Webの全てをデータベースにするLinked Open Data(LOD)とクエリ言語SPARQLの基礎:データ資源活用の基礎(3)(2/3 ページ)
オープンデータをLinked Open Dataにするには?
オープンデータをLODとするためには、データを他のデータとリンクさせる必要があります。他のデータとリンクさせるには、データを記述する際に、URIに他のデータで使用されているURIを使用したり、他のデータで使用されているURIと関連付けたりする方法があります。
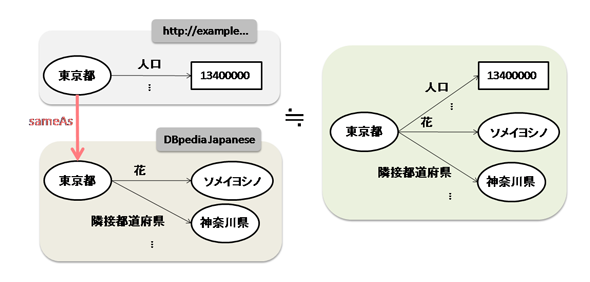
例えば、DBpedia Japanese のURIはよく使用されるURIの一つです。これまでの説明で使用した「東京都」を表すURI(http://example/prefectures/tokyo)がDBpedia Japaneseの東京都(http://ja.dbpedia.org/resource/東京都)と同一である場合は、次のように記述することで、リンクできます。ここでは、述語に同一であることを表すプロパティ「owl:sameAs」を使用します。
1: @prefix owl: <http://www.w3.org/2002/07/owl#>. 2: <http://example/prefectures/tokyo> owl:sameAs <http://ja.dbpedia.org/resource/東京都>.
上記のように定義することで、データをリンクさせることができます。こうすることで、下図にあるように、人口や隣接都道府県といった「他のURIの情報として記述されている情報」を、同一の「東京都の情報」として扱うことができるようになります。
RDFデータの検索:SPARQLによるクエリ
RDFデータの検索にはW3C標準のクエリ言語SPARQL Protocol and RDF Query Language(SPARQL)(注3)を使用します。
注3 上綱 秀治氏によるW3Cのドキュメント和訳「RDF用クエリ言語SPARQL」(http://www.asahi-net.or.jp/~ax2s-kmtn/internet/rdf/rdf-sparql-query.html)を参照。
SPARQLクエリの基本
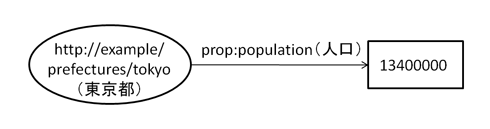
まず、RDFデータの説明で使用した東京の人口のデータに対する検索を例にSPARQLによるクエリの基本を紹介します。
1: @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>. 2: @prefix prop: <http://example/properties/>. 3: <http://example/prefectures/tokyo> prop:population 13400000.
例えば、上記の検索対象データ(http://example/data/)に対して、「都道府県のURIと人口」を求めるSPARQLクエリは下記の記述になります。
1: PREFIX prop: <http://example/properties/>
2: SELECT ?prefecture ?population
3: FROM <http://example/data/>
4: WHERE{ ?prefecture prop:population ?population. }
1行目は名前空間の定義、2行目はSELECT句、3行目は検索対象のデータの指定、4行目はWHERE句です。
SPARQLクエリにはSELECT句とWHERE句の2つが必須です。WHERE句には取得したいグラフパターンを指定し、SELECT句にはWHERE句内で使用されている変数のうち、取得したい値を参照する変数を指定します。
グラフパターンは、変数を用いたトリプルと条件文から構成されます。また、変数はクエスチョンマーク(?)で始まる文字列を用いて表します。この例のWHERE句では、主語を「?prefecture」(変数)、述語を「prop:population」(人口を表すプロパティ)、目的語を「?population」(変数)としたトリプルを用いたグラフパターンを指定しています。このグラフパターンを図で書くと次のようになります。

上記の検索対象データに対し、このグラフパターンを用いて検索を行うと、「?prefecture」は都道府県のURIの値を参照し、「?population」は人口の値を参照します。このクエリでは都道府県のURIと人口を求めるため、SELECT句ではその2つの変数を指定しています。また、FROM句を用いて検索対象のデータを指定しない場合は、登録されているデータ全体が検索対象となります。
検索対象データに対して、上記のSPARQLクエリを用いると、次のようなグラフとマッチし、下記の検索結果が得られます。
| prefecture | population |
|---|---|
| http://example/prefectures/tokyo | 13400000 |
その他に、よく使用される機能を紹介します。1つ目は「DISTINCT」です。SELECT句内で使用することで、重複する結果を削除することができます。
2つ目は「ORDER BY」です。WHERE句の後に、任意の変数と順序を指定して付与することで、結果の出力順を指定することができます。昇順の場合は「ORDER BY ASC」、降順の場合は「ORDER BY DESC」を使用します。
また、「LIMIT」もよく使われます。WHERE句の後に、任意の数値を指定して付与することで結果の数を指定できます。下記のクエリにより、人口TOP10の都道府県のURIと人口を取得することができます。
1: PREFIX prop: <http://example/properties/>
2: SELECT DISTINCT ?prefecture ?population
3: FROM <http://example/data/>
4: WHERE{ ?prefecture prop:population ?population. }
5: ORDER BY DESC(?population)
6: LIMIT 10
その他にも、「GROUP BY」や「FILTER」、集約関数などが用意されています。例えば、「GROUP BY ?x」のように任意の変数を指定して使用することで、変数?xごとにグループとしてまとめることができます。また、「FILTER」を用いて変数の値を指定することができます。集約関数には、「COUNT」や「SUM」、「AVERAGE」などがあります。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。