どのようなデータ基盤を作ったのか? データ収集/蓄積/加工/活用、パイプライン管理の設計:開発現場に“データ文化”を浸透させる「データ基盤」大解剖(2)(2/3 ページ)
データ収集
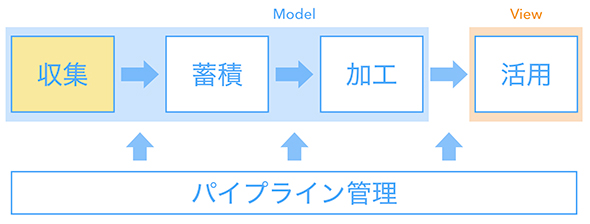
プロダクト本体のRDBMS(MariaDB)やアクセス解析ツール(Adobe Analytics)、そしてアクセスログ(Apache Server)といったデータを取り出して、BigQueryに収集しています。

データの転送に使っている技術要素としては主に以下の2つです。
- TreasureData社が提供するツール
定期的なバッチ処理に適したEmbulkと、リアルタイムのストリーミング処理に適したFluentdを採用しています。主要なDB、ログの転送処理が用意されており、最小限の設定と処理を書くだけで使い始めることができます。
- Python(主に「Requests」「Beautiful Soup」というライブラリ)
Web APIへのリクエストや画面のスクレイピングが必要なものはPythonで書いています。例えば、モバイルアプリのクラッシュログは社内独自ツールに蓄積されるため、Web API経由でデータを取り出します。
Pythonの処理を開発するに当たってはJupyter Notebookを活用しました。データ基盤がない状況だと、分析者がローカル環境のJupyter Notebookに必要なデータを集めることになります。そのデータ収集処理のうち繰り返し必要になるものをPythonスクリプトに出力して流用し、使うかどうかまだ分からないデータの集約についてはROIの判断が難しいため、無理に実装せず後回しにしました。

データ収集の際、データの性質に応じて全件更新と差分反映を使い分けています。

- 状態(State)を扱うデータ
例えば「ユーザーの最終ログイン日時」のように上書きされるデータです。
主な用途としては、画面に「このユーザーは1日前にログインしましたよ」と表示するために使われます。
プロダクト本体のパフォーマンス向上施策としてERを非正規化したものが「状態(State)」に当たります。「いちいちユーザーテーブルと履歴テーブルをJoinして最新ログインに該当するレコードを探すのはDB負荷が大きいため、ユーザーテーブル上に最終ログイン日時を持たせる」といった具合です。
このデータをBigQueryに反映する際は、日次バッチで一括置き換えとしました。差分を記録して疎通するには実装がひと手間掛かります。「初期構築では過剰要件だ」と判断しました。
- 履歴(Event)を扱うデータ
例えば「過去のログイン履歴」のように蓄積されるデータです。
主な用途としては、定着までのログイン頻度を分析したり、ユーザーからの問い合わせを受けて記録を調査したりするために使われます。
毎回ログイン日時を上書きすると分析や調査ができなくなってしまうため、サービス運用、改善の観点では必須となります。性質上データ量が多くなりやすいので、前回以降のレコードだけを抽出してBigQueryに差分を反映します。
ソフトウェアエンジニアがデータ分析に携わっていないと「履歴(Event)」データはログ要件から抜け漏れがちです。必ずしも履歴データを全て保存しなくても機能要件を満たすことはできるからです。
システム開発としては適切かもしれませんが、プロダクト開発としては分析志向を追求したいところでした。「使われるデータ基盤」を構築するには、分析で使える形でデータ収集することが必要です。データ収集の設計時には、「担当プロダクトのログをどう取るべきか」まで描き、必要なら改修していくことが大切だと思います。
データ蓄積
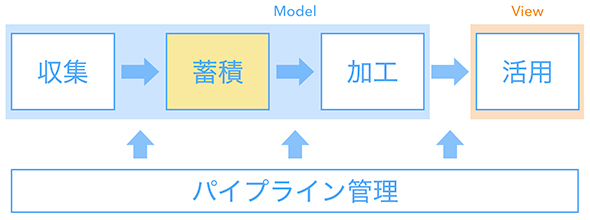
BigQueryに蓄積したデータは3層構造で管理しています。

- Source層
元データをそのままコピーした層で、「データレイク」と呼ばれる概念に近いです。元データと同じ形で残っていると、後から加工・集計のロジックを修正したくなったときに対応できます。多様なデータソースから収集してきたデータは全てSource層に配置されることになります。
- Warehouse層
主要指標や頻出データを中間テーブルとして切り出した層で、「データウェアハウス」と呼ばれる概念に近いです。最初から完璧に定義できるものではなく、ドメイン知識の獲得や組織戦略の変化に伴って主要指標自体が変わり得るので、その変化に追随する形で分離、結合していきます。
- App層
BIツールなどから直接参照するデータの層で、「データマート」と呼ばれる概念に近いです。利用者一人一人が抱える「こういうデータを見たい」という要望と1対1対応になります。運用フェーズではこの層へのアクセス状況をモニタリングすることでデータ基盤の利用状況を分析することになります。

システムがデータを処理する流れは左から右に、人間がシステムを設計する流れは左右から中央に向かいます。

どの層に属するかはデータセット(テーブル名)の命名規則で管理します。「enmusubi__source__db」といった名前で、要素をアンダースコア2つで区切っています。
- どのプロダクトか:enmusubi、koimusubi
- どのレイヤーか:source、warehouse、app
- どのデータか:製品DBならdb、サーバログならapache、アクセス解析ツールならadobe
柔軟に使える技術要素としてBigQueryを選定しましたが、それ故にさまざまな規約を整備する必要が出てきます。この命名規則は「BEM(Block Element Modifier:CSSの設計手法)」を参考にしました。「命名規則で定義を管理する」という発想は、旧来のフロントエンド分野で、グローバル空間で変数が互いに干渉し合うリスクに対して培われてきた知見です。データ基盤もシステムの本質は同じなので、既存の概念を当てはめて考えることができます。

急成長しているプロダクトの場合、機能追加によって頻繁にERを変更することになります。データ基盤も追随して、データソースと対応関係にあるSource層においてマイグレーションを行います。単なるカラム追加であれば話は単純ですが、エンジニアがシステムを綺麗に保つ努力をしていると、どこかでERの分離、結合を行う場面が出てきます。
マイグレーション処理の実装に当たってJupyter Notebookを活用しました。1日分のデータを対象にしてスクリプトを実行し、「想定通りのデータになっているか」をテストコードで自動検証させます。テストが通ったら、Pythonファイルを出力してサーバに上げて全データを対象にして移行処理を実施します。
こういった柔軟な作業がしやすいことも、汎用的なプログラミング言語であるPythonの魅力であり、特に初期構築フェーズでは重宝しました。ただ、あまりにも大量のデータを扱うとパフォーマンス観点で限界が来るので、クラウド事業者が提供する専用ツールなども視野に入れて検討するとよいと思います。
関連記事
 ネット広告のデータ分析プロジェクトはどのように行われるのか
ネット広告のデータ分析プロジェクトはどのように行われるのか
広告宣伝費を各宣伝媒体へのコスト配分を調整することで効率化したいという事業部の課題に対してデータ分析のプロジェクトはどう進められるものなのか。筆者の経験を基に紹介する。 CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。今回は、中古車販売サイト「カーセンサー」を例に「検討フェーズ」を軸とした個別最適化やビッグデータ分析の有効な生かし方について解説する。 Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、ログデータの分析および可視化の基盤を構成する5つの主なOSSや集計データを活用したキーワードサジェストの事例を紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。