[Python入門]Beautiful Soup 4によるスクレイピングの基礎:Python入門(2/2 ページ)
J1リーグの順位をスクレイピングしてみる
ここまでで、Beautiful Soupのだいたいの使い方は分かった。だが新着記事一覧を抽出してもそれほどの役には立たないだろう。そこで、もう少し役に立ちそうな例としてJリーグ(J1ディビジョン)の順位表をスクレイピングしてみよう。毎週月曜日など定期的にスクレイピングをして、それをファイルに保存しておけば、後から何かの役に立つデータとなるかもしれない。
ここではJリーグ公式サイトの順位表をデータのソースとしよう。なお、スクレイピングを行う際には、対象のサイトでそうした行為を禁止していないことを確認してから行うようにしよう。

ここでもHTMLファイルを確認して、その構造を確認しておく必要がある。といっても、このページにあるtableタグは1つだけで、その中にはtrタグで見出し行と各チームの情報が並んでいるだけだ(順位表はtableタグを使って記述するだろうという想定で、実際にHTMLを確認して、実際にそうだったということ。他の部分はスクレイピングには関係ないので無視する)。
そのため、スクレイピングの基本方針として、find_allメソッドでtrタグを検索して各行を含んだリストを取得したら、今度は得られた各行に対して処理を行えばよいだろう。試しに見出し行を見てみることにしよう。
response = request.urlopen('https://www.jleague.jp/standings/j1/')
soup = BeautifulSoup(response)
response.close()
header = soup.find('tr')
print(header)
実行結果を以下に示す。

「Some characters could not be decoded, and were replaced with REPLACEMENT CHARACTER.」と表示されているのは、BeautifulSoupオブジェクトの生成時に内部でHTMLの解析がうまくいかなかったことを示す警告だ。ここでは無視してもよい(以下のコラムも参照のこと)。
その下の出力結果を見ると、空欄が先頭にあるが、それに続けて順位、チーム名、勝ち点、試合数、勝ち数、負け数、引き分け数、得点数、失点数、得失点差、直近5試合の結果が並んでいることが分かる。直近5試合の結果については(事前にチェックしたところ)HTMLファイル自体には特に情報が含まれていなかったので、先頭の空欄と直近5試合の結果は無視することにしよう。
次に実際のチームの情報についても見てみよう。
table = soup.find_all('tr')
print(table[1])
実行すると次のようになる。

ほとんど問題ないが、チーム名がリンクになっていることから1つのtdタグにチーム名が2回登場している。そのため、単純にtext属性でチーム名を得ようとすると、うまくいかない。そのため、ちょっと対処が必要になる。
この後は先ほども言ったように、trタグを検索して、見出し行とチームごとの情報を含んだリストを得たら、今度はその各行に対して、tdタグを検索して上に示した情報を抽出していくだけだ。
実際のコードは次のようになる。
table = soup.find_all('tr')
standing = []
for row in table:
tmp = []
for item in row.find_all('td'):
if item.a:
tmp.append(item.text[0:len(item.text) // 2])
else:
tmp.append(item.text)
del tmp[0]
del tmp[-1]
standing.append(tmp)
for item in standing:
print(item)
ここでは二重ループの形式で処理を行っている。tdタグ内にaタグが含まれている場合は、item.textを半分にスライスすることでチーム名が二重にならないようにしているため、コードが少し複雑になってしまった。それがなければリスト内包表記でズバリと書いてしまいたいところではある。
実行結果を以下に示す。

ご覧のように、現在の順位とその他の情報がリストのリストとして取得できた。後は、これをテキストファイルにCSVファイル(カンマ区切りで要素を区切って並べたテキストファイル)に保存するなどしておけば、後ほど役立つかもしれない(その場合は更新日付をデータの先頭に入れておくなどの処理も必要になるだろう)。
うまくいかない場合
環境やバージョンによっては、Beautiful Soup 4がうまくHTMLをパースできないこともある。実際、上に示した画像では「Some characters could not be decoded, and were replaced with REPLACEMENT CHARACTER.」と表示されている。環境によってはそうしたメッセージを表示することなく、空のHTMLドキュメントしか取得できないこともある。以下に例を示す。

特に後者のようなときは、urllib.request.urlopen関数が返したオブジェクトに対して、readメソッドとdecodeメソッドを自分で呼び出して、エラーを無視してデコードを実行することで何とかなることもある。これには、decodeメソッドのerrorsパラメーターに'ignore'を指定する。実際のコードを以下に示す。
url = 'https://www.jleague.jp/standings/j1/'
response = request.urlopen(url)
content = response.read()
response.close()
charset = response.headers.get_content_charset()
html = content.decode(charset, 'ignore')
soup = BeautifulSoup(html)
print(soup.find('tr'))
このようにすることでうまくいくこともあるので覚えておこう。
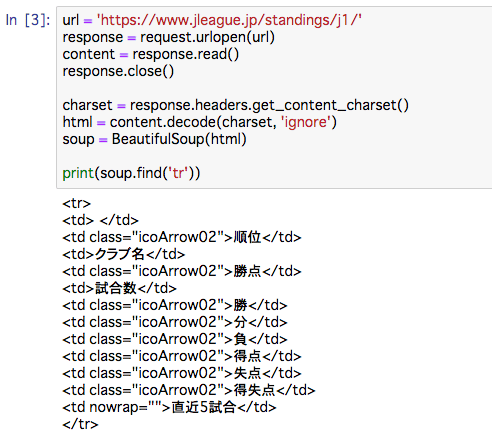 実行結果
実行結果まとめ
今回は前回で紹介したurllib.request.urlopen関数を使って、WebからHTMLファイルを取得して、Beautiful Soup 4というスクレイピングに使えるライブラリを使って、そのファイルから自分が必要な情報を抜き出す方法について簡単に見た。今回と前回はファイル操作からは少し離れた話題となったが、次回はファイルに関連して、フォルダーなどのファイルシステムの操作について見ていくことにしよう。
今回のまとめ
- Webページなどから、自分が欲している情報を抽出することを「スクレイピング」と呼ぶ
- Beautiful Soup 4はそうした処理に使えるPython用のライブラリ(他にもスクレイピングに使えるツールは幾つもある)
- Jupyter Notebookで外部ライブラリをインストールするには「!pip install ライブラリ」を実行する
- Beautiful Soup 4をインストールするには「!pip install bs4」を実行する
- urllib.request.urlopen関数などを使って取得したWebページの情報から、bs4モジュールのBeautifulSoupクラスのオブジェクトを作成すると、そのオブジェクトに対して「.」を使ってタグにアクセスしたり、findメソッドやfind_allメソッドでタグを検索したりできる
- これらの機能を使って、Webページから必要な情報を得られる
- ただし、その前にはWebページがどんな構造になっているかを調べる必要がある
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。