Rustは本当に動作が高速なのか? Pythonとの比較で分かる、Rustのパフォーマンス特性:WebエンジニアからみたRust(2)
Web開発者としての興味、関心に基づきRustを端的に紹介し、その強みや弱みについて理解を深める本連載。第2回は、Pythonとの比較を通じてRustのパフォーマンス特性を整理、考察します。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
今回は、Rustのパフォーマンス特性を理解し、Pythonとの比較を通じてRustの構文、記述性を簡潔に紹介します。そのために構文、パフォーマンスを比較するための課題(要件)を設け、それぞれの言語でどのようなプログラムになるのかを確認していきます。いろいろと高速化させたり要件を変化させたりすることで、改めてRustの強み(あるいはPythonの強み)を浮き彫りにしていきます。この記事を作成するに当たり関連コードを収録したGithubリポジトリも用意しましたので、検証したい方はぜひご利用ください。
課題設定
昨今のコロナ禍の情勢において、感染者数の7日間移動平均というデータをニュースでよく見掛けます。N日間移動平均とは、ある日次(時系列)データに対して、直近N日間の平均を計算して得られるデータのことです。例えば[10,20,30,40]という日次データに対して、2日間移動平均を計算すると、[(10+20)/2,(20+30)/2,(30+40)/2]=[15,25,35]というデータが得られます。
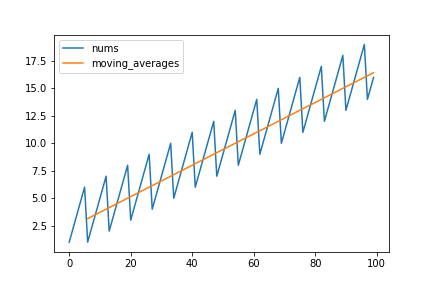 周期7の摂動(変動)を持つ時系列データと7日間移動平均:7日間移動平均を取ることで曜日ごとの摂動を時系列データから取り除くことができます
周期7の摂動(変動)を持つ時系列データと7日間移動平均:7日間移動平均を取ることで曜日ごとの摂動を時系列データから取り除くことができます大した計算ではないですが、考察を深める上で良い題材なのでこれを課題にします。今回のプログラムの要件をひとまず以下のように設定します(後で少し変更します)。
- 64bit浮動小数点で表現できる1000万個のデータ点がある時系列データのcsvを用意
- この7日間移動平均を計算し、メモリに保持する
パフォーマンス比較の形式
PythonやRustには「line_profiler」や「criterion-rs」など、それぞれ優れたプロファイリングのためのライブラリやツールがあります。基本的にはこれらのツールを使うべきですが、計測自体が計測対象に影響を与えてしまいますし(特にline_profiler)、異なる言語間で比較する必要があるため、経過時間をprint出力する方式で進めます。環境によって結果は異なるのですが、参考までに筆者のプログラムの実行環境を以下に記載しました。
- OS:ArchLinux(kernel 5.7.10-arch1-1)
- CPU:AMD Ryzen 9 3950X 16-Core Processor
- RAM:G.Skill F4-3200C16-32GVK×4(DDR4-3200 32GB×4)
- SSD:Crucial CT1000MX500SSD1(1000GB Serial ATA 6Gb/s)
最適化無しのPythonで実装する
まずは最適化一切なしの純粋なPythonで要件を満たすためのコードを記述しました。Pythonを利用したことがない人でも雰囲気がつかめるよう、コードにコメントを付記しています。
import csv
import math
import sys
import psutil
from datetime import datetime
from typing import List
import pandas as pd
def process_memory_usage_mb():
"""
実行プロセスのメモリ使用量を取得する(単位はMB)
"""
return psutil.Process().memory_info().rss/1e6
def read_csv(relative_path):
res = []
with open(relative_path) as f:
reader = csv.reader(f)
next(reader) # ヘッダをskipする
for row in reader:
res.append(float(row[0])) # csvの全行をfloat型に変換して読み込む
return res
def calc_batch_list(calc_strategy, average_length) -> List:
"""
csvからPythonのlistを読み込み、バッチ的に移動平均を計算させる
"""
before_read = datetime.utcnow() # データ読み込み前の時刻記録
nums = read_csv("../data/time_series.csv") # データ一括読み込み
after_read = datetime.utcnow() # データ読み込み後の時刻記録
moving_averages = calc_strategy(nums, average_length) # 関数を用いて移動平均計算
after_calc = datetime.utcnow() # 移動平均計算後の時刻記録
print(f"移動平均計算に使用した関数:{calc_strategy}")
print(f"移動平均の長さ:{average_length}")
print(f"移動平均の最後の要素:{moving_averages[-1]}")
print(f"csvロードにかかった時間:{after_read - before_read }秒")
print(f"移動平均計算にかかった時間:{after_calc - after_read}秒")
print(f"リストのメモリ使用量(参考):{sys.getsizeof(moving_averages)/1e6}MB")
print(f"プロセスメモリ使用量(参考):{process_memory_usage_mb()}MB")
return moving_averages
def moving_average_batch_python(nums: List, average_length: int) -> List:
"""
Pythonのlistを使う、移動平均を素直に計算する
"""
assert len(nums) - average_length + 1 > 0 # データが不足する場合は例外を送出する
# 直近N日間の総計を計算しそれをNで割る
res = [sum(nums[i-average_length+1:i+1]) / average_length for i in range(average_length-1, len(nums))]
return res
if __name__ == "__main__":
ma1 = calc_batch_list(calc_strategy=moving_average_batch_python, average_length=7)
| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Python(Naive,7) | 3.3秒 | 2.6秒 | 5.9秒 | 89MB | 870MB |
1000万行のデータを処理したことを考えれば決して悪くはない結果です。6秒以内で処理を完結させることができます。
Rustで実装する
次にRustで要件を満たすためのコードを記述しました。エラーを扱う上で便利な「anyhow」など幾つか外部のクレート(ライブラリ)を使用しています。
// リポジトリのルートディレクトリを起点とした絶対パスを取得する(Github参照)
fn get_csv_path(relative_path: &str) -> std::path::PathBuf {
let project_path = env!("CARGO_MANIFEST_DIR"); // RustのプロジェクトファイルCargo.tomlがあるディレクトリ
std::path::Path::new(project_path)
.parent() // project_pathの1つ上のディレクトリ(=リポジトリのルート)
.unwrap()
.join(relative_path)
}
fn read_csv(relative_path: &str) -> anyhow::Result<Vec<f64>> {
let csv_path = get_csv_path(relative_path); // csvデータの絶対パスを取得する
let mut csv_reader = csv::Reader::from_path(csv_path)?;
let nums = csv_reader
.deserialize::<f64>() // 何もしないと行データは文字列として読み込まれるので、f64に変換する
.filter_map(|row_result| row_result.ok()) // f64として読み込めなかった行を無視する
.collect::<Vec<_>>(); // 可変長配列に格納する
Ok(nums)
}
fn moving_average_batch_naive(nums: &[f64], average_length: usize) -> anyhow::Result<Vec<f64>> {
let size = nums.len() as i64 - average_length as i64 + 1; // 出力される移動平均の数列のサイズ
if size <= 0 {
// サイズが0以下ならばエラー値を関数の戻り値として返す
return Err(anyhow::anyhow!(
"average length must be less than nums array length"
));
}
let averages = nums
.windows(average_length) // 直近N個のデータを記憶しながらループを回す
.map(|window| window.iter().sum::<f64>() / (window.len() as f64)) // 直近N個のデータの総和をとり、Nで割る
.collect::<Vec<_>>(); // 結果を可変長配列に格納する
Ok(averages) // 可変長配列を関数の戻り値として返す、returnは省略している
}
fn calc_batch<F: FnOnce(&[f64], usize) -> anyhow::Result<Vec<f64>>>(
strategy: F,
average_length: usize,
) -> anyhow::Result<Vec<f64>> {
let before_read = chrono::Utc::now(); // データ読み込み前の時刻記録
let nums = read_csv("data/time_series.csv")?; // 指定したcsvデータをf64の可変長配列として読み取る
let after_read = chrono::Utc::now(); // データ読み込み後の時刻記録
let moving_averages = strategy(&nums, average_length)?; // 関数を用いて移動平均計算
let after_calc = chrono::Utc::now(); // 移動平均計算後の時刻記録
println!(
"移動平均計算に使用した関数:{:?}",
std::any::type_name::<F>()
);
println!("移動平均の長さ:{}", average_length);
println!(
"移動平均の最後の要素:{:?}",
moving_averages[moving_averages.len() - 1]
);
let load_time = after_read - before_read;
let calc_time = after_calc - after_read;
println!(
"csvロードにかかった時間:{:?}秒",
load_time.num_nanoseconds().unwrap() as f64 / 1e9
);
println!(
"移動平均計算にかかった時間:{:?}秒",
calc_time.num_nanoseconds().unwrap() as f64 / 1e9
);
println!(
"Vecの使用メモリ量(参考):{:?}MB",
std::mem::size_of_val(&*moving_averages) as f64 / 1e6
);
println!(
"プロセスの使用メモリ量(参考):{:?}MB",
psutil::process::Process::new(std::process::id())
.unwrap()
.memory_info()
.unwrap()
.rss() as f64
/ 1e6
);
Ok(moving_averages)
}
fn main() -> anyhow::Result<()> {
let ma1 = calc_batch(moving_average_batch_naive, 7)?;
Ok(())
}

| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Rust(Naive,7) | 0.65秒 | 0.047秒 | 0.7秒 | 80MB | 162MB |
純粋なPython実装と比べて処理が高速化されています。また、メモリ使用量についてもかなりの部分が説明可能であることも分かります。f64(8バイト)のデータが1000万行あるので、1000万×8バイト=80MBで、それがnums変数とmoving_averages変数に保持されているため160MBが必要最小限のメモリと計算できますが、それに非常に近い値となっています。
ソースコードの面で比較してみると、RustのコードはPythonに比べてやや冗長です。冗長となっている理由を簡単にまとめると、以下のようになります。
- 型を明示する必要がある(関数の入出力、計算時の細かな型変換など)
- エラー値の処理を細かく記述している(読み込めない行があった場合どうするか、移動平均を計算できない場合どうするかなど)
- (抽象化の余地があり、大した差ではないが)相対パスの解決のためにget_csv_path関数を作っている
これらを除外して見比べてみると、RustはPythonと非常に似通ったプログラム構造で記述可能であることが分かります。
Numpyを利用したPythonで実装する
ある程度データ分析に習熟したPython使用者にとって、上記の比較はフェアではないと思うことでしょう。Pythonが機械学習分野という多くの計算量を必要とする分野で利用され続けている理由は、それを支えるエコシステムがあるからです。その代表格といえる「Numpy」を利用して、要件を満たすコードを記述します(一度書いた関数は再利用します)。
def calc_batch_ndarray(calc_strategy, average_length) -> np.ndarray:
before_read = datetime.utcnow() # データ読み込み前の時刻記録
nums = pd.read_csv("../data/time_series.csv")['value'].values # データ一括読み込み
after_read = datetime.utcnow() # データ読み込み後の時刻記録
moving_averages = calc_strategy(nums, average_length) # 関数を用いて移動平均計算
after_calc = datetime.utcnow() # 移動平均計算後の時刻記録
print(f"移動平均計算に使用した関数:{calc_strategy}")
print(f"移動平均の長さ:{average_length}")
print(f"移動平均の最後の要素:{moving_averages[-1]}")
print(f"csvロードにかかった時間:{after_read - before_read }秒")
print(f"移動平均計算にかかった時間:{after_calc - after_read}秒")
print(f"配列のメモリ使用量(参考):{moving_averages.nbytes/1e6}MB")
print(f"プロセスメモリ使用量(参考):{process_memory_usage_mb()}MB")
return moving_averages
def moving_average_batch_numpy(nums: np.ndarray, average_length: int) -> np.ndarray: # numpy arrayを使う、convolve APIを使う
assert len(nums) - average_length + 1 > 0
return np.convolve(nums, np.ones(average_length), 'valid') / average_length
if __name__ == "__main__":
ma1 = calc_batch_ndarray(calc_strategy=moving_average_batch_numpy, average_length=7)
| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Python+Numpy(Naive,7) | 0.55秒 | 0.029秒 | 0.58秒 | 80MB | 227MB |
プロセスメモリ使用量を除いて、Rust実装と比べても良い結果が得られてしまいました。難しいテーマですが、このパフォーマンスについて考察してみます。Numpyではベクター計算を高度に最適化してくれますが、筆者が用意したRustコードではそのような最適化を含んでいないことが理由の一つだと考えられます。Rustコードに最適化の余地があるわけですが、本記事では計算のユースケースや汎用(はんよう)性に着目して議論を進めたいと思います。
移動平均の長さを変えて比較する
上記までの計算では移動平均の長さを7と固定していました。この要件を変更して5000に変更してみるとどうなるでしょうか?
| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Python+Numpy(Naive,5000) | 0.53秒 | 5.77秒 | 6.3秒 | 80MB | 227MB |
Numpyによる最適化の恩恵を受けても6秒近くの計算時間がかかりました。というのも上記までの計算手法では、移動平均の長さが大きくなるほど、必要となる足し算の回数が増えるからです(1ループ当たり6回→4999回)。
移動平均を計算するに当たって、もし1日前の和を参照できれば、今日の和=前日の和+今日のデータ-N日前のデータという関係性が成り立つので計算量を落とすことができます。この考え方に基づきRustコードを書き換えてみます。
fn moving_average_batch_online(nums: &[f64], average_length: usize) -> anyhow::Result<Vec<f64>> {
let size = nums.len() as i64 - average_length as i64 + 1; // 出力される移動平均の数列のサイズ
if size <= 0 {
// サイズが0以下ならばエラー値を関数の戻り値として返す
return Err(anyhow::anyhow!(
"average length must be less than nums array length"
));
}
let mut res = Vec::with_capacity(nums.len());
// 直近N個のデータの総和を計算する、最初のデータは素直に総和をとる
res.push(nums[0..average_length].iter().sum::<f64>());
// 最初のデータ以外は前の総和から新しいデータを足して、古いデータを引くことで計算し、計算量を減らす
for i in average_length..nums.len() {
res.push(nums[i] as f64 - nums[i - average_length] as f64 + res[i - average_length])
}
// 出力するデータをNで割る、後で割るのは計算誤差を小さくするため
for i in 0..(nums.len() - average_length + 1) {
res[i] /= average_length as f64;
}
Ok(res)
}
fn main() -> anyhow::Result<()> {
let _ma = calc_batch(moving_average_batch_online, 5000)?;
Ok(())
}
| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Rust(Online,5000) | 0.58秒 | 0.079秒 | 0.66秒 | 80MB | 162MB |
7日移動平均を計算していたときとそれほど変わらない計算時間で計算を完了させることができました。
一方でNumpyの方はもともとNumpyのconvolve関数を使っていたので、そのまま書き換えることができません。forループを使うことになりますが、Numpyでそのままforループを使ってしまうと基本的に遅くなってしまうので、ここでは「Numba」というライブラリを使って最適化します。
@numba.jit(nopython=True)
# numpy arrayを使う、オンラインアルゴリズムを使用、Numbaを使う
def moving_average_batch_numpy_numba_online(nums: np.ndarray, average_length: int) -> np.ndarray:
assert len(nums) - average_length + 1 > 0
N_i = nums.shape[0]
res = np.empty_like(nums, dtype=np.float64)
res[average_length - 1] = np.sum(nums[:average_length])
for i in range(average_length, N_i):
res[i] = nums[i] - nums[i - average_length] + res[i - 1]
for i in range(average_length-1, N_i):
res[i] = res[i] / average_length
return res[average_length-1:]
if __name__ == "__main__":
ma8 = calc_batch_ndarray(calc_strategy=moving_average_batch_numpy_numba_online, average_length=5000)
| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Python+Numpy+Numba(Online,5000) | 0.55秒 | 0.31秒 | 0.86秒 | 80MB | 304MB |
Pythonを利用してもそこまで速度を落とすことなく計算が終わるようになりました。
ストリーム処理で比較する
これまでは1000万行のデータを全てメモリに配置しバッチ処理をさせるという要件(インタフェース)で考えていました。この場合では1秒当たり何行処理できるかのスループットの観点が重要であり、いずれの言語でもスループットは引き出せることが分かりました。一方で、現状のプログラムは全部の値を読み込んでから計算することを前提にしているため、処理遅延(レイテンシ)とメモリ一括確保が避けられません。Webアプリケーションにおいては一括でデータを読み込まなければならないという前提はかなり不自然です。そこで以下の制約を要件に追加します。
- 中間変数(nums)を用いてデータを一括で読み込むことを禁止する(ストリーム処理で計算する)
この前提に基づきRustコードを書き換えてみます。
#[derive(Debug, Clone)]
pub struct MovingAverage {
period: usize,
sum: f64,
deque: std::collections::VecDeque<f64>,
}
impl MovingAverage {
pub fn new(period: usize) -> Self {
Self {
period,
sum: 0.0,
deque: std::collections::VecDeque::new(),
}
}
pub fn latest(&mut self, new_val: f64) -> Option<f64> {
self.deque.push_back(new_val);
let old_val = match self.deque.len() > self.period {
true => self.deque.pop_front().unwrap(),
false => 0.0,
};
self.sum += new_val - old_val;
match self.deque.len() == self.period {
true => Some(self.sum / self.period as f64),
false => None,
}
}
}
fn calc_stream(average_length: usize) -> anyhow::Result<Vec<f64>> {
let before_read = chrono::Utc::now();
let csv_path = get_csv_path("data/time_series.csv");
let mut csv_reader = csv::Reader::from_path(csv_path)?;
let mut ma = MovingAverage::new(average_length);
let moving_averages = csv_reader
.deserialize::<f64>()
.filter_map(|row_result| row_result.ok())
.filter_map(|new_val| ma.latest(new_val))
.collect::<Vec<_>>();
let after_calc = chrono::Utc::now();
println!("移動平均の長さ:{}", average_length);
println!(
"移動平均の最後の要素:{:?}",
moving_averages[moving_averages.len() - 1]
);
let total = after_calc - before_read;
println!(
"計算にかかった時間:{:?}秒",
total.num_nanoseconds().unwrap() as f64 / 1e9
);
println!(
"Vecの使用メモリ量(参考):{:?}MB",
std::mem::size_of_val(&*moving_averages) as f64 / 1e6
);
println!(
"プロセスの使用メモリ量(参考):{:?}MB",
psutil::process::Process::new(std::process::id())
.unwrap()
.memory_info()
.unwrap()
.rss() as f64
/ 1e6
);
Ok(moving_averages)
}
fn main() -> anyhow::Result<()> {
let ma4 = calc_stream(5000)?;
Ok(())
}
| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Rust(Stream,5000) | --- | --- | 0.59秒 | 80MB | 83MB |
csvの読み込み結果を一時的に受け取る中間変数numsがなくなりました。計算時間はバッチ計算のものとほぼ同じです。またMovingAverageという構造体を用意し、移動平均の計算の本質部分を抽出しました。これはストリーム・バッチ処理を問わず利用可能な汎用的な抽象であり、つまりパフォーマンスを損ねることなくアプリケーションコードとシミュレーション(データ分析)コードを同一にできる可能性を示しています。
次にPythonでストリーム処理を行うコードを記述します。
class MovingAveragePython(object):
def __init__(self, period):
self.sum = 0
self.period = period
self.deque = collections.deque()
def latest(self, new_val):
self.deque.append(new_val)
old_val = self.deque.popleft() if len(self.deque) > self.period else 0.0
self.sum += new_val - old_val
return self.sum / self.period if len(self.deque) == self.period else None
def calc_stream(constructor, average_length) -> np.ndarray:
before_read = datetime.utcnow() # データ読み込み前の時刻記録
moving_averages = []
ma = constructor(average_length)
with open("../data/time_series.csv") as f:
reader = csv.reader(f)
next(reader) # ヘッダをskipする
for row in reader:
num = float(row[0])
moving_averages.append(ma.latest(num))
after_calc = datetime.utcnow() # 移動平均計算後の時刻記録
print(f"移動平均の長さ:{average_length}")
print(f"移動平均の最後の要素:{moving_averages[-1]}")
print(f"計算にかかった時間:{after_calc - before_read}秒")
print(f"リストのメモリ使用量(参考):{sys.getsizeof(moving_averages)/1e6}MB")
print(f"プロセスメモリ使用量(参考):{process_memory_usage_mb()}MB")
return moving_averages
if __name__ == "__main__":
ma3 = calc_stream(constructor=MovingAveragePython, average_length=5000)
| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Python(Stream,5000) | --- | --- | 6.9秒 | 84MB | 529MB |
ストリーム処理をするということは、Pythonのコンテキストでループを回さざるを得なくなってしまうため、速度はどうしても落ちてしまいます。また、Numbaを使ってもストリーム処理の計算時間は改善できず、また抽象化にも限界があります。バッチ処理のコードとストリーム処理のコードを抽象化することは難しく、どちらかのパフォーマンスに妥協した結果になると思われます。
それでも1000万行のデータの処理時間であるので、レイテンシという観点で見れば1つの入力当たり69ナノ秒で処理できているともいえます。これを高いと見るか、低いと見るかはアプリケーションの性質や計算の重さによるところが大きいでしょう。また、Githubのリポジトリにチャネルという言語機能を用いたマルチスレッドの検証結果とasync/awaitを用いた結果を試験的に追加していますが、上述のシングルスレッドの方が速いことが分かっています。これは移動平均の計算コストよりもスレッド間の通信コストの方が高価であるためだと考察できます。アプリケーション特性に応じて自在に計算モデルを選択できるのもRustの魅力だといえるでしょう。
まとめ
今回、PythonとRustの構文比較をしながら、パフォーマンス特性について考察を深めました。結論としては以下のようになります。
- バッチ計算ではPythonとRustはそこまで大きな差はない
- ただし、Pythonで高速化するためにはNumpy、Numbaのコンテキストでループを回すという制約がつく
- ストリーム計算では、Rustに優位性がある
- Rustではパフォーマンスを損ねることなくアプリケーションコードとシミュレーション(データ分析)コードを抽象化できる
| 言語(計算手法,移動平均長) | csvロード時間 | 計算時間 | 総計算時間 | 変数のメモリ使用量 | プロセスのメモリ使用量 |
|---|---|---|---|---|---|
| Python(Naive,7) | 3.3秒 | 2.6秒 | 5.9秒 | 89MB | 870MB |
| Rust(Naive,7) | 0.65秒 | 0.047秒 | 0.7秒 | 80MB | 162MB |
| Python+Numpy(Naive,7) | 0.55秒 | 0.029秒 | 0.58秒 | 80MB | 227MB |
| Python+Numpy(Naive,5000) | 0.53秒 | 5.77秒 | 6.3秒 | 80MB | 227MB |
| Rust(Online,5000) | 0.58秒 | 0.079秒 | 0.66秒 | 80MB | 162MB |
| Python+Numpy+Numba(Online,5000) | 0.55秒 | 0.31秒 | 0.86秒 | 80MB | 304MB |
| Rust(Stream,5000) | --- | --- | 0.59秒 | 80MB | 83MB |
| Python(Stream,5000) | --- | --- | 6.9秒 | 89MB | 529MB |
次回は、ここまであまり触れることがなかったRustの難しさと開発生産性について考えてみたいと思います。
筆者紹介
藤田直己
1988年生まれ、大阪府枚方市出身
京都大学工学部電気電子工学科卒、同大学エネルギー科学研究科修了
応用情報技術者・情報処理安全確保支援士試験合格者
YKK AP株式会社にて超高層建築物の外装設計に従事し、型・モジュール設計・ウオーターフォールプロセスに精通する。その後ITエンジニアに転向。paiza株式会社にて、Ruby on RailsやVueを用いたWebサービスのスクラム開発に従事、現在に至る。
最も得意な言語はPython、最も影響を受けた言語はClojureであり、シンプルな関数型(的書き方ができる)言語を好む。関数型的記法を持ちながら、実行性能が高いRustに興味を持ち研さんを続けている。
関連記事
 プログラミング言語「Rust」とは? "Hello, World!"で基本を押さえる
プログラミング言語「Rust」とは? "Hello, World!"で基本を押さえる
Rustはどのようなプログラミング言語なのでしょうか? 本連載のスタートとなる今回は、Rust言語の概略と、手元にRustの動作環境構築までを紹介します。導入で利用可能になるコマンドと、最初のHello, World!プログラムも取り上げます。 「Rust」が開発者に最も愛される言語であり続ける理由――Rustを取り巻く状況はここ1年でどう変わったのか
「Rust」が開発者に最も愛される言語であり続ける理由――Rustを取り巻く状況はここ1年でどう変わったのか
人気記事を電子書籍化して無料ダウンロード提供する@IT eBookシリーズ。第69弾は、プログラミング言語「Rust」のニュース記事をeBookにまとめてお送りする。 「Rust」言語はCよりも遅いのか、研究者がベンチマーク結果を解説
「Rust」言語はCよりも遅いのか、研究者がベンチマーク結果を解説
ミュンヘン工科大学の研究チームのメンバーはRust言語で開発したネットワークデバイスドライバの処理速度をC言語のものと比較した。その結果、Rust版の速度低下は最大でも数%にとどまっていた。なぜ処理性能がわずかに遅くなるのか、その理由も説明した。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。