最終回 HTTPプロトコルの補足:超入門HTTPプロトコル(1/2 ページ)
今回はHTTPプロトコルに関連してよく見聞きする「ユーザーエージェント」「リファラ」「クッキー」や認証、高速化などについて説明する。
本入門連載では、システム管理者やシステムエンジニアの方々を主な対象として、IT業界でよく使われる技術や概念、サービスなどの解説をコンパクトにまとめておく。
- 第1回「HTTPプロトコルとは」
- 第2回「HTTPプロトコルの詳細」
- 第3回「HTTPプロトコルの補足」(最終回)
前回はHTTPプロトコルでやりとりされるメソッド(コマンド)とその応答、エラーコードなどについて解説した。今回は連載の最後として、HTTPプロトコルに関する幾つかの話題について補足しておく。
ユーザーエージェント(User Agent)
「ユーザーエージェント(UA)」とは、Webサーバにアクセスするクライアント側のプログラムのことであり、通常はWebブラウザのことを指す。HTTPのクライアントはHTTPのGET要求の送信時に、自身の属性に応じた適切なUA文字列をヘッダフィールドにセットして送信する。これはHTTPのクライアントからサーバ側に渡す情報である。
UA文字列は例えば次のような文字列である。
※Windows 10(ビルド14393)上のMicrosoft EdgeのUAの例
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393
Webサーバはこの内容を見て、アクセス元の機種を判別したり、PCとスマホで異なるデザインのWebページを返したりできるようになる。UAについては、以下の記事も参照のこと。
- Tech Basic「ユーザーエージェント(User Agent、UA)」
ただしUA情報は簡単に偽装できるので、この情報だけで確実に端末の種類を特定できるわけではない。
HTTPリファラ
「HTTPリファラ(HTTP referer)」とは、簡単に言うとWebページがどこから指されているか(リンクされているか)を表す情報である(リファラの正しいつづりは「Referrer」だが、HTTPの規格では「referer」となっている)。
Webページ中のリンクなどをクリックした場合、新しいページに対するGET要求を送る時に、Webブラウザ(ユーザーエージェント)はこのリファラ情報をヘッダフィールドにセットして送信する。これもHTTPのクライアントからサーバ側に渡す情報である。
サーバ側ではこの情報を追跡することにより、ユーザーがどのページからどこへ移動しているか、どこのサイトから自サイトへやってきたか、などが分かる(サイト内の回遊経路や滞在時間などをある程度計測できる)。
ただしサイト内のページから外部サイトへ移動した場合、その情報は得られない(最後に見ていたページのリファラ情報はクリック先のWebサーバへ送信されるため)。
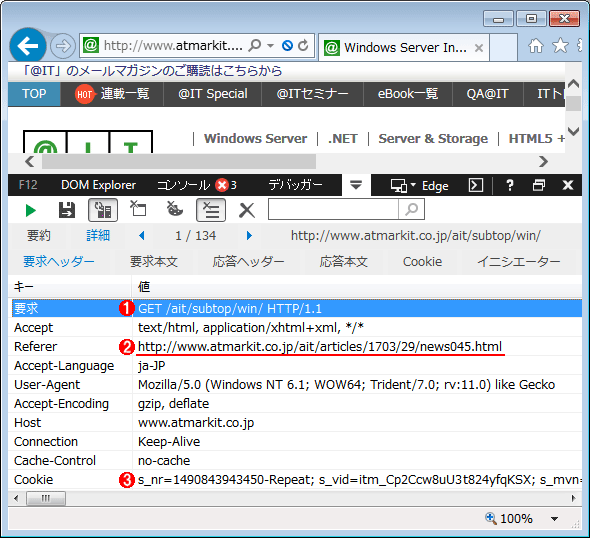 HTTPリファラの情報例
HTTPリファラの情報例Webページ上のリンクをクリックすると、どのページから来たか(どのページ中にあるリンクをクリックしたか)を知らせる、Refererという情報がWebサーバに送信される。
(1)クリックしたリンク先のページ(/ait/subtop/〜)の情報をGETで取得する。
(2)リファラ情報。どのページから来たかがWebサーバ側に送信される。
(3)クッキー(後述)の情報。
HTTPリファラ情報は、ある意味、非常にプライベートな情報である。そのため、このリファラ情報をブロック(削除)するようなWebブラウザやツールもある。だがサイトによってはリファラ情報がないHTTP要求をブロックすることもあり、常に禁止して運用できるわけではない。リファラの有効/無効を制御するHTMLの制御構文やセキュリティポリシーなども制定されようとしている。
クッキー
「HTTPクッキー(HTTP cookie)」とは、Webサーバとクライアント間でユーザーの状態などを維持・管理するための仕組みである。
本来HTTPはステートレスな(“状態”を持たない)プロトコルであり、セッションという概念を持っていない。そのため、例えば同じGET要求に対して、ログイン前とログイン後で表示する内容を変えたいとしても困難である。ページのリンクや遷移で見せるページを変えたとしても、直接該当ページへ飛び込んでくることを阻止できない。
このようなサーバ側の問題を解決するために導入されたのがクッキーの機能である。Webサーバ側からクライアントへ小さな“データ片”(これをコンピュータの分野ではクッキーと呼ぶ)を渡し、以後のやりとりでは必ずそのデータを受け渡すようにしてもらえば、ユーザーの挙動をある程度制御できる(上の画面の(3)参照)。
またCookieを複数のWebサーバやサイト間で共有管理することにより、複数のサーバ間にまたがったユーザーのステート管理などが実現できる。
Cookieについては、今後別記事で詳しく取り上げる予定である。
コンテンツのキャッシュ管理
1つのWebページを構成するHTMLやCSS、画像、スクリプトなどのファイルの数は数十から数百にも及ぶことは前回触れた。Webページを表示するたびに毎回、何百ファイルもいちいちGET要求を出して処理していると、非常に遅くなってしまうだろう。
そこで一般のWebブラウザでは、幾つかの手法でこれを高速化している。最も効果が大きいのは、コンテンツ(ファイルなど)のキャッシング機能であろう。数多くあるファイルのうち、前回Webブラウザで表示した内容と比較すると、実際にファイルの内容が変わっているものはそう多くないはずだ。
メインのコンテンツ部分の内容は頻繁に変更されるかもしれないが、それ以外の部分、例えば画像ファイル(特に背景やボタン、リンクなどのパーツ類)やスクリプト、CSSなどの部品は一度GETで取得すれば、変更がない限り、ローカルにダウンロードしたものをそのまま使えばよい。
このような機能を実現するために、HTTPにはコンテンツの内容が変更されているかどうかなどをチェックするためのヘッダフィールドが幾つか用意されている。以下、それについてまとめておく。
●HEADメソッド
GETメソッドは指定されたデータを取得するが、HEADはデータに関する情報(メタデータ)だけを取得する。データの本体は取得しないので素早く完了する。以前GETで取得したコンテンツのメタデータと比較して、変更点があればあらためてGETで再取得すればよい。
●If-Mocified-Since:
これはGETに追加で指定できるヘッダフィールドである。パラメータとして日時を指定することにより、指定された日時よりもデータが新しければその内容が返される。
●Date:/Last-Modified:
コンテンツの作成日時や最終変更日時を表すフィールド。ローカルのキャッシュ中のコンテンツとこれらを比較して、Webサーバ側の方が新しければデータを再取得する。
●Expires:
コンテンツの有効期間を表す。この日時を過ぎていれば、ローカルのコンテンツは破棄して新たに取得し直す。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。