LSTMとResidual Learningでも難しい「助詞の検出」精度を改善した探索アルゴリズムとは:Deep Learningで始める文書解析入門(終)(2/2 ページ)
大きな効果があった、目新しくない探索アルゴリズム「ビームサーチ」
上記のように、LSTMやDeep Residual Learningを取り入れ精度は向上したものの、冒頭でも述べた通り、「誤字脱字の検知」という課題の中でも、「助詞の検出」における精度が思った以上に向上しませんでした。そこで、モデルの構造を変えるのではなく、助詞に対しての予測ロジックを変更することにしました。
これまでは、例えば「私は野球に好きです。」という文章を評価する際は、先頭から1単語ずつモデルに読み込ませていき、「私」を入力した際に「は」が出て来る確率やその順位を見て誤字脱字を検出していました。この文章でいうと、「私は野球」の後に出て来る「に」の出現確率および順位が低いと検出が可能なのですが、助詞に関してこのロジックはうまく機能しませんでした。
その原因としては、助詞は前の文脈だけでは判断が難しいという点が挙げられます。例えば、先ほどの「私は野球に好きです。」という文章も、文章全体として見ると変ですが、「私は野球に」だけなら違和感はありません。「私は野球に没頭しています。」などの文章になることが考えられるからです。
「助詞の穴埋め問題を解く」のに有効
この問題に対応する選択肢はいくつかありました。その中には「Bidirectional LSTM」(双方向のLSTM)など、逆方向から文章を読み込み学習させるモデルを導入する手法もありましたが、学習コストの観点から採用しませんでした。代わりに導入した手法が、「助詞の部分だけを空欄にした文を作り、文全体として成り立つような助詞の穴埋め問題を解く」というものです。
可能性の高い助詞の組み合わせを求める際には、探索アルゴリズムの1つである「ビームサーチ」を採用しました。ビームサーチ自体は目新しくない探索アルゴリズムですが、これが今回のタスクにおいては大きな効果を与えました。ビームサーチの様子を図4に記載します。
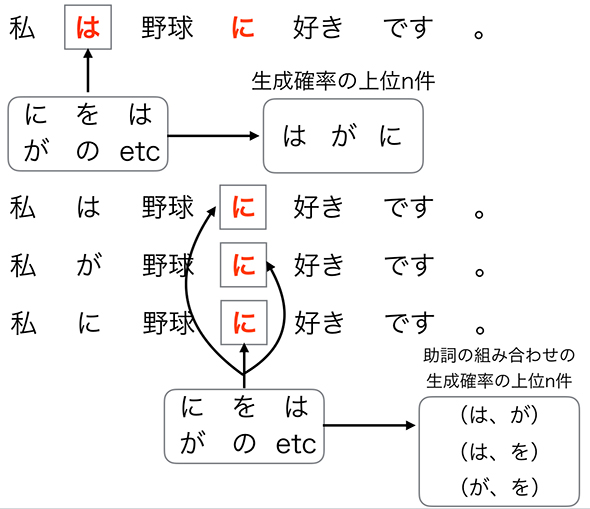 図4 「助詞の穴埋め問題を解く」際のビームサーチ
図4 「助詞の穴埋め問題を解く」際のビームサーチ例えば、「私は野球に好きです。」という文章が与えられた際に、まずそれぞれの単語の品詞を見て、助詞となるものを見つけます。ここでは、「は」と「に」の2つが助詞に該当します。まず「私」から1つ目の助詞(「は」)の穴に対して、全ての助詞で置き換え、その結果できる文章それぞれに対して、その生成確率を算出し、そこで「生成確率が高い」とされた助詞上位n件(図1では、n=3)を保存しておきます。
次の助詞(「に」)に対しても同様に、全ての助詞で置き換え文章全体の生成確率を計算します。そこでは、「1つ目の助詞の置き換えで生成確率が高いとされた上位3件の助詞を埋めた文章」(3パターンの文章)それぞれに対して、2つ目の助詞の生成確率を求めます。そこで生成確率が高かった上位3件の助詞の組み合わせを採用します。
この時点で、「1つ目の助詞について『野球』という後ろの単語を踏まえた評価がなされた」ことになります。これが本手法の狙いです。
以降、残った3個の助詞の組み合わせについて、最後の「。」という単語まで含めた文章の生成確率を求め、再度評価し直します。これにより、「1つ目と2つ目の助詞について、それ以降の単語を全て踏まえた評価がなされた」ことになります。
そして最後に、元の文で使われていた助詞の組み合わせが上位に来なければ誤字脱字としてアラートを上げる仕組みになっています。
ビームサーチを使った利点と導入効果
この手法の利点は、「どれほど助詞が多く含まれた文章であっても最大『n×助詞の数』で済む」点と、「文章全体の生成確率で評価するため一方向のLSTMでは検出できない誤字脱字の検出が可能になった」点が挙げられます。
このビームサーチの導入により、誤字脱字の検出確率は前回の80%程度から85%まで向上し、誤検出率も前回の40%程度から15%程度に抑えることができています。
実用は「人を支援する形での導入」で
ここまで述べてきたように、筆者は「誤字脱字の検出」というタスクに対してLSTMを用いて解決を図ってきました。Deep Residual Learningの導入によるモデルの改良や、ビームサーチの導入という予測ロジックの変更によって、精度もそこそこの数値になりましたが、実用を考えると依然としてさまざまな課題が存在しています。
大きな問題としては、レスポンス速度の問題です。このシステムはWeb APIとして提供され、リアルタイムに文章のチェックを行います。しかし、そこで返答に10秒もかかっていると、かえって原稿の作成に時間がかかってしまうため意味がありません。そのため、今回のシステムではレスポンスまでに1秒を切ることを目標にしています。例えば、「品詞ごとの処理の並列化」などを行うことで時間の短縮を図っています。実際はそれでも遅く、さらなる返答時間の短縮が必要です。
また精度に関しても、機械学習の性質上、「100%の精度で誤字脱字を検出する」「誤検出率を0%にする」というのは不可能です。そのため、「完全な校正(誤字脱字の検出)の自動化」の実現には程遠い状況です。実際の運用場面では、人と機械がそれぞれ得意な部分を担う必要性があります。
例えば、今回紹介したシステムでいうと、「疲れを知らない機械が大量の文章をザッと校正し、その結果アラートが上がったものを重点的に人が見ていく」といった役割分担が必要です。最終的には、「人を支援する形での導入」を目指しています。
RNNに興味を持った方は、まず使ってみて
これまでRNNを用いた誤字脱字検知というテーマで3回にわたって連載してきました。
本連載の目的は、「RNNは通常のニューラルネットワークとどう違うのか」という概念的な部分の理解でした。そのため、数学的な詳細などに関しては触れず、どういう場面でRNNが有効なのかという点にフォーカスしてきました。この連載を見てRNNに興味を持った方、使ってみたいという方は、ぜひ詳細まで理解を深めていってください。
また、連載第1回の最後でも述べましたが、現在RNNやLSTMは、Pythonをはじめ多くの言語で手軽に試せます。さまざまなデータを使ってそれらを動かし、学習の進み方や結果の比較を行ってみてはいかがでしょうか。
筆者紹介
高橋 諒(たかはし りょう)
リクルートテクノロジーズ ITソリューション統括部 ビッグデータ部所属
2015年入社。主にリクルートが抱えるサービスの行動ログ分析とエンハンス開発を行っている。その一方でR&Dとして、文書解析を用いた社内向けAPIサービスの開発推進を積極的に行っている。
関連記事
 「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか。GPUコンピューティングを推進するNVIDIAが、これらの違いを背景および技術的要素で解説した。 AlpacaDBがDeep Learningを使った自動取引アプリを公開
AlpacaDBがDeep Learningを使った自動取引アプリを公開
米AlpacaDBは、為替市場での自動取引アルゴリズムを設計できるiPhone向けモバイルアプリ「Capitalico(キャピタリコ)」の提供を開始した。 2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
人気連載を1冊にまとめてダウンロードできる@ITの電子書籍。第16弾は、「いまさら聞けないDeep Learning超入門」だ。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。