ドキュメント指向のNoSQLデータベース(CouchDB、MongoDB)編:知らないなんて言えないNoSQLまとめ(5)(2/2 ページ)
RDBとKVSの溝を埋めるMongoDB
MongoDBはオープンソース・プロジェクトですが、10gen(テンジェン)が後ろ盾となって支援をし、商用サポートを提供しています。
MongoDBの狙いは、「高速で拡張性の高いキー・バリューストアと、リッチな機能を持つ伝統的なRDBの隙間を埋めることだ」と位置づけられています。
マスタ・スレーブ型とレプリカセットによる複製
MongoDBは、マスタ・スレーブ型で複製を保持します。書き込みは常に1台のマスタに対してのみ行われ、スレーブとなる複数のサーバに非同期で複製を作り、読み出しは常にスレーブから行います。
このマスタ・スレーブ型に加え、リリース1.6から「レプリカセット」という新方式が提供されました。レプリカセットでは、プライマリ役とセカンダリ役のサーバがあり、通常はプライマリ側からセカンダリ側に対して複製を行います。プライマリ側に障害などが生じた場合には、調停ノードがセカンダリの中から次のプライマリを決定し、その役割を引き継がせることで、フェイルオーバーと復旧を自動化します。
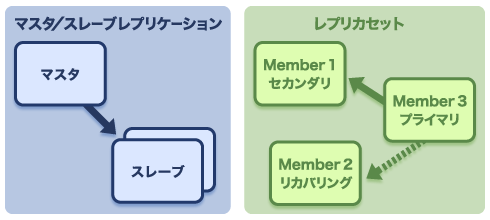 図1 MongoDBの複製
図1 MongoDBの複製結果整合性を保証
MonogoDBは、マスタ(プライマリ)ノード単体の場合には、読み書きを1つのノードで行うため強い整合性を保証します。しかし、スレーブ(セカンダリ)に非同期で複製を行う場合には、マスタに書き込み、スレーブから読み出すので、結果整合性となります。
本書の説明は、ビッグデータに対するNoSQLデータベースの適用を前提としており、ノード障害時のデータ消失を防ぐためにレプリケーション機能が実装されていることを想定しているので、MongoDBは結果整合性であると位置づけることにします。
自動シャーディングによるデータ分割
MongoDBのデータ分割はシャーディング*4により行います。MongoDBでは、ドキュメントの集まりを「コレクション」と呼びます。コレクションにはシャード・キーが割り当てられ、そのキーに基づいて複数のサーバにデータが分割されます。このシャード・キーは順番を保持しており、隣接したシャード・キーはたいてい同じサーバに保持されます。
コレクションの連続した範囲を「チャンク」と呼びます。チャンクの集まりは「シャード」と呼ばれ、あるシャードのデータサイズが大きくなった場合には、このチャンク単位で、データの分割や移動が自動で行われます。レプリカセットはこのシャードを構成するプライマリとセカンダリのサーバ間で行われます。
*4 シャーディング 本連載第3回 注2を参照ください。
定期的にディスクにフラッシュして永続化
MongoDBでは、メモリ上のデータをディスクにフラッシュする仕組みをfsyncと呼び、これによってデータを永続化します。fsyncのタイミングはデフォルトで60秒ごとです。
また、バージョン1.7.5からは「ジャーナル」と呼ばれるCommit Logに近い機能が搭載されましたが、ディスクへの書き込みがデフォルトで 100ミリ秒ごとになっており、その間にサーバの電源が落ちるなどした場合には書き込み前のデータが消失する可能性があります。
バージョン管理は“Last one wins”方式
MongoDBは、バージョン管理にベクタークロック*5を用いません。システム内のバージョン間に差異が生じた場合には、Last one wins、すなわち「最後に更新されたバージョンが勝つ」というルールを適用しています。
豊富な機能
MongoDBにはMapReduceを適用できます。また、GridFS*6という仕組みでラージオブジェクトをサポートし、さらにMySQLのようなインデックス機能も搭載しています。
*5 ベクタークロック 本連載第1回 注5を参照。
*6 GridFS MongoDBに巨大なファイルを格納するためのソフトウェアです。MongoDBはバイナリデータの格納をサポートしていますが、そのサイズは4MBに制限されています。GridFSでは大きなファイルを複数のドキュメントに自動的に分割することで、MongoDBに効率的に格納したり、「ファイルの途中にあるNバイトを取得する」といった操作を効率的に扱うことができます。
まとめ
本連載では、データモデルとアーキテクチャの組み合わせに基づき、主要なNoSQLデータベースを説明しました。以下にあらめてまとめておきましょう。
- データモデルからは、NoSQLデータベースをキー・バリュー(KVS)型、イネーブラ型、カラム指向型、グラフ型、ドキュメント指向型の4つに分類し、アーキテクチャからはマスタ型とP2P型に分類しました。これらの組み合わせに沿って、代表的な15製品の概要と特徴を個別に説明しています。
- マスタ型のKVSであるHibariは、チェインレプリケーションという独自アーキテクチャにより「強い整合性」を保証しています
- P2P型のKVSであるAmazon Dynamoは、可用性を重視した「結果整合性」ですが、Dynamoの設計を参考に実装されたVoldemortとRiakはQuorumにより整合性が調整可能です。いずれもノードを追加することでスケールアウトする拡張性を有し、ハードディスクにデータを保存することでデータを永続化します
- キーバリュー型において高速化を求めたオンメモリタイプの製品は、サーバの故障や電源が落ちるなどした際にデータが消失してしまうので、データの永続性を確保するために、他のNoSQLデータベースと組み合わせることで、その利用が促進されます。こうした特性から、イネーブラ型オンメモリタイプとして類型化できます
- 連載ではイネーブラ型オンディスクタイプとして、TokyoCabinet/Tyrantを紹介しました。ハードディスクへの書き込みが可能でデータの永続性をサポートしますが、拡張性がなく、TokyoCabinet/Tyrantは他のNoSQLデータベースとともに利用されています
- カラム指向型は、GoogleのBigTableに触発された、カラムを動的に追加できるデータモデルを採用しています。マスタ型のHBaseとHypertableは「強い整合性」を保証し、P2P型のCassandraは、Quorumによる整合性の調整が可能です。いずれも拡張性と永続性を有し、永続化にLSM-Treeを採用したことで高い書き込み性能を実現しています
- グラフ型は、データとデータの関係性をグラフとして表現するのに最適です。この関係性をRDBで表現するためには、テーブル間の関係性を定義する必要があり、また処理にも時間がかかります。ドキュメント指向型でも関係性を表現することはできますが、アプリケーション側で行う必要があります。グラフ型はそれをデータベース側で実現できます
- ドキュメント指向型は、ドキュメント形式でデータモデルを作ることができることから、Webサービスにおいて特に便利に利用できます。ただし、データ分割や複製に関しては、キーバリュー型やカラム指向型で紹介したような特性を有していないため、ビッグデータ対応というよりは、使いやすさに優れたNoSQLデータベースだといえます
◇ ◇ ◇
連載を通読いただければ、世に多数あるいわゆる「NoSQL」のそれぞれの長所・短所や、組み合わせた活用のアイデアが浮かぶのではないでしょうか? 本稿が皆さんの日々の企画や開発のヒントになると幸いです。
初出情報
本連載で抜粋・紹介している原稿の初出は下記書籍です。本連載では詳述していないNoSQLの基本的な考え方、アーキテクチャの詳細などは、書籍でご確認ください。
『NOSQLの基礎知識』
- 【著】 本橋信也、河野達也、鶴見利章
- 【監修】太田洋
- 【発行】リックテレコム
- 【ISBN】978-4-89797-887-1
本書はクラウディアン(旧ジェミナイ・モバイル・テクノロジーズ)の技術者らが監修および執筆を行っています。同社は、国産NOSQL「HIBARI」を開発、その後、Cassandraに自社の「HyperStore」を実装したクラウドストレージ用パッケージソフトウェア「Cloudian」を開発して、現在商用提供を行っているITベンチャー企業です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。