Hadoop偼乽擄偟偄丒抶偄丒巊偊側偄乿丠 墇偊傜傟側偄暻偑偁傞棟桼偲懪奐嶔傪惍棟偡傞丗揮姺婜傪寎偊傞Hadoop乮1/2 儁乕僕乯
僽乕儉偩偭偨Hadoop丅偱傕幚嵺偵偼傾乕儕乕傾僟僾僞乕埲奜偵偼丄埖偄偵偔偔偰晛媦偑恑傑側偄偺偑尰忬偩丅偦偺壽戣偵婔偮偐偺夝寛嶔偑弌偰偒偨丅揮姺婜傪寎偊傞Hadoop傪傔偖傞忬嫷傪惍棟偟傛偆丅
丂價僢僌僨乕僞偺怽偟巕偺傛偆偵憶偑傟偨乽Hadoop乿丅埲慜傎偳儊僨傿傾傪憶偑偣偰偼偍傜偢丄偦傟傎偳峀斖埻偵晛媦偟偨傛偆偵傕巚偊側偄傕偺偺丄偄傑偩拲栚偝傟傞偵傆偝傢偟偄懚嵼側偺偼娫堘偄偁傝傑偣傫丅偟偐偟丄崱擔偺丄偁傞偄偼偙傟偐傜偺Hadoop偑偳偺傛偆偵恑壔偟偰偄傞偺偐傪抦傟偽丄Hadoop傪掹傔偰偄偨曽乆傕嵞搙拲栚偟傛偆偲巚傢傟傞偺偱偼側偄偱偟傚偆偐丅
偦傕偦傕Hadoop偲偼乧乧丠 偺慣栤摎偭傐偝
丂撍慠偱偡偑丄乽Hadoop偲偼壗偱偡偐丠乿偲愢柧傪媮傔傜傟偨傜丄奆偝傫側傜偳偆摎偊傑偡偐丠
Q.乽Hadoop偲偼壗偱偡偐丠乿
Ans.
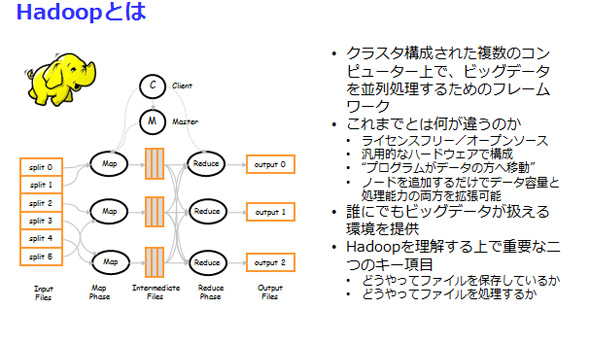
- 暋悢偺僒乕僶乕偱峔惉偝傟丄MapReduce偲屇偽傟傞巇慻傒偱暘嶶張棟傪峴偆娐嫬偱偁傞偙偲
- 僨乕僞傕嫟桳僗僩儗乕僕偱偼側偔丄奺僒乕僶乕偺撪憼僨傿僗僋偵暘嶶偟偰奿擺偝傟傞偙偲
- HDFS偲屇偽傟傞撈帺偺僼傽僀儖僔僗僥儉偑偁傝丄僨乕僞偺暘嶶偵偮偄偰偼帺摦揑偵峴傢傟傞偙偲
- 僨傿僗僋傗僒乕僶乕偺忈奞偵旛偊偰丄3僇強偵僐僺乕偑懚嵼偡傞偙偲
丂巹側傜偙偺傛偆偵愢柧偟傑偡偑丄偙傟偱偼晄懌偟偰偄傞偲傕偄偊傑偡偟丄嵟弶偺愢柧偲偟偰偼廫暘偩偲傕偄偊傞偱偟傚偆丅
丂偄偢傟偵偟偰傕丄偄偞偙偺愭傪棟夝偟傛偆丄幚嵺偵娐嫬傪峔抸偟偰傒傛偆偲側傞偲丄撍慠僴乕僪儖偑忋偑偭偰偟傑偆丅偦傫側僀儊乕僕傪昅幰偼帩偭偰偄傑偡偑丄偙偺楢嵹傪撉傒恑傔傞偵摉偨偭偰偼丄忋婰偑暘偐偭偰偄傟偽廫暘偱偡丅
丂傓偟傠丄偦傟埲忋傪媮傔傜傟偰嵙愜偟偰偟傑偆乮偟傑偭偨乯曽偨偪偵偙偦丄偄傑揮姺婜傪寎偊偰偄傞Hadoop傪抦偭偰偄偨偩偒偨偄偺偱偡丅
Hadoop偼壗傪揮姺偟傛偆偲偄偆偺偐
丂抋惗偟偰傢偢偐悢擭偲偼偄偊丄奼戝偲恑壔傪懕偗傞Hadoop偵偲偭偰丄戝偒側壽戣偑偄偔偮偐嫇偘傜傟傑偡丅崱夞偼丄庡偲側傞嶰偮偺壽戣偺偆偪擇偮傪庢傝忋偘偰丄偳偺傛偆偵揮姺婜傪寎偊偰偄傞偺偐傪徯夘偟傑偡丅巆傞堦偮偵偮偄偰偼師夞丄徻偟偔徯夘偟傑偡丅
1丗HDFS偑廬棃偺僼傽僀儖僔僗僥儉偲斾傋偰埖偄偯傜偄
丂Hadoop偱棙梡偡傞HDFS偼丄Linux傗Windows側偳偱堦斒偵梡偄傜傟傞僼傽僀儖僔僗僥儉偲偼堎側傞偨傔丄偦偙偵偁傞僼傽僀儖傪婛懚偺僣乕儖偐傜偼撉傒彂偒偱偒傑偣傫丅
丂廬偭偰丄Web僒乕僶乕偵偨傑偭偨儘僌偵偟偰傕丄僨乕僞儀乕僗偵拁偊傜傟偨僨乕僞偵偟偰傕丄Hadoop偱埖偆偨傔偵偼僼傽僀儖偺堏摦傑偨偼僐僺乕偲偄偆柺搢偑敪惗偡傞偺偱偡丅偦傟傕丄堦斒揑側僼傽僀儖僐僺乕偺曽朄偑巊偊傞傢偗偱偼側偔丄HDFS撈摿側API傪屇傃弌偡曽朄偱峴傢側偔偰偼側傝傑偣傫丅
丂戝梕検偺僨乕僞傪丄埨偔丄偟偐傕崅偄壜梡惈偱庢傝埖偆偙偲傪桪愭偟偨寢壥偱偼偁傞偺偱偡偑丄堦斒偵庴偗擖傟傜傟傞偵偼壽戣偲側傝傑偟偨丅偨偄偰偄偺応崌丄Hadoop偵偄偒側傝僨乕僞偑拁偊傜傟傞偺偱偼側偔丄偳偙偐偐傜帩偭偰偔傞偱偟傚偆偐傜丄偙偆偟偨庤娫偲帪娫偑偐偐傞偙偲偼Hadoop傪巊偄偯傜偄偲昡壙偡傞梫場偲側偭偨偺偱偡丅
丂偙偺揰偵偮偄偰偼丄Hadoop傪惢昳壔偟偰桳彏偱採嫙偡傞儀儞僟乕偺拞偵偼丄撈帺偺僼傽僀儖僔僗僥儉傪採嫙偟偰夝寛傪恾偭偰偄傞傕偺偑偁傝傑偡丅戙昞揑側椺偲偟偰偼丄IBM偺BigInsights偑採嫙偡傞GPFS-FPO丄偁傞偄偼MapR偑採嫙偡傞僼傽僀儖僔僗僥儉偑嫇偘傜傟傑偡丅偦傟傜傪巊偊偽丄堦斒揑側僼傽僀儖僔僗僥儉偲摨條偺憖嶌惈傪庤偵擖傟傜傟丄壽戣傪夝寛偱偒傑偡丅
2丏MapReduce張棟偑抶偄丄埖偄偯傜偄
丂僼傽僀儖僔僗僥儉偺栤戣偩偗偱側偔丄娞怱偺MapReduce偵偮偄偰傕丄偦偺埖偄偯傜偝偲張棟偺抶偝偑巜揈偝傟傞偙偲偑偁傝傑偟偨丅
丂埖偄偯傜偝偼丄MapReduce偺僼儗乕儉儚乕僋傗API偵懳偡傞姷傟偺栤戣傕戝偒偔丄僾儘僌儔儈儞僌偺宱尡傪愊傓偙偲偱夝徚偡傞柺傕偁傝傑偡丅偟偐偟丄張棟偺抶偝偵偮偄偰偼僠儏乕僯儞僌偺梋抧側偳傕側偔丄夵慞傪婜懸偡傞惡偑懡偔偁傝傑偟偨丅幚嵺栤戣丄MapReduce偼Java偱彂偐傟偰偄傞偙偲傕庤揱偭偰丄偁傞偄偼戝婯柾側僨乕僞傪僶僢僠張棟揑偵埖偆慜採偱偁傞偑備偊偵丄偄偔偮傕偺僆乕僶乕僿僢僪偑偁傞偺偱偡丅
丂偙傟偵偮偄偰傕丄桳彏偱Hadoop傪惢昳偲偟偰採嫙偡傞儀儞僟乕奺幮偼丄撈帺偵C尵岅偱彂偐傟偨傕偺偲抲偒姺偊傞側偳偺岺晇傪偟偰偒傑偟偨丅傑偨丄僆乕僾儞僜乕僗偺僾儘僕僃僋僩偲偟偰傕丄YARN傗MR2乮MapReduce Version2乯丄偼偨傑偨Spark側偳丄偙偺栤戣傪夝徚偡傞庢傝慻傒偑妶敪偵峴傢傟偰偄傑偡丅摿偵YARN偑捛壛偝傟偨Hadoop偼丄Hadoop 2.x宯偲屇偽傟偰偄偰丄傑偝偵戝偒側揮姺揰偲側偭偨偺偱偡丅
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅