並列分散処理の常識をHadoopファミリから学ぶ:ビッグデータ処理の常識をJavaで身につける(2)(3/3 ページ)
3つの課題に応える「Hadoopファミリ」
関連プロジェクトは、Hadoopが抱える以下の3つの課題に応えたものです。
【課題1】「並列分散処理をもっと簡単に書きたい」
MapReduceをJavaで書く処理はある種のひらめきが必要ともいわれます。特に、SQLで書かれていた処理をMapReduceで書き替える場合、思考の切り替えが必要で苦労することも多いようです。たとえ慣れていても、Hadoopで簡単なデータ加工したい、そのためだけに多くのクラス定義をするのは面倒です。
この難易度を下げるハイレベル言語として「Hive」「Pig」が存在します。どちらの言語もSQLやストアドプロシジャのようなコードを書いて、MapReduceを動かせます。対話型のシェルユーティリティもあり、簡単にMapReduceを動かせる点も魅力的です。Hiveの詳細は、後述します。

【課題2】「並列分散環境で大容量を処理できるRDBMSが欲しい」
HDFSはファイルシステムなので、すでに構造化したデータを持つRDBMSに比べれば操作性に見劣りする部分があるのは否めません。この課題へのアプローチが、カラム指向KVS(KeyValueStore)の「Hbase」と、分散トランザクション制御を行う「Zookeeper」でしょう。

データの格納先がHDFSになっており、そのままで分散処理される半面、Hadoopの持つ「単一障害点(Single Point of Failue)」の問題が、そのまま引き継がれます。マスタが単一障害点となることは常に課題として挙げられています。ノードの構成を管理するマスタが落ちたからといって、すぐHadoopのJOBが止まるわけではありませんが、制御できなくなる以上、HA構成を自分で作る必要があります。

これを回避できるアーキテクチャを持つKVSとして「Cassandra」がHadoop関連プロジェクトに登録されているようです。Cassandraはマスタ/スレーブという役割はなく、Quorum Systemを使って分散機構を実現します。全Nodeが同一の機能を有しているので、単一障害点はありません。

【課題3】「Hadoopの並列分散処理機構を使って、特殊な処理を動かしたい」
Hadoop自体はMapとReduceという分散処理の枠組みを提供しますが、その上で動く機能に特に色を付けていません。Hadoopに向くであろう機械学習やログ管理を行うために作られたのが「Mahout」と、「Chukwa」です。

Mahoutは機械学習とデータマイニングライブラリです。後の回で取り上げるので、ここではChukwaについて説明を加えます。
Chukwaは大規模分散システムでのログ収集管理を目的としたシステムです。

もともとHadoopはログ収集や管理を目的の1つとしていました。結果的に今のHadoopは小さいファイルをたくさん扱うよりは、数少ない大きいファイルを扱う処理向きのシステムになっています。代わりに、小さい大量のログファイルを迅速に扱うためのプラットフォームがChukwaです。ログ収集対象マシンに格納されたログファイルを集めて、HDFSとHbaseに格納します。このログをMapReduceで集約します。
さらに、結果を照会できる監視ツール「HICC(Hadoop Infrastructure Care Center)」も提供されています。
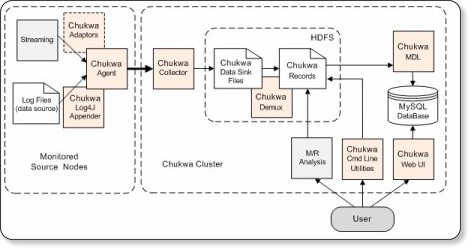
ただし、このプロジェクトはまだIncubatorの位置付けで、同様にログ収集、管理機能を持つ「Flume」が2011年6月からApache Projectとなっているところを見ると、もうしばらく様子を見た方がよさそうです。

【その他】Hadoopサブプロジェクトの機能強化
これらに含まれないものとして、HDFSの機能拡張に使える「Avro」があります。Avroはデータシリアライズシステムです。サービスを動かすようなものではなく、データのやりとりのために構造化データを直列化するプロトコルと仕組みで、シリアライズ対象となるデータの構造定義や、RPC定義はJSONで行います。

ただし、現在のHadoopクラスタの通信で使われているのは「Protocol Buffers」です。JVM上での「create object」「serialize」「deserialize」のベンチマークの結果「java-serialization-benchmarking:benchmark(2011/11/28)」を見ると、まだ>Protocol Buffersの方が速いようですし、こちらも「将来的に利用されるのでは?」という位置付けでしょう。
Hiveに学ぶ性能改善アプローチ
最後に、Hadoopが抱える課題を解決するファミリの例として、Hiveを紹介しておきます。

Apache HiveはSQLライクな言語「HiveQL」を提供するHadoop用の簡易言語で、バッチ用スクリプトと、対話型シェルユーティリティを持ちます。Hiveを使うことで、コンパイルの手間を省けるので、Hadoopクラスタを簡単に試すには良い仕組みです。
サンプルとして、郵便番号データを都道府県で集計する処理を示します。
Hiveは、「ExecMapper」「Reducer」クラスがHiveQLのコードを解釈してMapReduce処理として動きます。ここに性能改善の仕組みが埋め込まれています。同じデータに対し、同じ処理をJavaのMapReduceで書いた場合と比較すると以下のような結果になりました。
| Hive | Java |
|---|---|
| 2min 51sec | 5min 48sec |
ご覧のように、処理によってはJavaでMapReduceを書くよりHiveの方が速くなります。デフォルトの動きではmap関数には読み込んだデータが1行ずつ渡され、これをkey/valueの形に分けて返しているので、現状はmap処理の入力レコード数と出力レコード数は同じになります。
public void map(Object key, Text value, Context context)
throws IOException,InterruptedException
{
p.init(value.toString());
context.write(p.todoufuken_name, one); // 入力1件に対し、1件出力
}しかし、Hiveの実行ログを見ると、「Map Input Records」が1億2000万件なのに対し、「Map Output Records」が181件です。
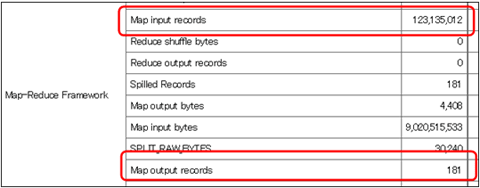 図9 Hiveの実行ログ
図9 Hiveの実行ログ試しに前述の「Combiner」クラスを使ってみると、同じようにCombiner Output Recordsが181件となります。ただし、ログを見る限りHiveのデフォルトの動作ではCombinerは使っていないようです。
このことから「map処理で複数件のレコードを集計する」といったチューニング処理が組み込まれていると推測できます。そこで、同様の処理をJavaのプログラムでも行ってみました。
これでHiveと同程度の性能が出せました。
| Hive | Java | Java-Combiner | Java-inMapper |
|---|---|---|---|
| 2min 40sec | 5min 48sec | 3min 15sec | 2min 35sec |
map/reduce関数のように繰り返し呼ばれる処理は、「小さな改善が大きく効いてくる」ということです。Combinerの利用は簡単ですが、一度map処理を実行したのち、再度集計をするロスがあります。上記コードでは、map処理中にreduce相当の処理を行うことで無駄を省いています。
この設計は、書籍「Hadoop MapReduceデザインパターン」の「3.1 ローカル集計」で示されている「in-mapper combining」を参考にしました。どのようにmap/reduce関数を作れば、効率が良いか、データのレイアウトや並び方、比率によっても異なり、一概にはいえませんが参考情報も多く出てきています。構造化されたきれいなデータであれば、Hiveでもいいでしょう。しかし、背後で動くMapReduceの動きを知ることで、大きく性能改善できるのも、Hadoopの魅力の1つではないでしょうか。
Hiveについては、以下の記事もご参照ください。
- Hadoop+Hive検証環境を構築してみる
Hive——RDB使いのためのHadoopガイド(前)
Hadoop上でSQLライクな操作が可能なDWH向けのプロダクトHive。RDBに慣れた人にも使いやすいので、ぜひ試したい
次回以降は、KVSや機械学習
以上がHadoopの特徴と課題、そして現在の「Hadoopファミリ」の顔ぶれです。Hadoopの特性をご理解いただければ幸いです。
次回以降は、Hadoopでビッグデータを活用するための常識として、KVSであるHbaseや、機械学習エンジンMahoutなどを紹介していきます。
著者紹介
TIS株式会社 先端技術センター 主査
森 未英(もり みえ)
大規模案件での性能問題にかかわり、性能対策の観点でOODB、RDB、NoSQL、データモデリングなどの効果と検証に取り組む。TIS先端技術センターでは、採れたての検証成果や知見などをWebサイトで発信中
関連記事
- テキストマイニングで始める実践Hadoop活用
- 次世代Hadoopの特徴は、MapReduce 2とGiraph
Hadoopの父に聞く、HadoopとClouderaの現在・未来 - MapReduceのJava実装Apache Hadoopを使ってみた
いま再注目の分散処理技術(後編) - 分散Key-Valueストアの本命「Bigtable」
- Javaで覚えるIT技術者の40の常識
新人プログラマ/SEは覚えておきたい“まとめ”
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。