乵柍帇偱偒側偄乶IE偺Content-Type柍帇丗嫵壢彂偵嵹傜側偄Web傾僾儕働乕僔儑儞僙僉儏儕僥傿乮2乯乮1/2 儁乕僕乯
XSS偵CSRF偵SQL僀儞僕僃僋僔儑儞偵僨傿儗僋僩儕僩儔僶乕僒儖乧乧Web傾僾儕働乕僔儑儞偺僾儘僌儔儅偑抦偭偰偍偔傋偒惼庛惈偼偄偭傁偄偁傝傑偡丅偦偙偱杮楢嵹偱偼丄偦偺傛偆側儊僕儍乕側傕偺乬埲奜乭傕孈傝壓偘偰偄偒傑偡乮曇廤晹乯
柍帇偱偒側偄IE偺乽Content-Type柍帇乿栤戣
丂奆偝傫偙傫偵偪偼丄偼偣偑傢傛偆偡偗偱偡丅
丂戞2夞偱偼丄Internet Explorer乮埲壓丄IE乯偺巇條偱傕摿偵埆柤崅偄乽Content-Type柍帇乿偵偮偄偰愢柧偟傑偡丅
丂IE偺Content-Type柍帇栤戣偼旕忢偵暋嶨偱丄巹帺恎傕姰慡偵愢柧偱偒傞帺怣偼側偄偺偱偡偑丄偦傟偱傕僙僉儏傾側Web傾僾儕働乕僔儑儞傪奐敪偡傞偆偊偱旔偗偰偼捠傟側偄栤戣偱偡偺偱丄庢傝忋偘傞偙偲偵偟傑偟偨丅傕偟婰帠撪偵娫堘偄側偳傪尒偮偗偨応崌偼丄偤傂偛巜揈偄偨偩偗傞偲岾偄偱偡丅
丂側偍丄杮峞偱偼摿偵柧婰偟偰偄側偄尷傝丄IE6偍傛傃IE7傪懳徾偲偟偰偄傑偡丅
Content-Type柍帇偵傛傞XSS
丂IE偺Content-Type柍帇栤戣偼丄Web傾僾儕働乕僔儑儞偺奐敪傗専嵏偵偐偐傢傞曽偱偁傟偽堦搙偼帹偵偟偨偙偲偑偁傞偲巚偄傑偡丅
丂椺偊偽丄埲壓偺傛偆側乽僥僉僗僩僼傽僀儖乿傪IE偱奐偄偨偲偟傑偡丅
HTTP/1.1 200 OK
Content-Type: text/plain
<br/>
偙傟偼僥僉僗僩僼傽僀儖偱偡丅
<script>alert("xss");</script>
丂偙偺応崌丄IE偼乬text/plain乭偲巜掕偝傟偨Content-Type僿僢僟偵廬傢偢丄僐儞僥儞僣撪偵娷傑傟傞撪梕偐傜乽HTML乿偱偁傞偲敾抐偟偰丄偦偙偵娷傑傟傞僗僋儕僾僩傪幚峴偟偰偟傑偄傑偡丅
丂偙偺応崌丄IE偼乬text/plain乭偲巜掕偝傟偨Content-Type僿僢僟偵廬傢偢丄僐儞僥儞僣撪偵娷傑傟傞撪梕偐傜乽HTML乿偱偁傞偲敾抐偟偰丄偦偙偵娷傑傟傞僗僋儕僾僩傪幚峴偟偰偟傑偄傑偡丅
丂椺偊偽丄Wiki側偳偺僾儗乕儞僥僉僗僩傪昞帵偡傞傛偆側婡擻傪帩偮Web傾僾儕働乕僔儑儞偵忋婰偺僼傽僀儖傪傾僢僾儘乕僪偡傞偲丄峌寕幰偵傛傞僋儘僗僒僀僩僗僋儕僾僥傿儞僌乮XSS乯峌寕偑壜擻偲側偭偰偟傑偄傑偡丅偙傟偼丄HTML偱偼側偄僐儞僥儞僣偱偁傞偵傕偐偐傢傜偢丄IE偑乽HTML偱偁傞乿偲敾抐偟偰偟傑偆偨傔偵敪惗偡傞栤戣偱偡丅杮幙揑偵偼Web僽儔僂僓懁乮IE乯偱廋惓偝傟傞傋偒栤戣側偺偱偡偑丄偙傟傕戞1夞偲摨偠傛偆偵丄屳姺忋偺栤戣偐傜丄側偐側偐懳墳偑恑傑側偄傛偆偱偡丅
丂埲壓丄IE偑僐儞僥儞僣傪嵟廔揑偵偳偺傛偆側庬椶偺僪僉儏儊儞僩偲偟偰埖偆偐傪乽僼傽僀儖僞僀僾乿偲彂偔偙偲偵偟傑偡丅乽IE偱偼Content-Type傗僐儞僥儞僣偺撪梕傪婎偵僼傽僀儖僞僀僾傪寛掕偟偰偄傞乿偲峫偊傞曽偑僗儉乕僘偵棟夝偱偒傞偐傜偱偡丅
丂偝偰丄IE偑Content-Type偩偗偱側偔丄僼傽僀儖僞僀僾傪寛掕偡傞偨傔偵僐儞僥儞僣偺撪梕傪僗僉儍儞偡傞摦嶌偼乽Content sniffing乿偲屇偽傟偰偍傝丄Content-Type偱巜掕偝傟偨抣傗僐儞僥儞僣偵娷傑傟傞撪梕偵墳偠偰暋嶨偵曄壔偟傑偡丅
丂Content sniffing帺懱偵娭偡傞徻嵶側愢柧偼偙偙偱偼徣偒傑偡偑丄椺偊偽乽Mime Signatures - Web Security Research at Berkeley乿偍傛傃乽Secure Content Sniffing for Web Browsers or How to Stop Papers from Reviewing Themselves
乿偲偄偆帒椏偱偼丄IE偵尷傜偢偝傑偞傑側Web僽儔僂僓偑偳偺傛偆偵撪梕傪僗僉儍儞偟丄僼傽僀儖僞僀僾傪寛掕偟偰偄傞偺偐傪徻偟偔愢柧偟偰偄傑偡丅
丂偙傟傑偱傕宱尡懃偲偟偰乽text/plain偍傛傃image/bmp偺摦揑惗惉偼旔偗傞乿偲偄偭偨偙偲偑峴傢傟偰偒偨偲巚偄傑偡丅
丂偙偺傛偆側丄Content sniffing偵傛偭偰僼傽僀儖僞僀僾偑HTML偲敾抐偝傟偰XSS偑敪惗偡傞偙偲傪杊偖偵偼丄
- IE懁偱偼乽奼挘巕偱偼側偔丄撪梕偵傛偭偰僼傽僀儖傪奐偔偙偲乿傪乽柍岠偵偡傞乿偵愝掕偡傞
- 僒乕僶懁偺儗僗億儞僗僿僢僟偵 X-Content-Type-Options: nosniff 傪捛壛偡傞乮IE8岦偗乯
偲偄偆懳嶔傪峴偄丄Content sniffing傪柍岠偵偟傑偡丅
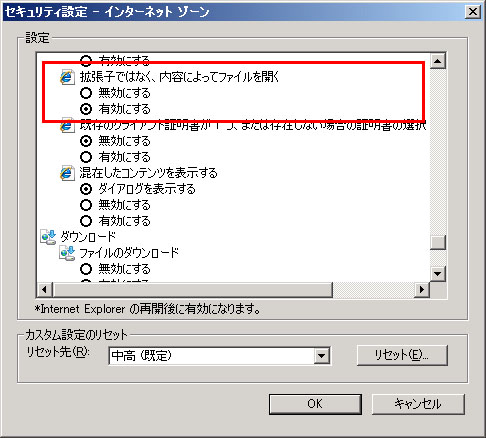
僼傽僀儖僞僀僾傪偳偺傛偆偵敾抐偡傞偺偐
丂慜婰偺傛偆側曽朄偱Content sniffing偺愝掕傪曄峏偱偒傑偡偑丄Content sniffing偼僐儞僥儞僣偺張棟曽朄傪寛掕偡傞偨傔偺梫場偺1偮偵偡偓偢丄Content sniffing偑柍岠偵側偭偰偄傞応崌偱傕丄HTML偱偼側偄傕偺偑HTML偲敾抐偝傟XSS傪堷偒婲偙偡応崌偑偁傝傑偡丅
丂IE偑僐儞僥儞僣偺張棟曽朄傪寛掕偡傞偨傔偺梫場偲偟偰偼丄彮側偔偲傕埲壓偺3庬椶偑巊傢傟偰偄傑偡丅
- 僒乕僶偺儗僗億儞僗僿僢僟偱巜掕偝傟偨Content-Type
- 僐儞僥儞僣帺恎偺拞恎乮Content sniffing乯
- URL
丂IE偼丄偙傟傜3庬椶偺忣曬偲丄儗僕僗僩儕乮HKCR\Mime\Database\Content Type乯偵搊榐偝傟偰偄傞忣曬偵傛偭偰僼傽僀儖僞僀僾傪寛掕偟偰偄傞偲峫偊傜傟傑偡丅
丂儗僕僗僩儕乮HKCR\Mime\Database\Content Type乯偵偼丄IE偑埖偆偙偲偺偱偒傞Content-Type偺堦棗偑奿擺偝傟偰偍傝丄僒乕僶偐傜偺儗僗億儞僗僿僢僟偵傛偭偰曉偝傟偨Content-Type偑丄儗僕僗僩儕偵搊榐偝傟偰偄傞偐偳偆偐偱IE偺摦嶌偼戝偒偔曄傢傝傑偡丅
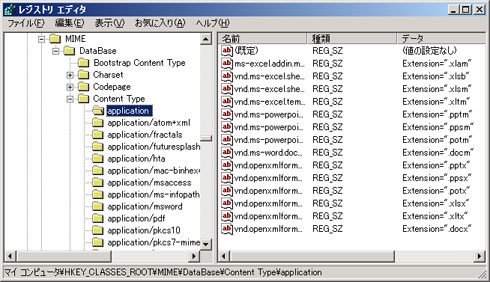
仠儗僕僗僩儕偵搊榐偝傟偰偄傞応崌
丂僒乕僶偺巜掕偟偨Content-Type偑儗僕僗僩儕乮HKCR\Mime\Database\Content Type乯偵搊榐偝傟偰偄傞応崌偼丄偦偺搊榐撪梕偵婎偯偒埲壓偺傛偆偵張棟偝傟傑偡丅
丒IE埲奜偺傾僾儕働乕僔儑儞偑張棟偡傞応崌
丂丂PDF偺傛偆偵奜晹僾儔僌僀儞傪屇傃弌偡偐丄僾儔僌僀儞偑尒偮偐傜側偄応崌偼僟僂儞儘乕僪僟僀傾儘僌偑昞帵偝傟傑偡丅
丒Content sniffing偑桳岠側応崌
丂丂慜弎偺偲偍傝丄Content sniffing偵婎偯偒僼傽僀儖僞僀僾偑寛掕偝傟傑偡丅
丒Content sniffing 偑柍岠側応崌
丂丂僒乕僶懁偱巜掕偝傟偨Content-Type偵廬偭偰丄IE帺恎偑偦偺僐儞僥儞僣傪張棟偟傑偡丅
仠儗僕僗僩儕偵搊榐偝傟偰偄側偄応崌
丂僒乕僶偺巜掕偟偨Content-Type偑儗僕僗僩儕乮HKCR\Mime\Database\Content Type乯偵搊榐偝傟偰偄側偄応崌偼丄IE偼埲壓偺傛偆偵僼傽僀儖僞僀僾傪寛掕偟傑偡丅偙偙偱丄乽URL奼挘巕乿偼URL拞偺僷僗柤偵娷傑傟傞奼挘巕晹暘傪丄乽QUERY_STRING乿偼URL拞偺?埲崀傪巜偡傕偺偲偟傑偡丅椺偊偽丄URL偑乽http://example.com/search.cgi?q=text乿偱偁偭偨応崌丄URL奼挘巕偼乬.cgi乭傪丄QUERY_STRING偼乬q=text乭傪帵偟傑偡丅
丒URL奼挘巕偑乬.exe乭傑偨偼乬.cgi乭偱偁偭偨応崌
QUERY_STRING偺枛旜晹暘偺乬.xxx乭偺晹暘偑奼挘巕偲偟偰巊傢傟丄偦傟偵婎偯偔僼傽僀儖僞僀僾偑慖戰偝傟傑偡丅椺偊偽丄URL偑乬http://example.com/search.cgi?q=abcd.html乭偱偁偭偨応崌丄奼挘巕偼乬.html乭偲側傝丄僼傽僀儖僞僀僾偲偟偰偼HTML偑慖戰偝傟傑偡丅
僼傽僀儖僞僀僾偵懳墳偡傞僴儞僪儔偲偟偰奜晹僾儔僌僀儞偑搊榐偝傟偰偄傞応崌偼丄奩摉偡傞僾儔僌僀儞偑屇傃弌偝傟傑偡丅慖偽傟偨僼傽僀儖僞僀僾偑IE帺恎偱張棟偱偒偢丄奜晹僾儔僌僀儞偺搊榐傕側偄応崌偼丄僟僂儞儘乕僪僟僀傾儘僌偑昞帵偝傟傑偡丅
僼傽僀儖僞僀僾偲偟偰乬.txt乭側偳偑慖戰偝傟偨応崌偵偼丄Content sniffing偑柍岠偵愝掕偝傟偰偄偰傕Content sniffing偑摥偒丄偙傟偵傛傝僼傽僀儖僞僀僾偑寛掕偝傟傑偡丅
QUERY_STRING偵奼挘巕偵奩摉偡傞暥帤楍偑娷傑傟側偄応崌偼丄屻弎偺乽URL奼挘巕偑乬.exe乭偍傛傃乬.cgi乭埲奜偺応崌乿偺傛偆偵張棟偝傟傑偡丅
丒URL奼挘巕偑乬.exe乭偍傛傃乬.cgi乭埲奜偺応崌
URL奼挘巕偑偦偺傑傑僼傽僀儖僞僀僾偺寛掕偵巊傢傟傑偡丅椺偊偽丄URL偑乬http://example.com/search.pl?q=abcd.html乭偱偁偭偨応崌丄奼挘巕偼乬.pl乭偲側傝丄僼傽僀儖僞僀僾偲偟偰偼乬.pl乭偑慖戰偝傟丄偦傟偵墳偠偨僴儞僪儔偑儗僕僗僩儕偐傜専嶕偝傟傑偡丅
僼傽僀儖僞僀僾偵懳墳偡傞僴儞僪儔偲偟偰奜晹僾儔僌僀儞偑搊榐偝傟偰偄傞応崌偼丄奩摉偡傞僾儔僌僀儞偑屇傃弌偝傟傑偡丅慖偽傟偨僼傽僀儖僞僀僾偑IE帺恎偱張棟偱偒偢丄奜晹僾儔僌僀儞偺搊榐傕側偄応崌偼丄僟僂儞儘乕僪僟僀傾儘僌偑昞帵偝傟傑偡丅
傑偨丄椺偊偽URL偑乬http://example.com/search.pl/a.txt?q=abcd乭偱偁偭偨応崌側偳丄僼傽僀儖僞僀僾偲偟偰乬.txt乭側偳偑慖戰偝傟偨応崌偵偼丄Content sniffing偑柍岠偵愝掕偝傟偰偄偰傕Content sniffing偑摥偒丄偙傟偵傛傝僼傽僀儖僞僀僾偑寛掕偝傟傑偡乮戝掞偺CGI僾儘僌儔儉偱偁傟偽丄梋暘側PATH_INFO傪晅梌偟偰傕摦嶌偟傑偡乯丅
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅