校正担当者必見!? 地味な誤字脱字で泣かないためのRecurrent Neural Networkのスゴイ生かし方:Deep Learningで始める文書解析入門(2)(1/2 ページ)
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。今回は、本連載における「誤字脱字」の定義と「なぜRNNを利用する必要があるのか」「課題に対してRNNをどのように利用したのか」について。
本連載「Deep Learningで始める文書解析入門」ではDeep Learningの中でも時系列データを扱うRecurrent Neural Network(以下、RNN)とその応用方法としてリクルートグループ内で取り組んでいる原稿校正(誤字脱字の検知)の実現方法について解説していきます。
連載第1回「Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか」ではRNNの概要や活用例について述べてきました。第2回では、誤字脱字の検知というタスクの概要を紹介し、それに対してRNNをどのように活用したかを紹介します。
そもそも何をもって「誤字脱字」とするのか
われわれが文章を書くときは、必ずと言っていいほど誤字脱字のミスが発生します。現在は、PCを使って文章を入力することも多く、その傾向はより顕著になっています。
筆者はリクルート内部で作成される原稿や記事において、この誤字脱字のミスを軽減するためにRNNを利用しています。具体的なRNNの活用方法に触れる前に、このタスクにおいて筆者が想定する「誤字脱字」の定義と「なぜRNNを利用する必要があるのか」について述べていきます。
機械学習は必要なくルールベースで事足りる例
例えば、前回も例で取り上げたように、「私は妄奏する。」という文章があるとします。ここで「妄奏」という単語は、著者自身が考えた造語であり、実際には存在しない単語のため、辞書を構成しておけば、このようなミスを抽出することが可能です。
つまり、この例では機械学習は必要なくルールベースで事足ります。
ルールベースやN-gramでは難しい例
しかし、「私は税金を収める。」という文章はどうでしょうか。「収める」は「税金」という単語に掛かる場合は「納める」が正しいのですが、「収める」も辞書に存在するため、単純なルールベースでは難しいということが分かります。
例えば、N-gramによる言語モデルを利用して検知することも不可能ではありませんが、対象となる文字列の長さに制約があるため、「税金は老後の生活を考えると若いうちから収めておいた方が良いです。」というように文章が長くなっていくと対応できないという問題点があります。
さらに、「私は野球に大好きです。」というような助詞のミスに関しても、N-gram言語モデルでは精度がうまく出ません。
そこで今回は長さが可変であっても対応でき、長期的な系列に対しても有効に学習することが可能なRNNを利用することにしました。
「誤字脱字」の3つの定義
一口に誤字脱字といっても、さまざまなパターンが存在します。例えば、漢字の“つづり”を間違えるといったことは、ほぼ全ての方が経験したことがあると思います。しかし、社内で作成される原稿は手書きではなくPCによって入力されます。そのため、今回のタスクでは下記の3点を誤字脱字と定義しました。
- 助詞のミス:例「私は野球がしました。」
- 変換ミスによる同音異義語ミス:例「税金を収める。」
- タイプミスなどでノイズが含まれるミス:例「週5で働ける方をあ募集しています。」
RNNを誤字脱字検知ロジックの作成に、どう応用するか
ここからは、上記で述べた誤字脱字の課題に対してRNNをどのように利用したのかについて述べていきます。
学習フェーズ(通常のRNNの活用法と全く同じ)
実際に学習フェーズでやっていることは通常のRNNの活用法と全く同じです。図1を参照してください。学習フェーズはRNNのモデルに正しい文章を教え込ませるフェーズです。そのため、間違いのない正しい文章を大量に用意して、それを次々とモデルに覚えさせていきます。
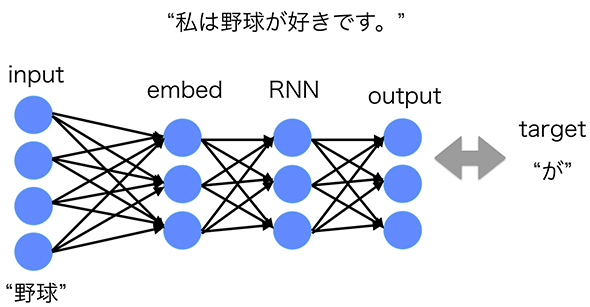 図1 学習フェーズ
図1 学習フェーズここでいう「input」は前回の「入力層」、「output」は前回の「出力層」、「target」は前回の「目標」です。「RNN」の部分が前回の図4となります。「embed」一般的には「embedding層(埋め込み層)」と呼ばれるもので、入力となったベクトルを次元縮約する部分です。
 Recurrent Neural Networkによる学習(前回の図4の再掲)
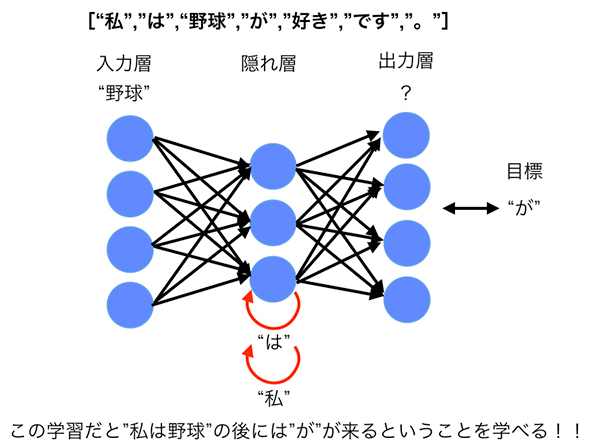
Recurrent Neural Networkによる学習(前回の図4の再掲)例えば、「私は野球が好きです。」という文章の場合は、["私","は","野球","が","好き","です","。"]というように単語で分割して、頭から1単語ずつモデルに入れて、次の単語を予測するように各ユニット間の重みを調整します。
前回の連載でも述べたようにRNNは過去の系列情報を受け継ぎながら学習をするため、「野球」という単語を入力して「が」を予測する際には、「野球」以前に出ている「私」「は」の情報も保持しながら学習を行います。
これにより、前述の「税金」と「納める」の間に他の単語が入っていても「税金」と「納める」の関係性を学習することができるのです。
関連記事
 「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか。GPUコンピューティングを推進するNVIDIAが、これらの違いを背景および技術的要素で解説した。 AlpacaDBがDeep Learningを使った自動取引アプリを公開
AlpacaDBがDeep Learningを使った自動取引アプリを公開
米AlpacaDBは、為替市場での自動取引アルゴリズムを設計できるiPhone向けモバイルアプリ「Capitalico(キャピタリコ)」の提供を開始した。 2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
人気連載を1冊にまとめてダウンロードできる@ITの電子書籍。第16弾は、「いまさら聞けないDeep Learning超入門」だ。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。