PyTorchからGPUを使って畳み込みオートエンコーダーの学習を高速化してみよう:作って試そう! ディープラーニング工作室(1/2 ページ)
GPUを使えるようにGoogle Colabを設定し、PyTorchからGPUを使って畳み込みオートエンコーダーの学習を高速化してみましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
今回の目的
前回は畳み込みオートエンコーダーを作成しました。全結合型のオートエンコーダーと比べると、学習にかかる時間も短くなり、復元された画像もキレイになりました。

しかし、この畳み込みオートエンコーダーの学習には約50分かかりました。同じ100エポックの全結合型オートエンコーダーでは学習には1時間半がかかり、その復元画像もたいしたものではなかったことを考えると、これは大きな進歩ではあります。が、もう少し高速にはならないものでしょうか。
そこで出てくるのが、CPUのような複雑な処理は苦手かもしれませんが、単純な数値計算を高速に行ってくれるGPUです。ニューラルネットワークでは、単純な計算が大量に実行されることから、GPUを使うことで、処理の高速化が見込めます。
そこで今回は、PyTorchでGoogle Colab環境上のGPUを使い、畳み込みオートエンコーダーの学習を高速化してみたいと思います。その過程で、Google ColabでGPUを使うための設定、PyTorchでGPUを使うためのホントにホントの基礎部分について学んでいきましょう。なお、今回のコードはこのノートブックで公開しています。
Google Colab環境でGPUを使うには
PyTorchからGPUを使うには、その前にGoogle Colab環境でGPUを使えるようにしておく必要があります。といっても、これはGoogle Colabの[ランタイム]メニューから[ランタイムの変更]を選択するだけです。これにより[ノートブックの設定]ダイアログが表示されるので、[ハードウェア アクセラレータ]ドロップダウンで[GPU]を選択します。最後に[保存]ボタンをクリックすればGPUを使うための設定が保存されます。
![[ランタイム]メニューから[ランタイムの変更]を選択](https://image.itmedia.co.jp/ait/articles/2008/28/di-gsdl1602.gif)
![[ノートブックの設定]ダイアログで[ハードウェア アクセラレータ]ドロップダウンから[GPU]を選択](https://image.itmedia.co.jp/ait/articles/2008/28/di-gsdl1603.gif)
![[保存]ボタンをクリック](https://image.itmedia.co.jp/ait/articles/2008/28/di-gsdl1604.gif)
GPUを使えるようにノートブックの設定を変更する
以上でGPUを使えるようになりました。なお、有償版のColab Proではより高速なGPUを優先的に使えるなどのメリットがありますが、残念なことに日本での正式なリリースはまだ行われていないようです。
試しに以下のようなコードを書いてみます。
import torch
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
上記の設定を行わないまま、このコードを実行すると、次のような実行結果となります。これはtorch.cuda.is_available関数の戻り値がFalseとなるからです。
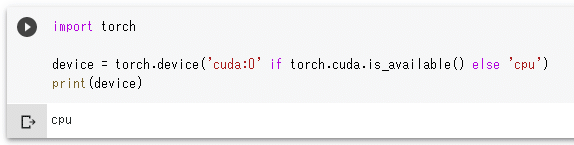 デフォルトではGPUを使わずにCPUを使って全ての処理が行われる
デフォルトではGPUを使わずにCPUを使って全ての処理が行われるしかし、設定を変更した後に同様なコードを実行すれば、その結果は次のようになります(ランタイムが新規に起動されます)。
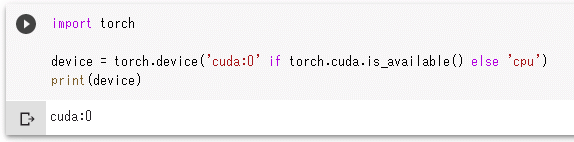 GPUを使えるようになったことが分かる
GPUを使えるようになったことが分かるPyTorchでGPUを使って演算してみる
これでGoogle Colab環境でGPUを使う準備が整いました。しかし、本題の畳み込みオートエンコーダーのコードをGPUに対応させる前に、簡単にPyTorchでGPUを使った処理を行う基本も見ておきましょう。
先ほども見ましたが、現在の環境でGPUが使えるかどうかの確認には、torch.cuda.is_available関数を使います。
print(torch.cuda.is_available()) # GPUが使える:True、使えない:False
ところで、先ほどのコードでは次のようなコードを書いていました。
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
これは何を意味するのでしょう。torch.deviceはテンソルをどのデバイスに割り当てるのか(CPUかGPUか、GPUが複数あるときにはどのGPUか)を表すクラスです。よって、このコードはtorch.cuda.is_available関数呼び出しの戻り値に応じて、'cuda:0'か'cpu'を引数としてtorch.deviceオブジェクトを作成しているということです。
そこでこれを分解して次のようなコードを実行してみましょう。
print(repr(torch.device('cuda:0')))
print(repr(torch.device('cpu')))
この実行結果は次のようになります。
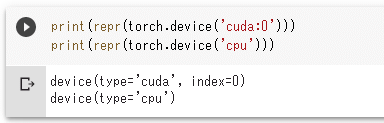 実行結果
実行結果つまり、'cuda:0'を指定してtorch.deviceオブジェクトを作成すると「type='cuda'、index=0」というdeviceオブジェクトが作られ、'cpu'を指定して「type='cpu'」というdeviceオブジェクトが作られるということです。前者の場合、indexはGPUのインデックスを表します。インデックスは複数のGPUを使える環境では、0、1、……のように増えていきます。「torch.device('cuda')」のようにすれば、デフォルトのGPUが指定されたものと見なされます。
これらのdeviceオブジェクトは今も述べたように、「テンソルを割り当てるデバイスを表す」ものです。既存のテンソルであれば、toメソッドにこのオブジェクトを渡すことで、対応するデバイス(CPUかGPU)にその内容が転送されます。実際に試してみましょう。
x = torch.tensor([1, 2, 3])
x = x.to(torch.device('cuda:0')) # テンソルをGPU0に転送して、その結果をxに代入
print(x)
これを実行すると、次のような結果が得られます。

これにより、変数xに転送したテンソルがGPU(インデックス0)に転送されました。注意すべき点は、toメソッドの戻り値を何かの変数に代入しなければ、それは捨てられてしまうことです。上のコードでは、変数xに代入し直しています。
もう一つ、重要なことは「ある処理を行うに当たって、必要となる全ての要素が同じデバイス上になければならない」ことです。つまり、CPU上に割り当てられているテンソルと、GPU上に割り当てられているテンソルとを加算するといったことはできません。
x = torch.tensor([1, 2, 3])
y = torch.tensor([3, 2, 1], device='cpu')
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
z = x.to(device) # GPUに転送
print(x + y) # tensor([4, 4, 4])
print(y + z) # 例外
このコードはではまず2つのテンソル(変数xとy)を作った後に、GPUが使用可能かどうかに合わせてtorch.deviceオブジェクトを作成しています。この時点でGoogle Colab環境ではGPUを使用できるように設定済みなので、deviceオブジェクトはテンソルをGPUに割り当てることを表しています。そして、そのオブジェクトをtoメソッドに与えることで、GPU上に割り当てられたテンソル(元のテンソルのコピー)を別の変数zに代入しています。最後に同じデバイス(CPU)上にあるテンソルを参照している変数xとy、別のデバイス(CPUとGPU)上にあるテンソルを参照している変数yとzとをそれぞれ加算しようというものです。
これを実行してみると、コメントにもある通り、変数yとzの加算で例外が発生します。

このことから分かりますが、ニューラルネットワークモデルの学習や、ニューラルネットワークモデルを利用した推測においては、必要なものを全て同じデバイスに転送しておかなければなりません。
具体的にいえば、GPUを使って学習を行うには重みとバイアスが、入力データと演算されて、正解ラベルと比較されます(正解ラベルがある場合)。よって、これらを全て、事前にGPUへと転送しておく必要があります。
と書くと、何やら大変そうな気になりますが、実際にはそうでもありませんでした。というわけで、前回のコードをGPUに対応させるコードを見てみることにしましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。