Cでポピュラーな脆弱性とバッファオーバーフロー(前編):もいちど知りたい、セキュアコーディングの基本(2)(1/2 ページ)
連載の第2回では、Cアプリの脆弱性として頻繁に耳にする「バッファオーバーフロー」の基礎知識と対策の考え方を復習します。
セキュアコーディングに関する事例や対策をお届けするこの連載。第1回の「なぜ、いま『セキュアコーディング』なのか?」に続く第2回は、Cアプリの脆弱性として頻繁に耳にする「バッファオーバーフロー」について取り上げます。
これまでに多くのアプリケーションにおいて、攻撃されたり発見されたりしている、しかもいまだになくならないバッファオーバーフロー問題ですが、その仕組みや原理を理解していなければ、具体的な対策も難しいと思います。そこで、この連載では、あらためてこの問題について掘り下げます。
今回のバッファオーバーフロー前編では、バッファオーバーフローの基礎知識と対策の考え方を復習します。次回、バッファオーバーフロー後編では、過去に発見され、修正された脆弱性の実例を紹介します。
ソフトウェアに多い脆弱性とは
ソフトウェアに作り込みやすい脆弱性にはどのようなものがあるのでしょうか? その疑問に答えてくれる資料があります。以下の、「CWE/SANS最も危険なプログラミングエラーTop25」です。
「CWE/SANS Top 25 Most Dangerous Software Errors」
http://www.sans.org/top25-software-errors/
なおこの資料は、現在2011年版が出ていますが、2009年版については以下のURLから日本語で読むことができます。
http://www.sans.org/top25-software-errors/2009/top25_japanese.pdf
この「Top 25」は、さまざまなソフトウェアに見られるエラーの中から、悪用のしやすさやコードレビューによる問題部分の見つけにくさなど、いくつかの観点から危険性が高いと考えられるソフトウェアエラーを25種類選び出したものです。これらは大きく3つに分類されています。
- Insecure Interaction Between Components(6 errors)
- ソフトウェアコンポーネント間のセキュアでないやりとり
- SQLインジェクションやクロスサイトスクリプティング(XSS)のような類の脆弱性
- Porous Defenses(11 errors)
- 不完全な防御策
- 認証関連の不備や暗号化機能の不適切な使い方など
- Risky Resource Management(8 errors)
- リソース管理の問題
- バッファオーバーフローや整数オーバーフロー、書式指定文字列の脆弱性など
1つ目に分類されているSQLインジェクションやXSS(クロスサイトスクリプティング)などは、やりとりされる情報の意味がコンポーネント間で変わることから問題が発生するパターンです。
例えば、入力データからSQL文を組み立てるコンポーネント、そのSQL文を受け取ってデータベースから必要なデータを抽出するコンポーネントの2つがあるとします。入力データの中にシングルクオートや '%' のような特殊文字が含まれている場合を考慮せずにSQL文を組み立てている場合、もともとのソフトウェアの意図とは異なる構造のSQL文を生成して後段のコンポーネントに渡してしまう可能性があります。
2つ目の不完全な防御策というのは、ユーザー認証が適切に行われていなかったり、暗号化などによって重要な情報を保護しているつもりで保護できていない、というパターンです。
ユーザー認証機能の実装に問題があって認証を迂回することが可能だったり、動作テスト用のパスワードをコードに埋め込んだままにしてあって誰でも容易にログインできる、というような状態だと、ユーザー認証が意味をなさなくなってしまいます。また、重要な情報の暗号化に使ったアルゴリズムが実は容易に解読できる弱いものだったり、復号のための鍵が誰でもアクセスできるようになっていると、暗号化する意味がなくなってしまいます。
3つ目のリソース管理の問題は、用意したメモリ領域の大きさが十分でないのにデータをコピーしたり、そもそも必要なサイズを計算した結果が想定外の不適切な値になったりするパターンです。書式指定文字列を外部から指定できる場合や、操作するファイルを適切に制限できていないパストラバーサルの問題なども含まれます。
これらのカテゴリの中でC言語に特徴的な問題が目立つのは、3つ目の「リソース管理の問題」でしょう。C言語ではLispやJavaのような言語と違って、メモリ管理が全てプログラマに任されているため、適切なメモリ管理をしなければバッファオーバーフローの問題につながります。また、C言語における型や整数演算に関する規則を正しく理解しないままコーディングしていると、整数オーバーフローの問題を作り込んでしまう危険があります。
以下、まずはバッファオーバーフローについて見ていきましょう。
バッファオーバーフローとは
プログラムで何らかのデータを処理する場合、処理すべきデータや処理した後のデータを保持するためのメモリ領域が必要になります。これが「バッファ」です。
ユーザーの入力したテキストを一文字ずつ処理したり、圧縮された画像データを伸長したり、といった処理を行うコードでは、処理対象となるデータを保持するためのメモリ領域を、関数のローカル変数として用意したり、malloc()関数を使ってヒープメモリから割り当てたりします。
重要なことは、Cのコード上、これらのメモリ領域は固定長でしか記述できないということです。処理の途中で倍のサイズが必要になったからといって、勝手にサイズを倍にしてくれるような便利な仕組みはありません。必要であれば、倍のサイズのメモリ領域を確保し、データを移し替えて処理を続けるような仕組みを自分で実装する、それがC言語です。
この固定長であるメモリ領域にデータをコピーする際、用意された領域の外まで書き込みを行ってしまうことを「バッファオーバーフロー」といいます。
具体的にバッファオーバーフローが発生する可能性があるコード例を見てみましょう。
char *
gets(char *buf)
{
int c;
char *s;
for (s = buf; (c = getchar()) != '\n'; )
if (c == EOF)
if (s == buf){
return (NULL);
} else
break;
else
*s++ = c;
*s = '\0';
return (buf);
}
コード例1は、OpenBSDの標準ライブラリにある関数gets(3)の関数定義を簡単にしたもので、バッファオーバーフローを起こす典型的なコード例です。このコードがやっていることを日本語に書き下してみると次のようになります。
- 標準入力から(getchar()を使って)入力データを読み取る
- 読み取ったデータをbufが指すメモリ領域に書き込む
- 入力データの読み取りは改行文字('\n')が出現するかEOF(入力データがなくなる)まで続く
- 入力の読み取りが終わった後、最後にnull終端文字を付け加える
ここから、このコードは以下の前提の下に書かれていることが分かります。
[gets() 実行時の前提条件]
- 引数 buf が指しているバッファは、入力データ(およびその後ろに付けるnull終端文字)を全て収めることのできる大きさであること
この前提条件が満たされていない場合、バッファオーバーフローが発生します。具体的には、標準入力から読み込むデータが用意されたバッファのサイズを上回ると、バッファの後ろのメモリ領域にはみ出してデータを書き込んでいくことになります。
では、バッファオーバーフローが発生すると何が起こるのでしょうか?
バッファオーバーフローの影響
例えば関数の内部で宣言されるローカル変数(自動変数)を考えてみましょう。
通常、ローカル変数はスタック上に配置されます。その変数への書き込みでバッファオーバーフローが発生した場合、隣に配置されているオブジェクトの値が上書きされることになります。
隣に配置されているオブジェクトとしては、ローカル変数、関数呼び出し時の実引数、関数呼び出しのときに退避されたレジスタの内容、関数の呼び出し元への飛び先アドレス、などがあります。これらの値が上書きされることで、関数の動作が変わったり、正しい呼び出し元に戻るつもりで別のコードに飛んでしまう可能性があります。スタック上のメモリ領域でバッファオーバーフローが発生するため、「スタックバッファオーバーフロー」と呼ぶこともあります(注1)。
注1:「バッファ」を省略して「スタックオーバーフロー」としてしまうと、別の現象を意味する言葉になってしまいますので気を付けましょう。
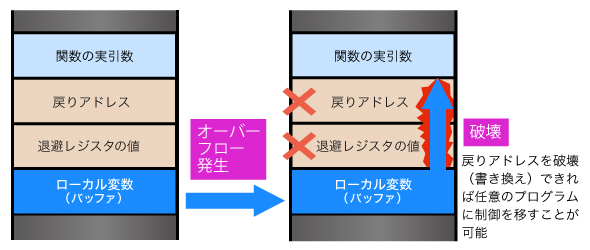 図1 スタックバッファオーバーフロー
図1 スタックバッファオーバーフローヒープ領域に配置された変数への書き込みでバッファオーバーフローが発生した場合はどうでしょうか。
ヒープ領域は通常、小さいメモリブロックの集まりとして管理されます。メモリブロックのサイズなど管理のための情報も一緒にメモリ上に置いてあるため、バッファオーバーフローが発生すると、それら管理のための情報が上書きされる可能性があります。どのような管理情報がどのような値で上書きされるかによって挙動が変わってきますが、アクセス違反でプロセスが強制終了させられたり、メモリの別の領域の書き換えにつながったりすることもあります。
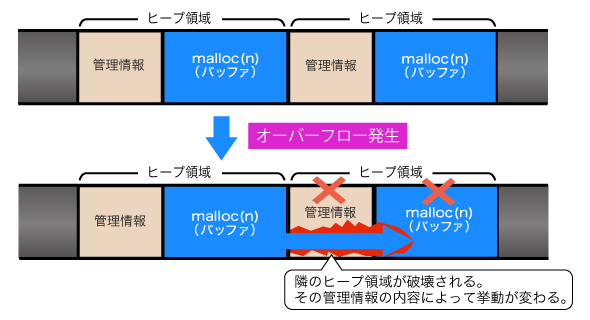 図2 ヒープバッファオーバーフロー
図2 ヒープバッファオーバーフローヒープ領域におけるバッファオーバーフロー、すなわち「ヒープバッファオーバーフロー」の影響を考えるには、動的メモリの管理手法をある程度理解しておく必要があります。本連載で動的メモリ管理について取り上げる際により詳しく説明したいと思います。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。