LODとして統計データを扱えると、どうなる?:データ資源活用の基礎(4)(1/3 ページ)
Linked Open Dataの形式でデータが扱えると、何ができるようになる? RDFという知られた技術を軸に、多様な可能性が見えてくる。
はじめに
第3回では、オープンデータの目指す世界である「Linked Open Data」(LOD)を実現するための要素技術として、データモデルとそのモデルを用いたデータに対する検索方法を紹介しました。
第4回の今回は、LODとして公開が進められているRDFを用いた統計データについて紹介します。具体的には、まず統計データをRDFで表すメリットを紹介し、その後、統計データをRDFで表すために用いる語彙(ごい)と、それを用いたRDF化の方法、統計RDFデータに対する検索方法について説明します。
統計データをRDF化する利点は何か?
国勢調査など、政府が行う調査活動の結果は、表形式にまとめられ、既存の表計算ソフトウェアの形式(ExcelやCSVなど)で公開されています。表形式は一覧性に優れ、人にとっては扱いやすい形式ですが、絞り込みや、集計、統合といった二次加工を行うためには、人が表を見て、そのデータ構造を理解し、再加工する必要があります。
このように、これまでは、表形式のデータ構造を統一的に表す方法がなく、使用語彙も統一されていなかったため、機械によるデータの再利用性に欠けていました。例えば、同一のデータが異なる表構造で表されている場合もあれば、「従業者数」を「従業員数」と書く場合もあります。これらも、人が見れば、同一であることが分かりますが、異なる表の間で統合を行う際にはその対応付けの手間が問題となります。
このような問題を解決するのが、統計表のRDF化です。RDFの設計の背後には、モデル、意味論が明確に存在するため、誤解の余地がなく、厳密な機械処理が可能になります。また、RDFでは、三つ組みの要素(トリプル)である、(1)主語、(2)プロパティを必ず識別可能なURIで記述し、(3)目的語も可能な限りURIで記述します。
既に定義されている標準のURIを使うことで、語彙の不一致という問題も解決することができます。また、語彙間の関係を定義したオントロジを用いれば、高度な推論も可能になります。さらに、URIを介して、他で公開されているオープンデータとの連携も容易になります。例えば、組織Aの統計表では東京都の人口しか公開されていなくても、組織Bの統計表で面積が公開されていれば、これらを「東京都のURI」で統合して人口密度を計算することができます。このように、さまざまなデータの関係を組織を超えて関連付けられるため、政府や市区町村のデータと民間のデータを組み合わせるなど、組織の枠にとらわれないデータの連携が可能になります。
統計データのRDF化
統計表のRDF化にもいくつかの方法がありますが、ここでは、RDFデータキューブ語彙(参考文献1)を用いたRDF化を紹介します。
表1は関東地方の年度別人口を表す統計表です。RDFデータキューブ語彙を用いたRDF化では、表の各セルを“観測”とみなして、観測ごとにRDF化を行います。
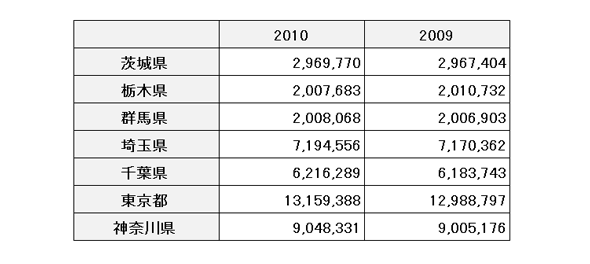 表1 関東地方の人口(データは総務省「国政調査」より引用)
表1 関東地方の人口(データは総務省「国政調査」より引用)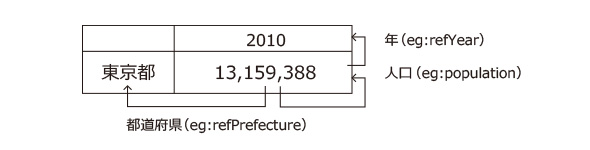 図1 「東京都の2010年の人口」を表す部分
図1 「東京都の2010年の人口」を表す部分例えば、表1の7行2列目のセルは「東京都の2010年の人口」という観測を表しています。図1はその観測に関する部分のみを抽出したものです。
RDF化のために、この観測に「eg:dataset-01-00006」というURIを付けます。セル内の数字は人口を観測した値ですので、まず、「東京都の2010年の人口」を表す観測「eg:dataset-01-00006」の観測の対象である「人口」が「13159388」であるという関係をRDFで表現すると、次のトリプルで表されます。
eg:dataset-01-00006 eg:population 13159388.
ここでは、「人口」に相当するURIを「eg:population」としています。RDFデータキューブ語彙では、観測の対象のことを“測度”と呼びます。上記の場合は、「人口」が測度になります。接頭語「eg」は、ある名前空間を参照する略語です。
次に、観測を限定しているさまざまな条件をRDF化します。図1の場合は、「都道府県が東京都」で「年が2010年」という条件で人口を観測しています。RDFデータキューブ語彙では、観測の条件である「都道府県」(場所)や「年」(時)のことを“次元”と呼びます。これらをRDFで表現すると次のようになります。
eg:dataset-01-00006 eg:refPrefecture eg:prefecture-13. eg:dataset-01-00006 eg:refYear eg:year-2010.
ここでは、「都道府県」「年」に相当するURIをそれぞれ「eg:refPrefecture」「eg:refYear」としています。「東京都」や「2010年」を見れば、これらが「都道府県」や「年」を表していることは明らかなので、次元は不要と思われるかもしれませんが、「東京都から流出した人口」のように、同じ「東京都」でもさまざまな次元(この場合は「流出元の都道府県」)が考えられますから、機械処理を行うためには、次元も明確に書いておくことが必要です。
また、「eg:population」が測度であること、「eg:refPrefecture」と「eg:refYear」が次元であることもRDFで記述する必要がありますが、その記述方法についてはRDFデータキューブ語彙(参考文献1)を参照してください。
以上のようにRDF化しておくと、同じ観測であれば、どのような表の構造で表現されていても必ず同じRDFで表現されます。ただし、上記のように統計データをRDFへ変換する作業には手間がかかるため、変換作業を効率的に行うための手法(参考文献2、3)が提案されています。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。