Facebook、スケーラビリティを強化したスケジューリングツール「Corona」をオープンソース化:MapReduceの限界を独自開発で解決
データが大きくなりすぎてMapReduceのジョブトラッカーが死亡? そんな課題に対応するため、Facebookはジョブスケジューリングツールをゼロから構築、公開した。
米Facebookはユーザーベースの拡大に伴って生成される大量のデータ処理に対応するため、新しいスケジューリングフレームワークの「Corona」を開発し、11月8日にオープンソースとして公開したことを明らかにした。
Facebookはこれまで、データインフラ基盤としてApache HadoopのMapReduceを採用してきた。しかし、データウェアハウスで生成されるデータが24時間あたり0.5ペタバイトを超え、Hiveクエリの処理は1日当たり6万を超える中で、2011年初めごろからMapReduceのスケーラビリティが限界に達し始めたという。
MapReduceではジョブトラッカーが割り当てるタスクをタスクトラッカーが実行する仕組みになっているが、クラスタサイズとジョブの数が増えるに従い、ジョブトラッカーが作業を適切に処理できなくなり、負荷がピークに達するとスケジューリングのオーバーヘッドによってクラスタの利用率が激減してしまう問題が発生した。
さらに、プルベースのスケジューリングモデルの限界や、静的なスロットベースのリソース管理モデルの制約にも突き当り、ソフトウェアアップデートの間は実行中のジョブを全て中断するダウンタイムが必要とされることも問題になっていた。
こうした状況を改善するために開発された「Corona」は、クラスタリソース管理をジョブコーディネーションと切り離す設計にしている。Coronaのクラスタマネージャは、クラスタ内のノードとフリーなリソースの量を把握することのみを目的とし、個別のジョブごとに専用のジョブトラッカーを作成。小さなジョブではクライアントと同じプロセスで、大きなジョブの場合はクラスタ内の別のプロセスとして実行できるようにした。
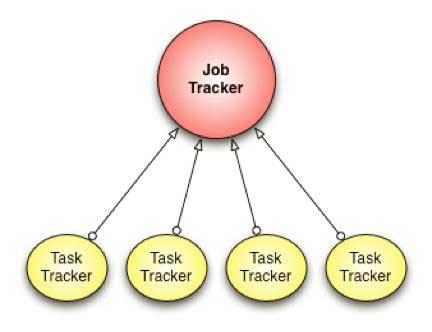 MapReduceにおけるジョブスケジューリングの概念図(Facebookエンジニアリングチームの発表より)
MapReduceにおけるジョブスケジューリングの概念図(Facebookエンジニアリングチームの発表より)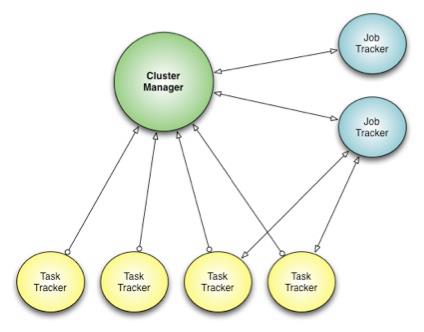 Coronaにおけるジョブスケジューリングの概念図(Facebookエンジニアリングチームの発表より)
Coronaにおけるジョブスケジューリングの概念図(Facebookエンジニアリングチームの発表より)さらに、プルベースではなくプッシュベースのスケジューリングを採用したことなどにより、Coronaではスケーラビリティの強化、遅延解消、ダウンタイムなしのアップグレード、リソース管理の向上という目標を達成したとしている。また、ジョブのリスタートの高速化、コードベースのスリム化、他のシステムとの連携といった機能も実現できたという。
MapReduceとCoronaを比較すると、クラスタの利用率は70%から95%強に向上し、テストジョブの遅延は50秒から25秒に半減しているという。現在、CoronaはFacebookのデータインフラに組み込まれており、全社でビッグデータ分析に活用されているという。
関連記事
 過去の負荷動向も検証可能:Hadoop/HBaseの内部動作を可視化するソフトウェア「halook」をOSSで公開
過去の負荷動向も検証可能:Hadoop/HBaseの内部動作を可視化するソフトウェア「halook」をOSSで公開
Hadoop内部の負荷状況などをグラフィカルに表示するOSSツールが登場。Javaプログラム解析ツールを流用し、HTML5などを駆使して内部の挙動を可視化する SQLライクなクエリがHiveの10倍速に:ClouderaがHadoop用リアルタイムクエリエンジンを発表
SQLライクなクエリがHiveの10倍速に:ClouderaがHadoop用リアルタイムクエリエンジンを発表
Hadoop用のリアルタイムクエリを高速に実現するプロダクトがApacheライセンスで登場。リアルタイムデータクエリとBI的な利用を両立させる手法に選択肢が広まる Hadoopアプリケーションのパフォーマンス最適化:Compuware APM Dyna Trace Enterprise for Hadoopが新価格を発表
Hadoopアプリケーションのパフォーマンス最適化:Compuware APM Dyna Trace Enterprise for Hadoopが新価格を発表
日本コンピュウェアは2012年10月22日、Apache Hadoopアプリケーションのパフォーマンスを最適化する「Compuware APM Dyna Trace Enterprise for Hadoop」について、1台あたり1000USドルという新価格を発表した 知らないなんて言えないNoSQLまとめ(1):KVS系NoSQLのまとめ(Hibari、Dynamo、Voldemort、Riak編)
知らないなんて言えないNoSQLまとめ(1):KVS系NoSQLのまとめ(Hibari、Dynamo、Voldemort、Riak編)
エンジニアとして「知らない」とは言えない空気が漂うNoSQL界隈……。いろいろあるけども何がどう違うのか、主要プロダクトの特徴をコッソリ自習しよう。第1回はKVS系NoSQLの中から、マスタ型、P2P型に分類されるものを紹介していく。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。