」関数は700を超えた辺りで、オーバーフローして「Inf」になってしまうということです。そこで、オーバーフローを避けるために、47行目ですべてのカテゴリの「wx」の最大値を引いて「exp」を計算しています。40〜45行目は、この「wx」の最大値を計算しています。
51〜68行目でカテゴリごとの重みを更新しています。54行目で、正解のカテゴリに一致したら確率1、そうでなければ確率0を「教師信号」として割り当てています。55行目で、
を計算しています。60行目で、更新する重みの差分を計算し、61〜66行目で重みを更新して、weightMapに設定しています。
73〜76行目で、カテゴリ番号を「Key」、カテゴリごとの更新した重みベクトルを「Value」にして出力しています。カテゴリの数だけ出力され、Reducerで集計されることになります。
Reducer側
Reducerは前回のRegressionReducerとほとんど同じです。違いはKeyがカテゴリ番号のVIntWritableになっていることだけです。
つまり、カテゴリごとに重みを平均して、カテゴリごとに重みを出力しています。
変更した部分を強調しています。
public class MulticlassClassifierReducer
extends Reducer<VIntWritable, MapWritable, VIntWritable, MapWritable> {
@Override
public void reduce(VIntWritable key, Iterable values,Context context)
throws IOException, InterruptedException {
……
}
}
実行
前回作成した、IterativeParameterMixingDriverのrunIteration関数を以下のように変更すれば、実行できます。変更した部分を強調しています。
private static void runIteration(Configuration conf, Path input, Path output)
throws IOException, InterruptedException, ClassNotFoundException {
Job job = new Job(conf, "logistic regression: " + output);
job.setJarByClass(IterativeParameterMixingDriver.class);
job.setMapperClass(MulticlassLogisticRegressionMapper.class);
job.setReducerClass(MulticlassClassifierReducer.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(VIntWritable.class);
job.setOutputValueClass(MapWritable.class);
job.setNumReduceTasks(1);
FileInputFormat.addInputPath(job, input);
FileOutputFormat.setOutputPath(job, output);
if (!job.waitForCompletion(true)) {
throw new InterruptedException("job failed: " + output);
}
}
実行コマンドは以下の通りです。
$ hadoop jar job.jar IterativeParameterMixingDriver -D mapred.child.java.opts=-Xmx1024m -D sdm.step.size=0.001 -D iteration.num=15 /hdfs/path/to/input /hdfs/path/to/output
前回とほとんど同じですが、Mapperでメモリが足りなくなる場合があるので、「mapred.child.java.opts=-Xmx1024m」というMapper、ReducerのJavaオプションを指定しています。
テキストからロジスティック回帰で、寿命を予測するプログラムは以下の通りです。
1 public class TestMulticlassClassifier {
2 private static int classWidth = 5;
3 public static void main(String[] args) throws Exception {
4 if (args.length < 2) {
5 System.err.println("Usage: cmd <test file> <train file>");
6 return;
7 }
8 MapWritable testMap = CommonUtil.readTestFile(args[0]);
9 Map<VIntWritable, MapWritable> weightMap = CommonUtil.readMulticlassWeightFile(args[1]);
10 testMap.put(new Text(CommonUtil.BIAS_KEY), new VIntWritable(1));
11 int maxCat = 0;
12 double maxYk = 0;
13 for (VIntWritable cat : weightMap.keySet()) {
14 double yk = DiscriminantFunctionAlgorithm.predict(testMap,
15 weightMap.get(cat));
16 if (yk > maxYk) {
17 maxYk = yk;
18 maxCat = cat.get();
19 }
20 }
21 int predict = maxCat * classWidth;
22 System.out.println("" + predict + "" + (predict + 5) + "");
23 }
24 }
13〜20行目で、カテゴリごとの確率の推定を行い、最も確率が高いカテゴリを求めています。どのカテゴリの確率が高いか調べるだけならば、確率
を計算する必要はなく、単に「wx」の大小を比較するだけでOKです。
再び記事「モテる女子力を磨くための4つの心得「オムライスを食べられない女をアピールせよ」等 - Be Wise Be Happy Pouch [ポーチ]」のテキストから作者の寿命を予測してみましょう。
あなたは50歳〜55歳で死ぬでしょう。
業務などでの課題にテキストマイニングを応用しよう
本連載では、まず、Hadoopとテキストマイニングとはどういうものか、概要を説明しました。テキストマイニングといっても幅広いのですが、テキストから何かの値を予測する「回帰」と、テキストをカテゴリに分類する「テキスト分類」に注目して手法を説明し、実際にMapReduceプログラムを作成していきました。
今回は、青空文庫の作品から学習して、テキストデータの作者の寿命を推定するプログラムを作成しましたが、「ブログの著者の性別、年代・地域を予測してマーケティングに役立てる」「ユーザーからの質問と、その回答をカテゴリごとに分類して、マニュアルを自動作成する」「問題になりそうな社員のブログやTwitterの発言などを自動抽出してリスクを回避する」などさまざまな応用が考えられます。
これらの処理は必ずしもHadoopを使う必要はありませんが、Web上のデータなど“巨大なデータ”を扱う場合は、Hadoopを使うことで、テキストマイニング処理の時間の短縮が期待されます。ぜひ、業務などでの課題にテキストマイニングが応用できないか、検討してみてはいかがでしょうか。本連載が、そうした課題解決に少しでもお役立に立てれば幸いです。
本連載は、角田直行さん、@nokunoさんにチェックしていただきました。お礼を申し上げます。
参考文献
記事で紹介した手法や、機械学習、テキストマイニングについてより詳しく学びたい方のために参考文献を挙げておきます。
前回紹介した手法などが、分かりやすく書かれている入門書です。
機械学習をテキストの処理にどう応用するか、実装面も含めて書かれています。今回紹介したロジスティック回帰も対数線形モデルという名前で紹介されています。
機械学習の定番の教科書です。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。