戞5夞丂偍姪傔偺丄TensorFlow 2.0嵟怴偺彂偒曽擖栧乮僄僉僗僷乕僩岦偗乯丗TensorFlow 2亄Keras乮tf.keras乯擖栧乮2/2 儁乕僕乯
僆僾僥傿儅僀僓乮嵟揔壔梡僆僽僕僃僋僩乯
丂傑偢偼僆僾僥傿儅僀僓乮嵟揔壔傾儖僑儕僘儉乯偐傜乮儕僗僩4-8-1乯丅
# 亂弶拞媺幰岦偗偲偺斾妑梡亃妛廗曽朄傪愝掕偡傞
# model.compile(
# tf.keras.optimizers.SGD(learning_rate=0.03), # 嵟揔壔傾儖僑儕僘儉
# 乧乧懝幐娭悢乧乧,
# 乧乧昡壙娭悢乧乧)
# ###亂僄僉僗僷乕僩岦偗亃嵟揔壔傾儖僑儕僘儉傪掕媊偡傞 ###
optimizer = tf.keras.optimizers.SGD(learning_rate=0.03) # 峏怴帪偺妛廗棪
丂偛棗偺捠傝丄慡偔摨偠僐乕僪偲側偭偰偄傞丅弶拞媺幰岦偗偲僄僉僗僷乕僩岦偗偺堘偄偼丄tf.keras.optimizers柤慜嬻娫乮暿柤丗僄僀儕傾僗丗tf.optimizers柤慜嬻娫偱傕傾僋僙僗壜擻乯偺僋儔僗乮椺丗SGD乯偺僀儞僗僞儞僗傪丄
- compile()儊僜僢僪偺堷悢偵巜掕偡傞偐
- 曄悢偵戙擖偡傞偐
偩偗偱偁傞丅
懝幐娭悢
丂師偵懝幐娭悢乮儕僗僩4-8-2乯丅
# 亂弶拞媺幰岦偗偲偺斾妑梡亃妛廗曽朄傪愝掕偡傞
# model.compile(
# 乧乧嵟揔壔傾儖僑儕僘儉乧乧,
# 'mean_squared_error', # 懝幐娭悢
# 乧乧昡壙娭悢乧乧)
# ###亂僄僉僗僷乕僩岦偗亃懝幐娭悢傪掕媊偡傞 ###
criterion = tf.keras.losses.MeanSquaredError()
丂弶拞媺幰岦偗偲僄僉僗僷乕僩岦偗偺堘偄偼丄
- 暥帤楍乮椺丗'mean_squared_error'乯偱丄compile()儊僜僢僪偺堷悢偵巜掕偡傞偐
- tf.keras.losses柤慜嬻娫乮僄僀儕傾僗丗tf.losses柤慜嬻娫乯偺僋儔僗乮椺丗MeanSquaredError乯偺僀儞僗僞儞僗傪丄曄悢偵戙擖偡傞偐
偱偁傞丅
丂側偍曄悢柤傪criterion偲偟偨偑丄偙傟偼岆嵎偐傜偺懝幐傪應傞乽婎弨乮criterion乯乿傪堄枴偡傞丅PyTorch偱偼criterion偑姷椺偱丄TensorFlow偱偼loss_object偲柦柤偡傞偙偲偑懡偄傛偆偱偁傞乮崱夞偼PyTorch偲傕斾妑偟傗偡偄傛偆偵丄PyTorch婑傝偺柦柤傪偟偨乯丅
昡壙娭悢
丂師偼昡壙娭悢偱偁傞乮儕僗僩4-8-3乯丅
# 亂弶拞媺幰岦偗偲偺斾妑梡亃妛廗曽朄傪愝掕偡傞
# model.compile(
# 乧乧嵟揔壔傾儖僑儕僘儉乧乧,
# 乧乧懝幐娭悢乧乧,
# [tanh_accuracy]) # 昡壙娭悢
# ### 亂僄僉僗僷乕僩岦偗亃昡壙娭悢傪掕媊偡傞 ###
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = TanhAccuracy(name='train_accuracy')
valid_loss = tf.keras.metrics.Mean(name='valid_loss')
valid_accuracy = TanhAccuracy(name='valid_accuracy')
丂tanh_accuracy()娭悢傗TanhAccuracy僋儔僗偼丄杮峞偱撈帺偵掕媊偟偨傕偺偱丄Colab僲乕僩僽僢僋懁偵婰弎偑偁傞乮徻偟偔偼偦偪傜傪嶲徠偟偰傎偟偄乯丅
丂弶拞媺幰岦偗偲僄僉僗僷乕僩岦偗偺堘偄偼丄
- tf.keras.metrics柤慜嬻娫乮僄僀儕傾僗丗tf.metrics柤慜嬻娫乯偺娭悢柤乮椺丗binary_accuracy丄崱夞偼撈帺偺tanh_accuracy乯傪丄compile()儊僜僢僪偺堷悢偵巜掕偡傞偐
- tf.keras.metrics柤慜嬻娫乮僄僀儕傾僗丗tf.metrics柤慜嬻娫乯偺僋儔僗乮椺丗Mean乯偺僀儞僗僞儞僗傪丄曄悢偵戙擖偡傞偐
偱偁傞丅
丂僐乕僪検偑偐側傝憹偊偰偟傑偭偨報徾偑偁傞丅弶拞媺幰岦偗偺compile()儊僜僢僪偼丄帺摦揑偵懝幐乮loss乯偼寁嶼偟偰偔傟傞偟丄偟偐傕孭楙僨乕僞偲惛搙専徹僨乕僞偼暘偗偰張棟偟偰偔傟傞丅偦偺偨傔丄惓夝棪乮accuracy乯偺傒傪昡壙娭悢偲偟偰巜掕偡傟偽傛偄丅
丂堦曽丄僄僉僗僷乕僩岦偗偼丄撪晹偵塀暳偝傟偰偄偨偦傟傜偺曄悢傪丄庤摦偱掕媊偟偰偁偘傞昁梫偑偁傞偲偄偆傢偗偩丅偄偢傟傕tf.keras.metrics柤慜嬻娫傪儀乕僗偲偟偨僋儔僗傪巊偭偰偄傞偑丄偙傟偵傛偭偰屻弎偺妛廗乛昡壙偺嵺偵丄懝幐傗惓夝棪偺寁嶼偑妝偵側傞偲偄偆儊儕僢僩偑偁傞丅
丂埲忋偑丄compile()儊僜僢僪偵懳墳偡傞晹暘偱偁傞丅師偵fit()儊僜僢僪偵懳墳偡傞晹暘傪尒偰偄偙偆丅
tf.data僨乕僞僙僢僩
丂傑偢偼孭楙僨乕僞乛惛搙専徹僨乕僞偲儈僯僶僢僠梡偺僶僢僠僒僀僘偺巜掕偱偁傞乮儕僗僩4-9-1乯丅
# 亂弶拞媺幰岦偗偲偺斾妑梡亃擖椡僨乕僞傪巜掕偟偰妛廗偡傞
# model.fit(
# X_train, y_train, # 孭楙僨乕僞
# validation_data=(X_valid, y_valid), # 惛搙専徹僨乕僞
# batch_size=15, # 僶僢僠僒僀僘
# 乧乧僄億僢僋悢乧乧,
# 乧乧幚峴忬嫷偺弌椡儌乕僪乧乧)
# ###亂僄僉僗僷乕僩岦偗亃擖椡僨乕僞傪弨旛偡傞 ###
# NumPy懡師尦攝楍偺僨乕僞宆傪僨乕僞僙僢僩乮僥儞僜儖乯梡偵摑堦偡傞
X_train_f32 = X_train.astype('float32') # np.float64宆 仺 np.float32宆
y_train_f32 = y_train.astype('float32') # 摨忋
X_valid_f32 = X_valid.astype('float32') # 摨忋
y_valid_f32 = y_valid.astype('float32') # 摨忋
# 乽擖椡僨乕僞乮X乯乿偲乽嫵巘儔儀儖乮y乯乿傪丄1偮偺乽僗儔僀僗僨乕僞僙僢僩乮TensorSliceDataset乯乿偵傑偲傔傞
train_sliced = tf.data.Dataset.from_tensor_slices((X_train_f32, y_train_f32)) # 孭楙梡
valid_sliced = tf.data.Dataset.from_tensor_slices((X_valid_f32, y_valid_f32)) # 惛搙専徹梡
# 僔儍僢僼儖偟偰乮孭楙僨乕僞偺傒乯丄儈僯僶僢僠梡偺乽僶僢僠僨乕僞僙僢僩乮BatchDataset乯乿偵偡傞
train_dataset = train_sliced.shuffle(250).batch(15)
valid_dataset = valid_sliced.batch(15)
print(train_dataset)
# <BatchDataset shapes: ((None, 2), (None, 1)), types: (tf.float32, tf.float32)> 乧乧側偳偲昞帵偝傟傞
丂弶拞媺幰岦偗偲僄僉僗僷乕僩岦偗偺堘偄偼丄僨乕僞偲僶僢僠僒僀僘傪丄
- fit()儊僜僢僪偺堷悢偵巜掕偡傞偐
- tf.data婡擻傪巊偭偰儈僯僶僢僠梡僨乕僞僙僢僩傪嶌惉偟偰丄曄悢偵戙擖偡傞偐
偱偁傞丅
丂tf.data偼TensorFlow 2.x帪戙偺擖椡僨乕僞娗棟婡擻乮擖椡僷僀僾儔僀儞乯偱丄僄僉僗僷乕僩岦偗偵儈僯僶僢僠妛廗傪偡傞偺偱偁傟偽桳梡側僣乕儖偱偁傞丅偨偩偟丄忋婰偺捠傝丄僐乕僪偼挿偔側傞丅
丂僐乕僪偺堄枴偼僐儊儞僩傪撉傔偽暘偐傞偲巚偆偺偱妱垽偡傞丅億僀儞僩偼埲壓偺捠傝丅
- 僨乕僞宆偼乽float32乿偵摑堦偟偨曽偑埖偄傗偡偄乮astype(僨乕僞宆)儊僜僢僪棙梡乯
- tf.data.Dataset.from_tensor_slices()儊僜僢僪偱丄NumPy懡師尦攝楍僨乕僞傪tf.data偺悽奅偵帩偭偰偙傜傟傞
- 孭楙帪偵偼婎杮揑偵僔儍僢僼儖偑昁梫丅shuffle(僶僢僼傽僒僀僘)儊僜僢僪偺僶僢僼傽僒僀僘偺晹暘偵偼乮婎杮揑偵乯慡僨乕僞審悢埲忋傪巜掕偡傞
- 嵟屻偵batch(僶僢僠僒僀僘)儊僜僢僪傪屇傃弌偟偰丄孭楙梡乛惛搙専徹梡偺僨乕僞僙僢僩傪惗惉偡傟偽姰椆
丂懕偄偰丄妛廗偲昡壙偺張棟傪尒偰偄偙偆丅偪側傒偵丄偙偺僨乕僞僙僢僩偺弨旛傗丄妛廗偲昡壙偺張棟偼丄PyTorch偺僐乕僪偵偐側傝帡偰偄傞丅乽PyTorch擖栧丗 戞3夞丂PyTorch偵傛傞僨傿乕僾儔乕僯儞僌幚憰庤弴偺婎杮乿傪尒傞偲丄傎偲傫偳尒暘偗偑晅偐側偄偔傜偄摨偠偱偁傞偙偲偑暘偐傞偩傠偆丅傛偭偰丄僐乕僪撪梕偺夝愢傕婎杮揑偵偼摨偠傛偆側撪梕偲側傞丅
妛廗乮1夞暘乯
丂fit()儊僜僢僪偱偼丄妛廗偲昡壙偺張棟偼姰慡偵塀暳偝傟偰偍傝丄懳墳偡傞僐乕僪晹暘偑側偄偺偱丄僄僉僗僷乕僩岦偗偺僐乕僪偺傒傪帵偡乮儕僗僩4-9-2乯丅
import tensorflow.keras.backend as K
# ###亂僄僉僗僷乕僩岦偗亃孭楙偡傞乮1夞暘乯 ###
@tf.function
def train_step(train_X, train_y):
# 孭楙儌乕僪偵愝掕
training = True
K.set_learning_phase(training) # tf.keras撪晹偵傕揱偊傞
with tf.GradientTape() as tape: # 岡攝傪僥乕僾偵婰榐
# 僼僅儚乕僪僾儘僷僎乕僔儑儞偱弌椡寢壥傪庢摼
#train_X # 擖椡僨乕僞
pred_y = model(train_X, training=training) # 弌椡寢壥
#train_y # 惓夝儔儀儖
# 弌椡寢壥偲惓夝儔儀儖偐傜懝幐傪寁嶼偟丄岡攝傪媮傔傞
loss = criterion(pred_y, train_y) # 岆嵎乮弌椡寢壥偲惓夝儔儀儖偺嵎乯偐傜懝幐傪庢摼
# 媡揱攄偺張棟偲偟偰岡攝傪寁嶼乮帺摦旝暘乯
gradient = tape.gradient(loss, model.trainable_weights)
# 岡攝傪巊偭偰僷儔儊乕僞乕乮廳傒偲僶僀傾僗乯傪峏怴
optimizer.apply_gradients(zip(gradient, model.trainable_weights)) # 巜掕偝傟偨僨乕僞暘偺嵟揔壔傪幚巤
# 懝幐偲惓夝棪傪嶼弌偟偰曐懚
train_loss(loss)
train_accuracy(train_y, pred_y)
# ###亂僄僉僗僷乕僩岦偗亃惛搙専徹偡傞乮1夞暘乯 ###
@tf.function
def valid_step(valid_X, valid_y):
# 昡壙儌乕僪偵愝掕乮仸dropout側偳偺嫇摦偑昡壙梡偵側傞乯
training = False
K.set_learning_phase(training) # tf.keras撪晹偵傕揱偊傞
# 僼僅儚乕僪僾儘僷僎乕僔儑儞偱弌椡寢壥傪庢摼
#valid_X # 擖椡僨乕僞
pred_y = model(valid_X, training=training) # 弌椡寢壥
#valid_y # 惓夝儔儀儖
# 弌椡寢壥偲惓夝儔儀儖偐傜懝幐傪寁嶼
loss = criterion(pred_y, valid_y) # 岆嵎乮弌椡寢壥偲惓夝儔儀儖偺嵎乯偐傜懝幐傪庢摼
# 仸昡壙帪偼岡攝傪寁嶼偟側偄
# 懝幐偲惓夝棪傪嶼弌偟偰曐懚
valid_loss(loss)
valid_accuracy(valid_y, pred_y)
丂儕僗僩4-9-2傪尒傞偲丄
- 孭楙乮妛廗乯張棟傪幚憰偟偨train_step娭悢
- 惛搙専徹乮昡壙乯張棟傪幚憰偟偨valid_step娭悢
偑偁傞丅偦傟偧傟丄儈僯僶僢僠妛廗偺1夞暘偺孭楙乛惛搙専徹傪峴偆丅
岡攝僥乕僾偲帺摦旝暘
丂傑偢偼丄train_step娭悢偺拞恎傪尒偰傒傛偆丅pred_y = model(train_X)偲偄偆僐乕僪偱悇榑偑峴傢傟偰梊應抣傪庢摼偟偰偄傞丅loss = criterion(pred_y, train_y)偲偄偆僐乕僪偱丄偦偺梊應抣偲惓夝儔儀儖傪巊偭偰丄懝幐乮loss乯傪寁嶼偟偰偄傞丅偙偺2峴偺僐乕僪偼丄with tf.GradientTape() as tape偲偄偆僗僐乕僾撪偱幚峴偝傟偰偄傞偙偲偵拲栚偟偰傎偟偄丅
丂tf.GradientTape僋儔僗偼丄岡攝僥乕僾乮Gradient Tape乯偲屇偽傟傞TensorFlow 2.0偺怴婡擻偱偁傞丅乽岡攝乿偲偼丄懝幐傪旝暘偡傞偙偲偵傛偭偰摼傜傟傞抣乮愙慄偺孹偒乯偺偙偲偱偁傞丅乽僥乕僾乿偲偼乬僇僙僢僩僥乕僾乭偵壒妝傪婰榐偡傞偺傪僀儊乕僕偡傞偲傛偄乮乧乧側傫偱偙傫側屆偔偝偄柦柤偵偟偨偺偩傠偆偐乯丅偮傑傝丄僗僐乕僾撪偱庢摼偟偨懝幐乮loss乯傪巊偭偰丄帺摦旝暘乮Automatic Differentiation乯偟偨嵺偵丄寁嶼偝傟偨岡攝偑婰榐偝傟傞傛偆偵側傞丄偲偄偆傢偗偱偁傞丅
丂帺摦旝暘乮偡側傢偪僶僢僋僾儘僷僎乕僔儑儞乯傪峴偭偰偄傞偺偑丄gradient = tape.gradient(loss, model.trainable_weights)偲偄偆僐乕僪偱偁傞丅tape偼愭傎偳偺岡攝僥乕僾偱偁傞丅tape.gradient()儊僜僢僪偱岡攝傪寁嶼偟偰丄曄悢gradient偵戙擖偟偰偄傞丅儊僜僢僪偺堷悢偵偼丄懝幐乮losss乯偲丄儌僨儖撪偺孭楙壜擻側廳傒乮model.trainable_weights乯偑巜掕偝傟偰偄傞丅
廳傒偺峏怴
丂偟偐偟丄偙偺抜奒偱偼傑偩岡攝偑寁嶼偝傟偨偩偗偱丄儌僨儖撪偺廳傒傗僶僀傾僗偼峏怴偝傟偰偄側偄丅optimizer.apply_gradients(zip(gradient, model.trainable_weights))儊僜僢僪傪屇傃弌偡偙偲偱弶傔偰峏怴偝傟傞巇慻傒偱偁傞丅
懝幐偲惓夝棪
丂埲忋偱1夞暘偺妛廗偑廔傢偭偨丅傛偭偰偙偙偱丄1夞暘偺懝幐偲惓夝棪傪寁嶼偟偰丄忬嫷傪妋擣偟偰偍偒偨偄丅偙傟傪娙扨偵峴偆偺偑丄慜宖偺儕僗僩4-8-3偱掕媊偟偨昡壙娭悢偱偁傞丅孭楙梡偺懝幐偺昡壙娭悢偼train_loss丄惓夝棪偺昡壙娭悢偼train_accuracy偲偄偆曄悢偵掕媊偟偰偄偨丅偙傟傜傪娭悢偺傛偆偵屇傃弌偟偰偄傞偺偑丄train_loss(loss)偲train_accuracy(train_y, pred_y)偲偄偆2峴偺僐乕僪偱偁傞丅偙傟偩偗偱丄懝幐偲惓夝棪偑乮寁嶼仌乯曐懚偝傟傞丅
惛搙専徹偺張棟偵偮偄偰
丂valid_step娭悢偺曽偼丄妛廗偡傞傢偗偱偼側偄偺偱岡攝寁嶼乮with tf.GradientTape() as tape偲tape.gradient()乯傗廳傒偺峏怴乮optimizer.apply_gradients()乯偼晄梫偱偁傞丅懝幐乮loss乯偺傒傪寁嶼偟丄偦偺寢壥傪昡壙娭悢偱偁傞valid_loss乛valid_accuracy曄悢傪巊偭偰曐懚偡傟偽傛偄偩偗偱偁傞丅
@tf.function偲AutoGraph
丂嵟屻偵丄偦傟偧傟偺娭悢偺忋偵@tf.function偲偄偆僨僐儗乕僞乕偑晅梌偝傟偰偄傞偙偲偵拝栚偟偰傎偟偄丅偙傟偼昁恵偱偼側偄偑丄for儖乕僾側偳偺孞傝曉偟張棟偵偍偄偰丄僷僼僅乕儅儞僗偑椙偔側傞岠壥偑偁傞丅幚嵺偵忋婰偺僐乕僪偱幚峴帪娫傪寁應偟偨偲偙傠丄@tf.function側偟偺応崌偵乽20.3昩乿偐偐偭偰偄偨僐乕僪偑丄@tf.function傪晅偗傞偩偗偱乽3.65昩乿偵側偭偨丅幚偵5.6攞傕崅懍壔偝傟偨偙偲偵側傞丅
丂@tf.function偵傛傞僷僼僅乕儅儞僗岦忋偼働乕僗僶僀働乕僗偱偁傝丄堦奣偵偼尵偊側偄偑丄摿偵train_step乛valid_step娭悢偵巜掕偡傞偺偑偍姪傔偱偁傞丅懠偵偼丄儕僗僩4-1偵帵偟偨tf.keras.Model攈惗僋儔僗撪偺call儊僜僢僪偵晅偗傞偙偲傕偱偒傞丅
丂@tf.function偼丄TensorFlow 2.0偱Eager乮懄帪乯幚峴儌乕僪偑僨僼僅儖僩偵側偭偨偨傔偵摫擖偝傟偨婡擻偱偁傞丅Eager幚峴儌乕僪偱偼丄愢柧嵪傒偩偑丄幚峴帪偵摦揑偵寁嶼僌儔僼偑嶌惉偝傟傞丅偟偐偟壗搙傕摦揑偵嶌惉偡傞偲丄摉慠丄幚峴懍搙偼抶偔側偭偰偟傑偆丅偦偙偱丄1夞栚偺幚峴偺嵺偵寁嶼僌儔僼傪峔抸偟偨傜丄2夞栚偼偦傟傪惷揑側寁嶼僌儔僼偺傛偆偵巊偄夞偡偲丄傛傝張棟偑崅懍壔偡傞偩傠偆丅@tf.function偼偙傟傪峴偆偨傔偺婡擻偱偁傞丅
丂傑偨@tf.function偼丄Python偺if暥傗for暥乛while暥側偳偱彂偐傟偨僐乕僪傪丄寁嶼僌儔僼梡偺tf.cond()娭悢傗tf.while_loop()娭悢側偳偵帺摦揑偵抲偒姺偊傞丅偙偺婡擻偼丄AutoGraph乮帺摦僌儔僼乯偲屇偽傟偰偄傞乮仸乽Grad乿偱偼側偔乽Graph乿丄尒娫堘偄偵拲堄乯丅
丂偨偩偟丄暃嶌梡傕偁傞偺偱丄偳偙偵偱傕巜掕偱偒傞傢偗偱偼側偔丄巜掕偡傞娭悢偺僐乕僪傕拲堄怺偔彂偔昁梫偑偁傞丅徻偟偔偼乽TensorFlow 2.0 偱偺 tf.function 偲 AutoGraph | TensorFlow Core乿傪嶲徠偟偰傎偟偄丅
亂僐儔儉亃孭楙乛昡壙儌乕僪偵偮偄偰
丂杮峞偱偼丄Dropout張棟側偳偵巊偊傞training堷悢偵偮偄偰愢柧偟偨丅TensorFlow 2.x帪戙偺僇僗僞儉僩儗乕僯儞僌偱偼丄偙偺傛偆側柧帵揑側孭楙乛昡壙儌乕僪偺巜掕偑悇彠偝傟偰偄傞丅乽悇彠乿埖偄偱偼偁傞偑丄偙偺巜掕偼僐乕僪傪彂偔恖偑乽妋幚乿偵惂屼偟偨曽偑傛偄丅
丂偲偄偆偺傕丄tf.keras撪晹偱偼僌儘乕僶儖側忬懺娗棟偲偟偰乽Learning Phase乿偲偄偆僼儔僌傪娗棟偟偰偄傞偐傜偩丅椺偊偽tf.keras.layers.BatchNormalization僋儔僗偺撪晹偱偼丄僼僅儚乕僪僾儘僷僎乕僔儑儞偱屇傃弌偝傟偨嵺偵training堷悢偑巜掕偝傟側偐偭偨応崌偵偼丄乽Learning Phase乿僼儔僌偑埫栙揑偵嶲徠偝傟傞巇條偲側偭偰偄傞丅偦偺偨傔丄孭楙乛昡壙儌乕僪偑堄恾偟側偄宍偱摥偒丄寢壥偑偍偐偟偔側傞壜擻惈偑偁傞乮仸TensorFlow偺Issues傪尒傞偲丄偙偺儚僫偵偼傑傞恖偼懡偦偆偱偁傞乯丅
丂偪側傒偵丄弶拞媺幰岦偗偺fit()儊僜僢僪偱孭楙乮True乯偲惛搙専徹乮False乯傪峴偭偨偲偒傗丄僥僗僩乮False乯梡偺evaluate()儊僜僢僪傪屇傃弌偟偨偲偒偼丄偙偺僼儔僌偼tf.keras撪晹偱帺摦揑偵愗傝懼傢傞偺偱丄偁傑傝婥偵偡傞昁梫偑側偄丅偁偔傑偱栤戣偲側傝偦偆側偺偼丄僄僉僗僷乕僩岦偗偺僇僗僞儉僩儗乕僯儞僌偺応崌偱偁傞丅
丂偦偙偱儕僗僩4-9-2偱偼擮偺偨傔丄training堷悢偩偗偱側偔丄import tensorflow.keras.backend as K; K.learning_phase(True乛False)偺傛偆側僐乕僪偱丄乽Learning Phase乿僼儔僌傕摨帪偵巜掕偡傞傛偆偵偟偨偺偱丄嶲峫偵偟偰傎偟偄丅
丂側偍丄乽Learning Phase乿僼儔僌傪庢摼偡傞偵偼丄tf.keras.backend.learning_phase()娭悢傪屇傃弌偣偽傛偄丅
妛廗乮儖乕僾張棟乯
丂偄傛偄傛戝媗傔偩丅儈僯僶僢僠妛廗偱丄僶僢僠偛偲偵妛廗仌昡壙偡傞張棟傪丄for儖乕僾傪巊偭偰婰嵹偡傟偽傛偄丅傑偢僨乕僞慡懱偵憡摉偡傞僄億僢僋偛偲偺for儖乕僾傪嶌傝丄偦偺拞偵儈僯僶僢僠偛偲偺for儖乕僾傪嶌傞丄偲偄偆2奒憌偺峔憿傪嶌傞丅偙傟傪峴偭偰偄傞偺偑丄儕僗僩4-10偱偁傞丅
# 亂弶拞媺幰岦偗偲偺斾妑梡亃擖椡僨乕僞傪巜掕偟偰妛廗偡傞
# model.fit(
# 乧乧孭楙僨乕僞乮擖椡乯乧乧, 乧乧摨乮儔儀儖乯乧乧,
# 乧乧惛搙専徹僨乕僞乧乧,
# 乧乧僶僢僠僒僀僘乧乧,
# epochs=100, # 僄億僢僋悢
# verbose=1) # 幚峴忬嫷偺弌椡儌乕僪
# ###亂僄僉僗僷乕僩岦偗亃妛廗偡傞 ###
# 掕悢乮妛廗乛昡壙帪偵昁梫偲側傞傕偺乯
EPOCHS = 100 # 僄億僢僋悢丗 100
# 懝幐偺棜楌傪曐懚偡傞偨傔偺曄悢
train_history = []
valid_history = []
for epoch in range(EPOCHS):
# 僄億僢僋偺偨傃偵丄儊僩儕僋僗偺抣傪儕僙僢僩
train_loss.reset_states() # 乽孭楙乿帪偵偍偗傞椵寁乽懝幐抣乿
train_accuracy.reset_states() # 乽孭楙乿帪偵偍偗傞椵寁乽惓夝棪乿
valid_loss.reset_states() # 乽昡壙乿帪偵偍偗傞椵寁乽懝幐抣乿
valid_accuracy.reset_states() # 乽昡壙乿帪偵偍偗傞椵寁乽惓夝棪乿
for train_X, train_y in train_dataset:
# 亂廳梫亃1儈僯僶僢僠暘偺乽孭楙乮妛廗乯乿傪幚峴
train_step(train_X, train_y)
for valid_X, valid_y in valid_dataset:
# 亂廳梫亃1儈僯僶僢僠暘偺乽昡壙乮惛搙専徹乯乿傪幚峴
valid_step(valid_X, valid_y)
# 儈僯僶僢僠扨埵偱椵寁偟偰偒偨懝幐抣傗惓夝棪偺暯嬒傪庢傞
n = epoch + 1 # 張棟嵪傒偺僄億僢僋悢
avg_loss = train_loss.result() # 孭楙梡偺暯嬒懝幐抣
avg_acc = train_accuracy.result() # 孭楙梡偺暯嬒惓夝棪
avg_val_loss = valid_loss.result() # 孭楙梡偺暯嬒懝幐抣
avg_val_acc = valid_accuracy.result() # 孭楙梡偺暯嬒惓夝棪
# 僌儔僼昤夋偺偨傔偵懝幐偺棜楌傪曐懚偡傞
train_history.append(avg_loss)
valid_history.append(avg_val_loss)
# 懝幐傗惓夝棪側偳偺忣曬傪昞帵
print(f'[Epoch {n:3d}/{EPOCHS:3d}]' \
f' loss: {avg_loss:.5f}, acc: {avg_acc:.5f}' \
f' val_loss: {avg_val_loss:.5f}, val_acc: {avg_val_acc:.5f}')
print('Finished Training')
print(model.get_weights()) # 妛廗屻偺僷儔儊乕僞乕偺忣曬傪昞帵
丂僄億僢僋偛偲偺儖乕僾偼for epoch in range(EPOCHS):偲偄偆僐乕僪偱丄儈僯僶僢僠偛偲偺儖乕僾偼for train_X, train_y in train_dataset:乛for valid_X, valid_y in valid_dataset:偲偄偆僐乕僪偱婰嵹偝傟偰偄傞丅train_dataset乛valid_dataset曄悢偼丄慜宖偺儕僗僩4-9-1偱嶌惉偟偨僨乕僞僙僢僩偱偁傞丅
丂儈僯僶僢僠偛偲偺儖乕僾撪偱丄愭傎偳偺儕僗僩4-9-2偱幚憰偟偨train_step娭悢傗valid_step娭悢偑屇傃弌偝傟偰偄傞偺偑暘偐傞丅偙傟偩偗偺僐乕僪偱丄僯儏乕儔儖僱僢僩儚乕僋偺妛廗偲昡壙偼幚峴壜擻偱偁傞丅
丂偦偺懠偺僐乕僪偼丄懝幐傗惓夝棪偲偄偭偨惛搙専徹乛忬嫷昞帵偺偨傔偺僐乕僪偲側傞丅
昡壙乮儊僩儕僋僗乯
丂昡壙娭悢偱偁傞train_loss乛train_accuracy乛valid_loss乛valid_accuracy偵偼丄嫟捠偟偰埲壓偺傛偆側儊僜僢僪偑偁傞乮仸尩枾偵偼tf.keras.metrics.Metric僋儔僗偺儊僜僢僪乯丅
- reset_states()儊僜僢僪丗 懝幐傗惓夝棪偲偄偭偨儊僩儕僋僗乮應掕抣乯傪儕僙僢僩
- result()儊僜僢僪丗 儊僩儕僋僗乮應掕抣乯偺庢摼
丂偙傟傜傪巊偭偰丄僄億僢僋偛偲偵丄傑偢偼儊僩儕僋僗偺抣傪弶婜壔偟丄慡僶僢僠傪張棟屻偵儊僩儕僋僗偺抣傪庢摼偟丄偦偺撪梕傪print()娭悢偱Colab儁乕僕忋偵弌椡偟偰偄傞乮恾4-7乯丅

昡壙乮悇堏僌儔僼乯
丂傑偨丄儊僩儕僋僗偺偆偪丄懝幐偺抣傪丄奺僄億僢僋偺棜楌偲偟偰train_history乛valid_history曄悢偵曐懚偟偰偄傞丅偙偺傛偆偵偡傞偙偲偱丄僌儔僼傪昤夋偡傞偙偲傕壜擻偱偁傞乮儕僗僩4-11乯丅
import matplotlib.pyplot as plt
# 妛廗寢壥乮懝幐乯偺僌儔僼傪昤夋
epochs = len(train_history)
plt.plot(range(epochs), train_history, marker='.', label='loss (Training data)')
plt.plot(range(epochs), valid_history, marker='.', label='loss (Validation data)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
丂偙傟傪幚峴偡傞偲丄恾4-8偺傛偆偵昞帵偝傟傞丅
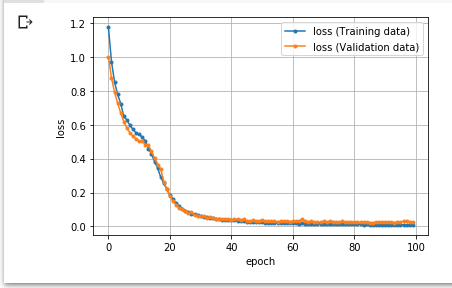 恾4-8丂懝幐抣偺悇堏僌儔僼昤夋椺
恾4-8丂懝幐抣偺悇堏僌儔僼昤夋椺師夞偵偮偄偰
丂崱夞偼Subclassing乮僒僽僋儔僗壔乯儌僨儖偺彂偒曽偵偮偄偰愢柧偟偨丅
丂師夞偺崱夞傪摜傑偊偰丄妶惈壔娭悢乛儗僀儎乕乛僆僾僥傿儅僀僓乛懝幐娭悢乛昡壙娭悢偺僇僗僞儅僀僘曽朄傪愢柧偡傞丅師夞偼偙偪傜丅
Copyright© Digital Advantage Corp. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅