OpenAI Cookbookで学ぶChatGPTプロンプトの基礎の基礎:ChatGPT入門
OpenAIが提供しているCookbookでは大規模言語モデルからの出力をどうすればよいものにできるか、そのノウハウが紹介されています。その基本部分を見てみましょう。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。

筆者がネタに苦しんでいるうちに、マイクロソフトがAzureにChatGPTを含むOpenAIのサービスを採用すると発表したり、ChatGPT Professionalのウェイトリストが用意されたりと、世の情勢は活発にうごいていますね(かわさき)。
OpenAI Cookbook
OpenAIは「OpenAI Cookbook」と呼ばれるリポジトリをGitHubで公開しています。これは、OpenAIが提供するAPIを使って何らかのタスクを行うためのサンプルコードやガイドを示したものです。今回はそのうちのGPT 3に関連する内容を幾つか紹介しましょう。ただし、OpenAI Cookbookで紹介されているノウハウはChatGPTに特化して書かれているわけではないことには注意してください。

このCookbookの「How to work with large language models」ページでは大規模言語モデルを「テキストとテキストをマップする」機能だとしています。純粋なGPTであればテキストを入力すると次にくるテキスト(単語列)を推測するし、InstructGPTやChatGPTであればテキストを入力するとユーザーが入力したテキストの指示に従った返答が得られるということです。
そして、モデルからの出力の質を高めるには、入力するテキストつまりプロンプトがとても重要です。このプロンプトには以下のような種類があります。
- Instructionプロンプト
- Completionプロンプト
- Demonstrationプロンプト
以下ではこれらのプロンプトについて見ていきましょう。
Instructionプロンプト
Instructionプロンプトとは「ユーザーがモデルに何をしてほしいかを伝える」プロンプトのことです。例えば、「○○について教えてください」とか「以下の文章の概要をまとめて」のようなプロンプトのことだと考えられます。
ちょっとした例を以下に示します。

上の画像は本フォーラムの用語辞典の記事「ファインチューニング(Fine-tuning:微調整)とは?」の内容を要約するように指示(instruct)したものです。もう少し文字数が多めでもいいんじゃない? と思いますが、いい具合の要約になっているようです。
Completionプロンプト
Completionプロンプトとは「ユーザーが入力したテキストに続くテキストをモデルに推測してほしい」ときに使用します。例えば「機動戦士」と人にいわれたら、「ガンダム」と続けたくなりますよね。これと同様に、入力されたテキストに続くテキストをモデルに補完(completion)させるようなプロンプトのことです。
「Zガンダム」や他のガンダム作品の名前を続けたくなる人がいることは承知しています(笑)。
実際にChatGPTに「機動戦士」と入力した結果を以下に示します(必ずしもこうなるとは限りません)。

「機動戦士」に続くテキストとして「ガンダム」を推測できましたが、余計なところまで出力してしまっています。Instructionプロンプトとは異なり、Completionプロンプトを受け取った場合、モデルは入力されたプロンプトに続くテキストを推測しますが、推測をどこで終わればよいかは分かりません。そのためにこのような結果になっています。
こうした事態を避けるには、「ストップシーケンス」を指定します。ストップシーケンスはテキスト生成を終了させるトリガーとなります(つまり、ストップシーケンスに指定したテキストにぶつかった時点で、テキストの生成が終了します。また、ストップシーケンスに指定したテキストは生成された出力に含まれません)。
ChatGPTにはストップシーケンスを指定する機能がありません。そこで、InstructGPTのPlaygroundで試してみましょう。こちらには「Stop sequences」欄があるので、ここでストップシーケンスを「ガンダム」に指定します。

上の画像を見ると、InstructGPTからの出力が表示されていません。これは恐らく、「機動戦士」に続けてモデルが「ガンダム」(または「ガ」→「ン」→「ダ」→「ム」のような列)を推測したところ、これがストップシーケンスに合致したために推測がそこで終了し、ストップシーケンスに指定したテキストが出力には含まれないようになっているために、何も出力されなかったところです。
Demonstrationプロンプト
Demonstrationプロンプトとはユーザーがモデルに対して、何らかの例を提示(demonstration)した上で、例を基にモデルに何らかの推測を行ってもらうためのものです。例が少ないfew-shot学習と多数の例を提示してのファインチューニングの2種類があります。
多数の例を用意するのは大変なので、ここではfew-shot学習の例を見てみます。ここでは変数xとyの値を指定して、その加算をしていますが、2つの変数の値の和を求めようとしています。が、ここでは単に加算するのではなく、間に2つの値の2進表記も含めるようにしています。

上の2行がここではデモです。下の2行は2つの変数の値が上とは異なっています。ここで求めたい結果は「x + y =」に続いて「0000 + 0001 = 0001 = 1」のように間に2進表記を含めて和を求めることです。果たして1つの例だけを見て、こうした形式を学習できるのでしょうか。
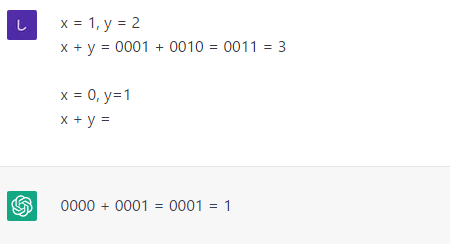 実行結果
実行結果このように思った通りの結果が求まりました。モデルがたった1つの例を見て、どんな形式の出力がほしいかをうまく学習できているようです。
次の例もDemonstrationプロンプトといえるでしょう。1〜3の階乗の計算方法をデモした上で4の階乗はどうなるかを尋ねてみました。
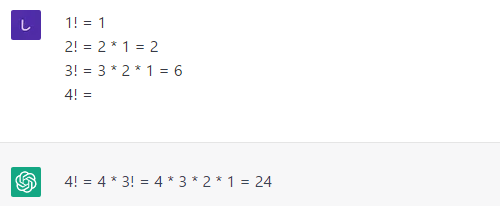 階乗の定義とその計算例
階乗の定義とその計算例デモから階乗の定義を読み取って、「4!」が「4×3!」とした上で、それが「4×3×2×1=24」であると正しく計算してくれました。
それどころか、チャットを新規作成して「4! =」と入力するだけできちんと4の階乗を計算してくれましたから、階乗がどんなものかをChatGPTはすでに学習しているようです(じゃあ、デモする意味なかったじゃん?)。

その場合、階乗の「4! =」に続くテキストを補完したのでCompletionプロントが働いたということなのでしょうかね(一色)。
よりよいプロンプトとは
OpenAI Cookbookではモデルからの出力をよりよいものにするために次のようなテクニックを使うとよいと述べています。
- 明確な指示を与える
- よりよい例を与える
- 専門家のように答えてくれるようにお願いする
- なぜそうなるのかを、一連のステップで書き下すように伝える
「明確な指示を与える」というのは、どんな出力がほしいのかなどを伝えるときに、具体的な要望を伝えることです。以下に例を示します。

最初の指示は単に「階乗を計算せよ」としか伝えていません。その結果は分かりやすいものですが、その結果をコピー&ペーストして流用したいとしましょう。そうなると、もっと簡潔な方が好ましくなります。そこで2つ目の例のようにどんな形式の結果がほしいかを明確に伝えることで、後でChatGPTからの出力を使いやすくなります。
「よりよい例を与える」というのは、プロンプトの中に例を含める場合には、法則性や一般性を全て包括した情報とすることや、そこに間違いがないようにすることといえるかもしれません。例えば、以下を見てください。
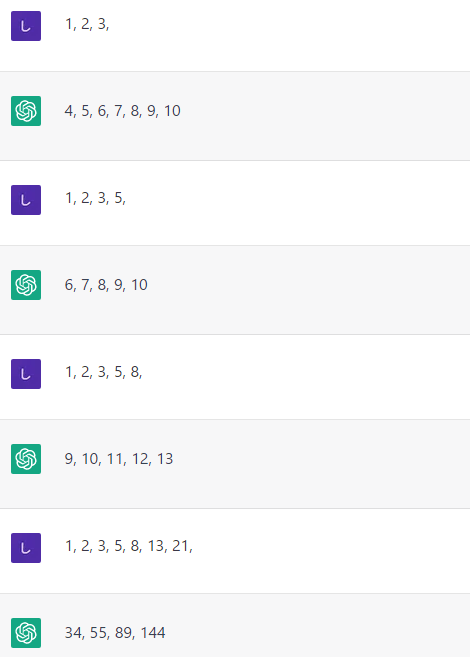 数字の後には何が続く?
数字の後には何が続く?プロンプトとして与えた数列がその後どう続いていくかを推測させようとしています。しかし、冒頭の「1, 2, 3,」だけでは求めたいものは初項1、公差1の等差数列かもしれませんし、フィボナッチ数列かもしれません。そこで、それ以降では幾つか情報を付加することで最終的にフィボナッチ数列が得られるようにしています。察しのよい人(モデル)ならば「1, 2, 3, 5,」とすれば「これはフィボナッチ数列!」となるかもしれませんが、上の画像ではそうはいきませんでした。そこで、「1, 2, 3, 5, 8, 13, 21」のようにモデルに十分な情報を与えることで、望みの結果が得られました。
この反対の意味でよく聞くのが「garbage in, garbage out」(ゴミを入れたら、ゴミが出てくる)ってヤツですね。
「数字の後には何が続く?」の例はDemonstrationプロンプトになっていると思います。それに対して明確に指示するInstructionプロンプトも組み合わせて使うとよいということですね。「機動戦士」の例だったCompletionプロンプトの場合も言葉が足りない印象だったので、それに対しても明確に指示するInstructionプロンプトも組み合わせた方がよさそうだなと思いました。3種類のプロンプト方法がありましたが、組み合わせて使えばよく、特にInstructionプロンプトを使うのが一番重要かなと、ここまで読んで思いました。
「専門家のように答えてくれるようにお願いする」についても例を見てみましょう。以下はPythonについてChatGPTに尋ねたところです。

まあまあの概要が得られたようには思えます。専門家のように教えてもらうと次のようになります(上の質問に続けて入力)。

返された内容には少し高度な話題が含まれるようになりました。もう少し深い話題がほしいといったときには使ってみてもよいかもしれませんね。とはいえ、高度な話題を含んだ出力はそれを見る側にも十分な知識が必要なことには注意しましょう。
「専門家のように教えてもらう」というのはそういうダイレクトな指示なのね。なんか驚いた。だけど「小学生でも分かるように教えてください」などアレンジ可能だと思いました。
最後の「なぜそうなるのかを、一連のステップで書き下すように伝える」というので重要なのは「ステップバイステップで考える」ように伝えることです。以下はその例です。

「ステップバイステップ」を入れるか入れないかで随分と出力が変わることが分かります。これについてはちゃんと計算できているようですが、実は間違った答えを返したときに「ステップバイステップ」で出力を指せるようにすることで正しく答えを導き出せたり、どこでモデルが間違えているかが分かったりする場合もあるようです。
OpenAI Cookbookにそうした例もあるのですが、その例にあるプロンプトを入力してみると、ChatGPTでは正解が得られ、InstructGPTではステップバイステップで考えさせても間違ってしまったので、ここでは別の例を使うことにしました。
というわけで、今回はプロンプトの基礎の基礎を見ました。次回はもう少しプロンプトについて見ていく予定です。
Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。