共有メモリとファイルシステム――その2:知ってトクするシステムコール(7)(2/2 ページ)
■ipc_mmap+tmpfs* : tmpfsメモリファイルシステム上のファイルをmmap(2)でマッピングしたケース
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
int
main(void)
{
int fd, i, rp=10;
long j;
char *s, *t;
fd = open("/tmp3/shm", O_RDWR);
s = mmap(0, 104857600, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
*s = '0';
for (i = 0; i < rp; i++) {
while ('1' == *s)
;
t = s;
for (j = 1; j < 104857600; j++)
*s++ = 'a';
s = t;
*s = '1';
}
}
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
int
main(void)
{
int fd, i, rp=10;
long j;
char *s, *t, b;
fd = open("/tmp3/shm", O_RDWR);
s = mmap(0, 104857600, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
for (i = 0; i < rp; i++) {
while ('0' == *s)
;
t = s;
++s;
for (j = 1; j < 104857600; j++)
b = *s++;
s = t;
*s = '0';
}
}
■ipc_mmap+ufs* : ディスク上のUFS領域のファイルをmmap(2)でマッピングしたケース
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
int
main(void)
{
int fd, i, rp=10;
long j;
char *s, *t;
fd = open("/tmp/shm", O_RDWR);
s = mmap(0, 104857600, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
*s = '0';
for (i = 0; i < rp; i++) {
while ('1' == *s)
;
t = s;
++s;
for (j = 1; j < 104857600; j++)
*s++ = 'a';
s = t;
*s = '1';
}
}
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
int
main(void)
{
int fd, i, rp=10;
long j;
char *s, *t, b;
fd = open("/tmp/shm", O_RDWR);
s = mmap(0, 104857600, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
for (i = 0; i < rp; i++) {
while ('0' == *s)
;
t = s;
++s;
for (j = 1; j < 104857600; j++)
b = *s++;
s = t;
*s = '0';
}
}
それぞれ1つ目が送信側、2つ目が受信側になっている。排他制御などはこれまでと同じだ。
実行結果のまとめ
それぞれ/usr/bin/timeとtruss(1)で実行を計測した結果をまとめると、次のようになった。実行速度はtmpfs上のファイルを利用したものが1.7倍ほど高速で、それ以外はほとんど変わらないという結果が得られた。処理時間のほとんどがユーザー時間として消費されていることも分かる。
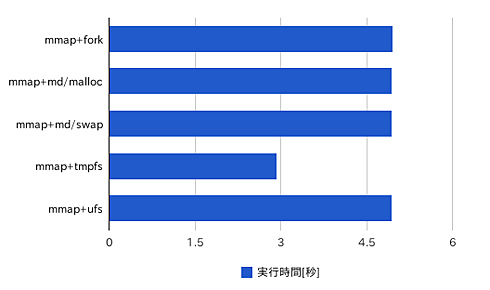 図1 各実装方式の処理時間の比較
図1 各実装方式の処理時間の比較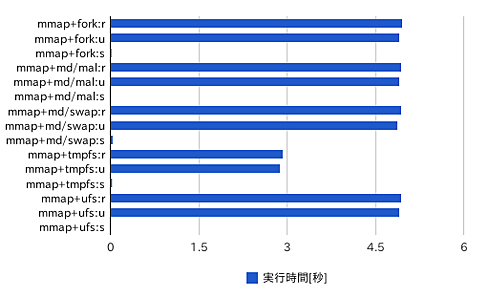 図2 tmpfs上のファイルを利用したものがやや高速で、それ以外に大きな違いは見られない
図2 tmpfs上のファイルを利用したものがやや高速で、それ以外に大きな違いは見られない| 実装方法 | 実行時間[秒] |
|---|---|
| ipc_mmap+fork:real | 4.96 |
| ipc_mmap+fork:user | 4.92 |
| ipc_mmap+fork:sys | 0.02 |
| ipc_mmap+mdconfig_malloc-1:real | 4.94 |
| ipc_mmap+mdconfig_malloc-1:user | 4.92 |
| ipc_mmap+mdconfig_malloc-1:sys | 0.00 |
| ipc_mmap+mdconfig_swap-1:real | 4.94 |
| ipc_mmap+mdconfig_swap-1:user | 4.88 |
| ipc_mmap+mdconfig_swap-1:sys | 0.04 |
| ipc_mmap+tmpfs-1:real | 2.93 |
| ipc_mmap+tmpfs-1:user | 2.88 |
| ipc_mmap+tmpfs-1:sys | 0.03 |
| ipc_mmap+ufs-1:real | 4.94 |
| ipc_mmap+ufs-1:user | 4.92 |
| ipc_mmap+ufs-1:sys | 0.00 |
| 表1 各実装方式の処理時間 | |
システムコールの呼び出し回数には、それほど大きな違いは見られない。
| 実装方法とシステムコール回数 | fork | lseek | mmap | open | close | fstat |
|---|---|---|---|---|---|---|
| ipc_mmap+fork | 1 | 1 | 8 | 2 | 2 | 1 |
| ipc_mmap+mdconfig_malloc-1 | 1 | 0 | 8 | 3 | 2 | 1 |
| ipc_mmap+mdconfig_swap-1 | 1 | 0 | 8 | 3 | 2 | 1 |
| ipc_mmap+tmpfs-1 | 1 | 0 | 8 | 3 | 2 | 1 |
| ipc_mmap+ufs-1 | 1 | 0 | 8 | 3 | 2 | 1 |
| 実装方法とシステムコール回数 | lstat | access | sigprocmask | munmap | read |
|---|---|---|---|---|---|
| ipc_mmap+fork | 2 | 1 | 12 | 1 | 2 |
| ipc_mmap+mdconfig_malloc-1 | 2 | 1 | 12 | 1 | 2 |
| ipc_mmap+mdconfig_swap-1 | 2 | 1 | 12 | 1 | 2 |
| ipc_mmap+tmpfs-1 | 2 | 1 | 12 | 1 | 2 |
| ipc_mmap+ufs-1 | 2 | 1 | 12 | 1 | 2 |
| 表2 truss(1)で計測したシステムコールの呼び出し回数 | |||||
強制的なコンテキストスイッチの回数には次のような差が見られたが、処理時間を加味すると、この差は純粋に処理にかかった時間がそのまま反映されたものだと考えられる。自発的なコンテキストスイッチの切り替えはほとんど発生しておらず、割り当てられた時間を使い切るまで連続して動作し続けている。
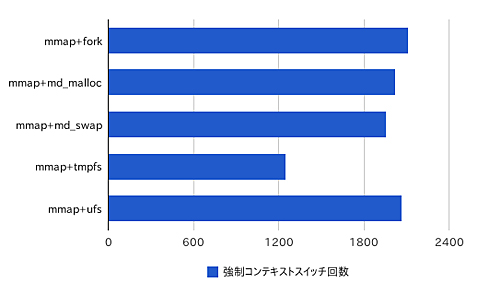 図3 強制コンテキストスイッチの回数
図3 強制コンテキストスイッチの回数| 実装方法 | 自発的コンテキストスイッチ回数 |
|---|---|
| ipc_mmap+fork | 2114 |
| ipc_mmap+mdconfig_malloc-1 | 2026 |
| ipc_mmap+mdconfig_swap-1 | 1961 |
| ipc_mmap+tmpfs-1 | 1250 |
| ipc_mmap+ufs-1 | 2072 |
| 表3 /usr/bin/timeで計測した強制コンテキストスイッチの回数 | |
考察——バックエンドはそれほど影響を与えない?
今回の結果を見る限り、バックエンドがディスクかメモリかといったことはmmap(2)を使ったファイル共有の実行速度という面ではそれほど影響がないことが分かる。ファイルシステムに何を使っているかの方が性能差になっている。
ディスク上のUFSも、mdconfig(8)で作成したメモリファイルシステムUFSも、どちらもnewfs(8)で作成したUFSであり、ファイルシステム上のファイルに対する処理はUFS/VFSの処理を経由して実施される。一方tmpfs(5)はそうしたUFSの処理は経由しないで動作する。この差が、今回の処理速度の差として現れたのではないかと考えられる。
こうした特性を加味すると、mmap(2)を使って処理を高速化した上で、さらに処理を高速化するにはtmpfs(5)との組み合わせがよいということが分かる。マシンに搭載されているメモリ量、共有メモリのサイズ、動作の安定性などほかにも考慮すべきことがあるので簡単にそういい切れるわけではないが、1つの指針としてこのような調査を実施しておくことは有益といえる。
著者紹介

BSDコンサルティング株式会社取締役/オングス代表取締役
後藤 大地
@ITへの寄稿、MYCOMジャーナルにおけるニュース執筆のほか、アプリケーション開発やシステム構築、『改訂第二版 FreeBSDビギナーズバイブル』『D言語パーフェクトガイド』『UNIX本格マスター 基礎編〜Linux&FreeBSDを使いこなすための第一歩〜』など著書多数。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。