ディープラーニング習得、次の一歩
ディープラーニングのチュートリアルが一通り終わったら、次に何をやればいいの? 実践に向けて踏み出す人の次の一歩を対象にした連載。
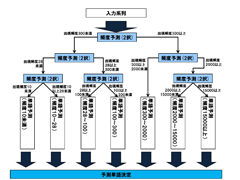
ディープラーニング習得、次の一歩:
「文書生成」チャレンジの後編。ネットワークにLSTM、ライブラリにKeras+TensorFlowを採用し、さらに精度を改善していく。最後に、全然関係ない入力文章から、江戸川乱歩風文書が生成されるかを試す。
[石垣哲郎, 著] ()

ディープラーニング習得、次の一歩:
ディープラーニングによる自然言語処理の一つ「文書生成」にチャレンジしてみよう。ネットワークにLSTM、ライブラリにKeras+TensorFlowを採用し、徐々に精度を改善していくステップを説明する。
[石垣哲郎, 著] ()

ディープラーニング習得、次の一歩:
Keras(+TensorFlow)を使って自然言語のベクトル化手法「word2vec」を実装。学習データに品詞分類を追加することによって、前回よりも予測精度が改善するかを検証する。
[石垣哲郎, 著] ()

ディープラーニング習得、次の一歩:
自然言語のベクトル化手法の一つである「word2vec」を使って、単語間の関連性を表現してみよう。Keras(+TensorFlow)を使って実装する。
[石垣哲郎, 著] ()

ディープラーニング習得、次の一歩:
ディープラーニングのチュートリアルが一通り終わったら、次に何をやる? 今回は、誰にでも簡単にできる「株価予測」をテーマに、LSTMのニューラルネットワークを、Kerasを使って実装する方法を説明する。
[石垣哲郎, 著] ()
スポンサーからのお知らせPR
SpecialPR
注目のテーマ

あなたにおすすめの記事PR
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。