PyTorchからGPUを使って畳み込みオートエンコーダーの学習を高速化してみよう:作って試そう! ディープラーニング工作室(2/2 ページ)
畳み込みオートエンコーダーをGPU対応に
例によって、画像表示/データセット読み込み/データローダー/オートエンコーダークラスのコードは本稿の末尾に掲載することにします。ここでは、学習を行うコード(関数)にだけ着目しましょう。
def train(net, criterion, optimizer, epochs, trainloader):
losses = []
output_and_label = []
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('using device:', device)
net = net.to(device)
for epoch in range(1, epochs+1):
print(f'epoch: {epoch}, ', end='')
running_loss = 0.0
for counter, (img, _) in enumerate(trainloader, 1):
img = img.to(device)
optimizer.zero_grad()
output = net(img)
loss = criterion(output, img)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / counter
losses.append(avg_loss)
print('loss:', avg_loss)
output_and_label.append((output, img))
print('finished')
return output_and_label, losses
上のコードで強調書体となっているのが、前回のtrain関数から変更した部分です。既に述べた通り、torch.cuda.is_available関数の戻り値に応じて、CPUかGPUへの割り当てを表すtorch.deviceオブジェクトを作成して、そのオブジェクトをニューラルネットワークモデルであるnetと、データローダーであるtrainloaderから取り出したimg(入力データ)とtoメソッドに指定することで、ここではGPUへ必要なものを転送するようにしています(正解ラベルは今回は使用していません)。それ以外はこれまでと変わりません。
「これだけ?」と思うかもしれませんが、これだけです(筆者もビックリしました)。重要なのは「必要なものは全て同じデバイスに転送しておく」ことです。ちなみに、GPUが使えない環境で、このコードはどうなるでしょう。その場合、torch.deviceオブジェクトは'cpu'を使って作成されるので、toメソッドでテンソルは「CPUへ転送される」ことになります。実際には、これは元のオブジェクトを返すだけなので、このコードはCPUでもGPUでもどちらでも動作するコードになっています。
では次に、実際に学習を行うコードを見てみましょう。
学習
ここでは前回の最後に見たエンコーダーとデコーダーを使って、AutoEncoder2クラスのインスタンスを作成することにします。
enc = torch.nn.Sequential(
torch.nn.Conv2d(3, 16, kernel_size=4, padding=1, stride=2),
torch.nn.ReLU(),
torch.nn.Conv2d(16, 32, kernel_size=4, padding=1, stride=2),
torch.nn.ReLU()
)
dec = torch.nn.Sequential(
torch.nn.ConvTranspose2d(32, 16, kernel_size=4, stride=2, padding=1),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(16, 3, kernel_size=4, stride=2, padding=1),
torch.nn.Tanh()
)
実際に学習を行うコードを以下に示します。損失関数、最適化アルゴリズム、エポック数(=100)などは前回同様です。
from datetime import datetime
net = AutoEncoder2(enc, dec)
net = net.to(device) # 不要
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
EPOCHS = 100
# 簡易的な実行時間の計測用
torch.cuda.synchronize()
t1 = datetime.now()
output_and_label, losses = train(net, criterion, optimizer, EPOCHS, trainloader)
# 簡易的な実行時間の計測用
torch.cuda.synchronize()
t2 = datetime.now()
print('time:', t2 - t1)
このコードでは、netオブジェクトを生成した後に「net = net.to(device)」を実行していますが、実際にはこれは不要でした。最初は、こうしないとnet.parameters()の戻り値であるジェネレータがGPUに転送されていないオブジェクトを参照してしまうのではないかとか、train関数の中で「net = net.to(device)」を実行することで、トップレベルの変数netとtrain関数内部で使用しているローカル変数(パラメーター)のnetが別々のオブジェクトを参照してしまうのではないかとか、不安に思って書き足していたのでした。
しかし、試したところ、この行がなくてもtrain関数内でnetオブジェクトをtoメソッドでGPUに転送するだけで問題はありませんでした。ソースコードを確認していないので確実ではありませんが、ニューラルネットワークモデルをGPUに転送した場合、その重みやバイアスなどがGPUにコピーされるのであって、それらを格納しているニューラルネットワークのインスタンス自体はそのままなのだと思われます。
興味のある方は、上のコードから「net = net.to(device)」行を削除して、学習を行った後、テスト用のデータローダー(testloader)などからデータを得て、それをGPUに転送したものと転送していないものをnetオブジェクトに入力してみてください。前者では戻り値が得られますが、後者では例外が発生するでしょう。コードだけですが、参考に書いておきましょう。
iterator = iter(testloader)
img, _ = next(iterator)
img2 = img.to(device) # GPUに転送
output = net(img2) # GPUに転送。エラーなし
output = net(img) # GPUに非転送。例外
この他にも注意が必要なコードがあります。それは「# 簡易的な実行時間の計測用」というコメント行の下にある2行(×2)です。PyTorchのドキュメント「CUDA semantics」には「A consequence of the asynchronous computation is that time measurements without synchronizations are not accurate. To get precise measurements, one should either call torch.cuda.synchronize() before measuring……」(非同期での計算には、同期せずに計測したときにその結果が不正確になるという影響があります。正確な計測結果を得るには、計測前にtorch.cuda.synchronize関数を呼び出してください……)という1文があります。「Is there any difference between x.to(‘cuda’) vs x.cuda()? Which one should I use?」なども参考になるでしょう。
そこでここでは、ドキュメントにある通りにtorch.cuda.synchronize関数を実行時間の計測の前に呼び出すことにしました。具体的には、train関数を呼び出す前後で、この関数を呼び出しから、続いてdatetimeモジュールのdatetime.nowクラスメソッドを呼び出して現在時刻を取得しています。最後にその差分を表示することで、簡易的な実行時間の計測としています。
実行結果を以下に示します。今回の目的はGPUによる学習の高速化なので、ここでは最後の実行時間の表示部分だけを示します。
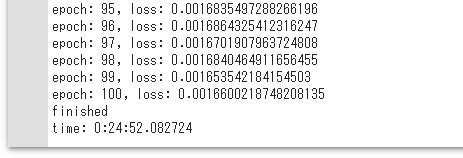 実行結果
実行結果前回のコードでは100エポックの学習に50分ほどがかかっていましたが、上の実行結果を見れば分かる通り、今回は25分程度の実行時間で済みました(何度か実行していますが、おおよそ20分前後で学習が完了することが多かった印象が筆者にはあります)。これがGPUの威力です。コードをほんの少し変更するだけで、GPUの恩恵を受けて、約半分の実行時間で前回と同様な結果が得られたというわけです。
念のため、元の画像と復元後の画像も表示しておきましょう。
img, org = output_and_label[-1]
img = img[0:10]
org = org[0:10]
plt.figure(figsize=(8, 8))
imshow(org.cpu())
plt.figure(figsize=(8, 8))
imshow(img.cpu())
ここでは最後に学習した際の学習結果(復元画像)と対応する元画像を10個取り出して、比較用に表示をしています。ここで画像を表示するためにimshow関数へ渡している引数に注目してください。GPU上に割り当てられて、GPU上で処理された結果はもちろんGPU上に存在します。そのため、これを素直にimshow関数に渡すことはできません。そこでcpuメソッドを使って、GPUからCPUへ画像を転送しています。
実行結果は次の通りです。
 実行結果
実行結果前回同様に、よい結果が得られているようです。
そして「GPUスゲー」と調子に乗って、原稿を書きながら、全結合型のオートエンコーダーについても圧縮後512次元、エポック数1200として学習をしてみました。以前に作成した全結合型のオートエンコーダーで圧縮後384次元、エポック数300の学習に8〜9時間が必要でした。そのまま、1200エポックの学習を行おうとしたら、とんでもない時間がかかりそうです。しかし、GPUを使うことで、おおよそ4時間で学習が終わりました。その結果の画像だけを以下には示しましょう。
 全結合型のオートエンコーダーを1200エポック学習させた結果
全結合型のオートエンコーダーを1200エポック学習させた結果例によって、上段の画像がエンコード/デコードを行う前の画像で、下段の画像はそれをオートエンコーダーで処理した結果です。これまでと同様、輪郭がぼんやりとはしていますが、さすがに1200エポックの学習を行っただけのことはある結果といえるかもしれませんね。
とはいえ、テスト用のデータセットから5つを取り出して、それを(前回の)畳み込みオートエンコーダーで処理したものと、1200エポックを学習した全結合型のオートエンコーダーで処理したものを比べてみると、その差はハッキリと分かります。
 畳み込みオートエンコーダーで処理したもの(上)と1200エポックの学習をさせた全結合型のオートエンコーダーで処理したもの(下)
畳み込みオートエンコーダーで処理したもの(上)と1200エポックの学習をさせた全結合型のオートエンコーダーで処理したもの(下)畳み込みオートエンコーダー(100エポックを学習)で処理した結果(上)は、全結合型のオートエンコーダー(1200エポックを学習)で処理した結果よりもさらにクッキリとした画像を復元できています。
確かにGPUを活用することで、1200エポックの学習を4時間ほどで実行できるようにはなりましたが、畳み込みオートエンコーダーなら50分(GPUなし)、あるいは25分(GPUあり)でもっとキレイに復元が可能なニューラルネットワークモデルを手に入れられます。ということは、筆者が原稿を書きながら待った数時間はまるっきり時間の無駄だったといえるでしょう(実際には、途中でGoogle Colabランタイムへの接続が突然切れたり、筆者のミスで学習後の画像をなくしたりと、10時間以上を無駄にしています)。
こうしたことから、よいアルゴリズムを選択する、使える資源はどんどん使うことで、ニューラルネットワークの学習は効率的に行えることが実感できました。しかし、オートエンコーダーが実際に何かの役に立つのか、その辺を次回は模索してみたいと思います。では、最後にいつものコードをご紹介しておきましょう。
いつものコード
import torch
from torch import nn
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
from torchvision.datasets import CIFAR10
import numpy as np
import matplotlib.pyplot as plt
def imshow(img):
img = torchvision.utils.make_grid(img)
img = img / 2 + 0.5
npimg = img.detach().numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = CIFAR10('./data', train=True, transform=transform, download=True)
testset = CIFAR10('./data', train=False, transform=transform, download=True)
batch_size = 50
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)
testloader = DataLoader(testset, batch_size=batch_size // 10, shuffle=False)
class AutoEncoder2(torch.nn.Module):
def __init__(self, enc, dec):
super().__init__()
self.enc = enc
self.dec = dec
def forward(self, x):
x = self.enc(x)
x = self.dec(x)
return x
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。