並列分散処理の常識をHadoopファミリから学ぶ:ビッグデータ処理の常識をJavaで身につける(2)(2/3 ページ)
Threadによる並列分散プログラミングの7つの課題
並列分散処理の課題の例として、Javaの「Thread」クラスを使った例を見ていきます。Threadクラスを使用することで、Fork/Joinという並列処理を簡単に実装できます。並列プログラムの課題も、このコードに潜んでいるので、クイズと思って探してください。
今回、以下のような「売上伝票の世代別分析」という要件を題材にして考えてみます。
- ある店舗の 売上伝票データ20万件を世代別(〜5歳/6〜15歳/../86歳以上の9つに区分化)に集計し、伝票数と合計金額を出力
- 売上伝票(伝票番号、商品名、金額、顧客番号、顧客番号、顧客名、性別、生年月日、カード番号)
伝票データを1行ずつファイルから読み込み、Thread内で、文字列からデータを取り出し、年齢を計算、世代区分と金額を出力します。同期を取るために、一度ファイルに出力して、その後世代ごとに集計します。
class SalesSlipThread extends Thread {
public void run() { // スレッド処理のスタート
SalesSlip slip = new SalesSlip(str);
// slipの内容をファイル書き込み
:
【略】
:
}
}
class SalesSlip {
static DateFormat df = DateFormat.getDateInstance();
public SalesSlip(String value) {
String values[] = value.split(",");
payment = new Integer(values[2]);
birth = df.parse(values[6]);
setGeneration(); // 年齢の計算と世代の計算
}
:
【略】
:
}この後、世代配列ごとに集計すれば、処理は完了です。このプログラムの課題ですが、まず同時並列数に制約がないので、メモリを際限なく消費し「OutOfMemoryError」が発生します。ファイルへの同時アクセスは競合しますから、書き込みをロストするケースもあるでしょう。また、世代計算に使っている「DateFormat」クラスはThreadSafeではないので、「RuntimeException」が発生します。
Threadのような並列して動くワーカの動きに注意を払って作る必要があります。つまり「並列」プログラムは、少なくとも下記の点を考慮しなくてはいけません。
- 【a】稼働環境のCPUやメモリなどのリソースに応じて、並列度を柔軟に変更できる
- 【b】共有する変数・ファイルに対し更新排他制御を行う
- 【c】ワーカ間で共有して利用可能なフレームワークを利用
さらに「分散」環境に対応する場合、プログラマは下記の仕組みを作り込まなくてはなりません。
- 【d】ワーカ数や問題に応じて対象データを分割し、所在を管理
- 【e】ワーカへ実行モジュールをデプロイ
- 【f】デプロイしたモジュールを全ワーカで起動、監視してエラー発生時は別のワーカに振り分けるなどのエラー処理を行う
- 【g】各ワーカで動く処理の同期を取り、ワーカを跨った処理結果を集約
そのうえで「どうやってうまく並列するように分散させるか」まで考えなくてはいけないとなれば、これはなかなかの重労働です。Hadoop/MapReduceは、これらの処理を助けてくれます。
Hadoopは並列処理の課題を取り除く
Hadoopを使うと、分散環境に伴う【a】〜【g】の処理を、全てHadoopが実施するか、取り除きます。
- 【aについて】同時並列数はコンフィグレーションファイルで制御
- 【bについて】データは各ワーカへ分割して渡されるので、競合しない
- 【cについて】Threadなどの並列処理フレームワークを使う必要はなくなる
さらに【d】〜【g】の分散処理はHadoopで実現されるので、開発者が作り込みをする必要もなくなります。
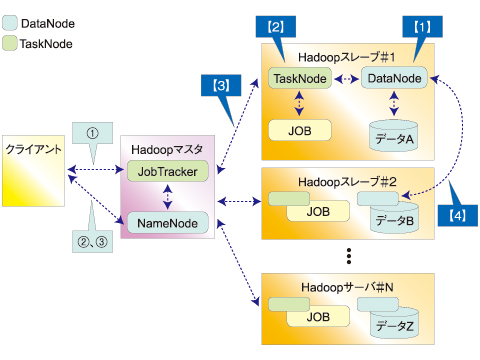 図6 Hadoopのロールと動き
図6 Hadoopのロールと動きHadoopをご存じの方には、おなじみのロールモデルだと思います。Hadoopクラスタは「マスタ」と、処理を行う「スレーブ」という2つの役割で構成されます。それぞれにHDFSとMapReduce管理用のデーモンプロセスがあり、これらが相互に連携して動くことで、余計なノード間の通信を省くところが、1つの特性です。
HDFSの役割
【1】では、クライアントはマスタのNameNodeにファイル登録を依頼します。NameNodeは対象ファイルを、レコードサイズをまたがらないようブロックサイズごとに分割してスレーブに分散配置します。分散単位となる「ブロック」サイズはデフォルトで64Mbytesなので、「ファイルサイズ÷ブロックサイズ<スレーブ数」となると、余ったスレーブには配置されません。
ただし、「レプリカ」(複製)数を設定すると、ブロックの複製を他のノードに配置してくれます。クライアントはデータがどこにあるのか、どのように分割しているか意識する必要はありません。
MapReduceの役割
【2】では、クライアントがマスタへジョブの起動を依頼すると、マスタは対象jarファイルをスレーブにコピーして、スレーブにジョブ実行を指示します。
【3】では、スレーブはブロック単位にMapとReduceの処理を実行、マスタは動作監視して、エラー時はリトライさせます。
【4】では、Map処理でデータにKey値を割り当てます。全てのMap処理が終わると、Key値でソート/集約し、各スレーブに送ってReduce処理で集計させます。このタイミングで同期が取られることになります。
Reduce-Key値を何にするかによって、データの分割の仕方を柔軟に決められます。つまり、「処理をどのように分割したら性能が良くなるか」にエンジニアは注力できます。
並列性を持つところを見つけるための「データ並列」「タスク並列」
どう処理を分割するかを考えるヒントとして、「データ並列」「タスク並列」という並列化パラダイムを紹介しておきます。
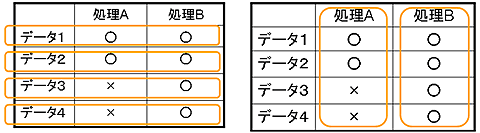 図7 データ並列(左)とタスク並列(右)
図7 データ並列(左)とタスク並列(右)- データ並列:対象データを分割して、それぞれに同じ処理を施す
- タスク並列:データにかかわらず、相互に依存しない処理(タスク)を並列に実行
MapReduceは、大量データを対象とした処理であり、全てのワーカは同じロールを割り当てられます(もちろんデータに応じて、違う振る舞いをするようにも書けますが)。そのため、MapReduceには「データ並列」でデータを基準に分割を検討する方が合っています。
スレーブ数より細かく分けても、Hadoopがブロック単位に処理をまとめてくれます。逆に、粗く分けていると、ブロック数以上はノードを増やしてもスケールしないので、細かい視点で考えた方がいいでしょう。
分割したデータに対する処理を、「並列実行可能か」「逐次処理でないとできないところはどこか」「同期はどのタイミングで取るべきか」などで見直していきます。
もちろん、あらゆる問題をMapReduceで解決することがベストの選択とはいえません。スレーブ間で何度も通信する必要がある処理、例えばノード間でやりとりを繰り返すグラフ理論の実装であれば、「Giraph」のような個別のアーキテクチャを提供するフレームを採用した方がいいでしょう。
効率的なプログラムのための「Partitioner」「Combiner」クラス
処理を分割すれば、後はMapReduceのロジックで実装するだけです。「MapReduceとは?」については、すでに多くの情報がありますから、記載は省きます(知らない方は、以下の記事を参照してください)。
- GoogleのMapReduceアルゴリズムをJavaで理解する
いま再注目の分散処理技術(前編)
最近注目を浴びている分散処理技術「MapReduce」の利点を、Javaのサンプルからアルゴリズムレベルで理解することによって探る
ここでは、限られたリソースで目指した性能目標を実現するためのHadoopのアプローチを見ていきます。
並列プログラミングが難しくなるのは、リソースに応じた「効率的なプログラム」を作ろうとするところからです。例えば、図8のようにデータ群をキー(図8の縦)の値で等分割したとしても、キーにひも付けられるデータ量(図8の横)が同じになるわけではありません。その場合、一部のスレーブの処理(例えば図8のノード3)だけ時間がかかり、その結果スケールしないプログラムになってしまいます。
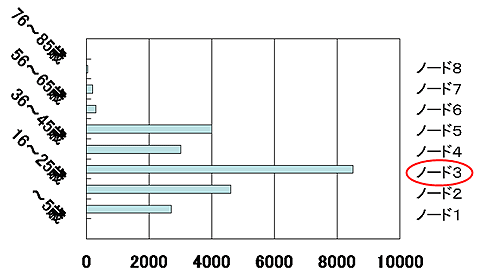 図8 データ群をキーの値で等分割した例
図8 データ群をキーの値で等分割した例MapReduceのデフォルトの動きは、キーのハッシュ値をスレーブ数で割って、剰余値で分割先を決めているので、同じ個数のキー値がスレーブに割り当てられます。
ただし、同一キーにひも付くレコード件数によってはアンバランスな状態になり、1つのスレーブの処理が全体処理のボトルネックになることがあります。このキー配分を変更するクラスとして、Hadoopは「Partitioner」クラスを提供しており、これを使って分割ルールを変更できます。
また、スレーブ間の通信コストを削減する手段の1つとして、クラス「Combiner」が提供されています。処理のおさらいですが、各スレーブはmap処理で、[ReduceKey,value]の形にデータを加工、これをHadoopがReduceKey値でソート/集約し、各スレーブに再配布してreduce処理を呼び出します。Combinerは、map処理後のローカルにある全データに対しreduce処理を実行します。そうすることで「ネットワーク越しのコピー量を削減しよう」というアプローチです。
このように、処理の分割の仕方やタイミングで、大きく性能が変わってきます。
Hadoopがしてくれないこと
ところで、お気付きの方もいるかと思いますが、RDBのクラスタ機能を用いても基本的には同じことができます。ただし、図6の【1】に関しては設計時に分割キーを決める必要があり、これが、【3】や【4】の処理性能にも影響します。
RDBはデータ登録時のコストが大きいので、頻繁にデータを入れ直すよりはテーブル定義時に想定する検索処理を決めて、これに合わせた分割キーを決定する必要が出てきます。
そもそもRDBクラスタは、パフォーマンスより、高可用性を目的にしていると思われます。これはRDBが実現しなくてはいけない機能が他に数多くあるからこそでしょう。例えば、下記のようなものです。
- ノードを跨った更新トランザクションのACID属性
- 分散環境でのレプリカへの完全同期と一貫性の保証
- ノードを跨ってもテーブルを結合して検索できるSQLの保証
- SQLを基に分散環境でも最適な実行計画を最速で計算するオプティマイザ
これらはHadoopが性能のトレードオフとして割り切ったものです。複数ユーザーからの同時接続を考慮した排他制御や、エラーのロールバックなどのトランザクション管理は行いません。
基本的にHDFSはファイルシステムですから、処理結果は更新ではなく追加する形です。論理I/O単位が64Mbytes以上を前提としますから、RDBの4〜16Kbytesで行うような、少量データ検索や更新には不向きです。動的にJOBをデプロイするので、リアルタイムに結果を返すことも目標ではありません。
Hadoopが目指すのは大容量ファイルを扱うバッチ処理を高速に実現することで、トランザクション制御を必要としない処理です。これらの制御を止める代わりに、容易な拡張機能、登録性能の向上を得ています。
ですから、データ量が多くても、対象処理を限定して、それに沿った形でテーブルを定義し、パーティションなどに分割して運用可能であれば、そして登録処理より検索が主体であれば、RDBの方が速いかもしれません。しかし、アドホックにファイル内のデータを操作したい場合、Hadoopは良い選択肢かと思われます。
そうはいいつつも、「基幹業務システムに欠かせないバッチ処理などをMapReduceというアルゴリズムに変換しないと使えない」というのは少々高いハードルです。提供しているのはMapとReduceという枠組みだけなので、それにどう取り組むとうまく分散するかを理解するには発想の転換が求められます。
これらは、Hadoopサブプロジェクトの「特性」といってもいいですが、「課題」ととらえる向きもあるでしょう。こうした課題に対するアプローチをしているのが関連プロジェクトです。次ページでは、関連プロジェクトを簡単に紹介していきます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。