[Python入門]Beautiful Soup 4によるスクレイピングの基礎:Python入門(1/2 ページ)
Beautiful Soup 4を使って、urllib.request.urlopen関数などで取得したHTMLファイルから情報を抜き出す基本的な方法を見てみよう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
前回は、urllib.requestモジュールを利用して、Webからファイルを取得する方法の基本を見た。今回は、このモジュールを使って得たHTMLファイルからBeautiful Soup 4というライブラリを使って必要なデータを抜き出す方法を見てみよう。
スクレイピングとは
スクレイピング(scraping)とは、Webサイトに表示されたHTMLページ(あるいはXMLなど、その他のリソース)から自分が必要とする情報を抽出する(抜き出す)ことだ。特に近年では、機械学習などで大量のデータを取得する必要が出てきていて、それを手作業で行うことは現実的ではないことから、プログラムを使ってそれを自動化(半自動化)することが多くなっている。
Pythonにもスクレイピングを行うためのフレームワークやライブラリといったものが幾つもある。今回はそれらの中でBeautiful Soup 4というライブラリを使って、スクレイピングの基本事項を眺めてみよう。
Beautiful Soup 4
Beautiful Soupは今いったような「HTMLファイルやXMLファイルからデータを抽出するためのPythonライブラリ」だ。本稿執筆時点(2019年10月16日)の最新バージョンは4.8.1であり、これはPython 2とPython 3の両者で動作する。この他にBeautiful Soup 3もあるが、これはPython 3には対応しておらず、また、Python 2のサポート終了とともに終了することから、本稿ではBeautiful Soup 4を使用することにする。
簡単な使い方を紹介しておくと、「urllib.request.urlopen関数でWebからHTMLファイルを取得して、それをBeautiful Soup 4に渡すと、そのHTMLファイルをツリー構造で表現したオブジェクトが得られるので、そのオブジェクトに対して検索するなどして、必要な情報を抽出していく」ことになる。
ただし、本連載で使用しているJupyter Notebook環境ではbs4モジュールは標準では利用できないので、使用する前にインストールする必要がある。これには、セルで「!pip install モジュール名」を実行する。Beautiful Soup 4のモジュール名は「bs4」なので、ここでは「!pip install bs4」となる。なお、Beautiful Soup 4で実際のスクレイピングに使うクラスはBeautifulSoupとしてbs4モジュールで定義されている。
!pip install bs4
これを実行すると次のようになる。

これでBeautiful Soup 4を利用する準備ができたので、本フォーラムの新着記事を抜き出しながら、その基本的な利用法を見ていこう。
Deep Insiderの新着記事を抽出する
先ほども述べたように、Beautiful Soup 4を使うには、その前に目的のWebページが必要になる。これには前回で紹介したurllib.requestモジュールを使える。基本構造は次のようになる。
from urllib import request # urllib.requestモジュールをインポート
from bs4 import BeautifulSoup # BeautifulSoupクラスをインポート
url = '……'
response = request.urlopen(url)
soup = BeautifulSoup(response)
response.close()
# 得られたsoupオブジェクトを操作していく
このように書くと、responseオブジェクトに対してreadメソッドを呼び出して、Webページの内容を読み込んでデコードするといった処理までを、BeautifulSoupインスタンス生成時に自動的に行ってくれる。ただし、これではうまくいかない場合もある(それについては後で見てみよう)。
出来上がったBeautifulSoupクラスのインスタンスは、ソースとなったWebページの構造をツリー状に表現したもので、Webページを構成するタグに「.」でアクセスしたり、特定のタグを検索したりできる。
ここでは、上の変数urlにDeep InsiderのトップページのURL「https://atmarkit.itmedia.co.jp/ait/subtop/di/」を代入して、BeautifulSoupオブジェクトを作成してみよう。
from bs4 import BeautifulSoup
from urllib import request
url = 'https://atmarkit.itmedia.co.jp/ait/subtop/di/'
response = request.urlopen(url)
soup = BeautifulSoup(response)
response.close()
print(soup)
このコードを実行すると次のようになる。

本フォーラムのトップページのHTMLが表示されているのが分かる。BeautifulSoupオブジェクトは既に述べたようにツリー構造のオブジェクトで「.」を使って、そのタグにアクセスできる。例えば、titleタグには次のようにアクセスできる(soup.titleとsoup.head.titleは実際には同じオブジェクト。興味のある方はis演算子で確認してみよう)。
print(soup.title)
print(soup.head.title)
これを実行すると、次のようになる。
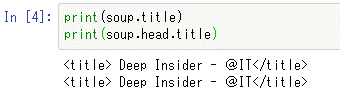 実行結果
実行結果タグのテキストはtext属性で得られる。例えば、titleタグのテキストであれば「title.text」とすればよい。
print(soup.title.text)
実行結果を以下に示す。
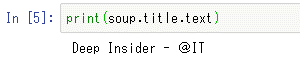 実行結果
実行結果ツリー状のオブジェクトを移動するための属性(next_siblingやnext_elementなど)もあるが、これらについては解説を省略する。
作成したsoupオブジェクトにはfindメソッドやfind_allメソッドで、その内容を検索できる。これを使って、新着記事を一覧してみよう。
元のHTMLファイルの内容を詳しく説明することはやめておくが、本フォーラムでは新着記事が「TOP STORIES」という枠の中に表示されるようになっている。
![新着記事は[TOP STORIES]枠に表示される](https://image.itmedia.co.jp/l/im/ait/articles/1910/18/l_di-pybasic4305.gif)
そして、その部分に該当するソースコードは次のようになっている。

要するに、class属性に「colBoxTopstories」を持つdivタグを見つければよい(その内部にclass属性を「colBoxIndex」とするdivタグが複数あり、それぞれに新着記事が1つずつ記述されている)。実際に試してみよう。BeautifulSoupオブジェクトでタグを検索するには、findメソッドやfind_allメソッドを使える。基本的には次のようにして呼び出せばよい(詳細についてはBeautiful Soupのドキュメント「find()」を参照されたい)。
soup.find(タグ名, 属性=値)
soup.find_all(タグ名, 属性=値
「タグ名」には「div」「p」などのタグを文字列として指定する。その次の「属性=値」に「id=……」「class_=……」のように属性とその値を指定すると、指定したタグのうち、指定した属性が指定した値を持つものだけが得られる。このときclass属性に特定の値を持つものだけを検索したいときには「class=……」ではなく「class_=……」とアンダースコアを付加することに注意しよう(Pythonでは「class」がクラス定義に使われているため)。
findメソッドとfind_allメソッドの違いは、前者は最初に一致したものだけが戻り値となるのに対して、後者は指定した範囲(ここの例であればsoup.find_all(……)とすることで、Webページ全体がその範囲となる)で条件に合致するもの全てを要素とするリストが戻り値となる。
では、findメソッドでclass属性が「colBoxTopstories」であるdivタグを検索してみよう。
topstories = soup.find('div', class_='colBoxTopstories')
print(topstories)
これを実行すると、次のようになる。

ちゃんと該当箇所が得られているようだ。ここからは変数topstoriesに取得した部分を対象に検索をしていこう。既に述べたように、この部分のHTMLは大まかには次のような構造になっている。
![[TOP STORIES]の構造](https://image.itmedia.co.jp/ait/articles/1910/18/di-pybasic4308.gif) [TOP STORIES]の構造
[TOP STORIES]の構造一つ一つの記事はclass属性が「colBoxIndex」であるdivタグの内部に記述されている。そして、その中にはclass属性が「colBoxSubTitle」「colBoxTitle」「colBoxDescription」となっているdivタグがあり、そこに連載タイトル、個々の記事のタイトル、説明が書かれている(それをaタグで囲んでいる)。
そこで、まずはclass属性が「colBoxIndex」であるdivタグをfind_allメソッドで検索して、それらをリストに取得しよう。
colboxindexes = topstories.find_all('div', class_='colBoxIndex')
print(colboxindexes[0])
これを実行すると次のようになる。上のコードでは、先頭要素を画面に出力するようにしている。

このことから、一つ一つの記事に対応するdivタグの内容が得られたことが分かるはずだ。後は、ここから必要な要素を抜き出していくだけだ。これについてもfindメソッドで個々のdivタグを検索してもよいが、Beautiful SoupにはCSSセレクタの書式を利用して要素を取り出すselectメソッドがある。これを使うと、個々の要素を抜き出すコードは次のように書ける。ここでは記事タイトル(class属性が「colBoxTitle」)と説明(class属性が「colBoxDescription」)だけを抽出している。なお、selectメソッドの戻り値はリストになるので、ここではその先頭要素のtext属性を取り出して、必要なデータを得ている。
title = colboxindexes[0].select('div.colBoxTitle')[0].text
description = colboxindexes[0].select('div.colBoxDescription')[0].text
print(title, ':', description)
実行結果を以下に示す。

このように1つの記事のタイトルと説明が得られた。後はこれと同じ処理を変数colboxindexesの各要素に対して行えばよい。
top_articles = []
for item in colboxindexes:
title = item.select('div.colBoxTitle')[0].text
description = item.select('div.colBoxDescription')[0].text
top_articles.append(f'{title}: {description}')
for articles in top_articles:
print(articles)
実行結果を以下に示す。

これで記事の抽出ができた。
なお、上のコードではclass属性が「colBoxIndex」であるdivタグを検索して、それに対してselectメソッドを使うことで記事を抽出したが、変数topstoriesに対して、find_allメソッドでclass属性「colBoxTitle」と「colBoxDescription」を検索し、それらをzip関数でまとめてしまうといったやり方も考えられる。説明はしないがコード例を掲載しておこう。
titles = topstories.find_all('div', class_='colBoxTitle')
descriptions = topstories.find_all('div', class_='colBoxDescription')
title_and_descs = zip(titles, descriptions)
top_articles = [f'{item[0].text}: {item[1].text}' for item in title_and_descs]
for articles in top_articles:
print(articles)
ここではリスト内包表記を使って短いコードとしている(先の例もリスト内包表記で記述できる構造になっているので、興味のある方は書き換えてみよう)。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。