SQL Serverのインデックス構造(後編):SQL Server 2000 チューニング全工程(5)(1/2 ページ)
本連載ではSQL Server 2000のチューニングに関するノウハウを解説する。SQL Server 2000は自動チューニング機能を持つために、チューニングはあまり必要ないと思われがちだが、そのアーキテクチャを理解し適切にツール類を使用しなければ、本来のパフォーマンスを得られない。(編集局)
前回は、インデックスの必要性を確認し、SQL Server注 のテーブルに作成できる2種類のインデックス(クラスタ化インデックスと非クラスタ化インデックス)の構造を比較しました。クラスタ化インデックスのリーフ・ページにはキー値が格納されており、データ行の物理的な並べ替えに使用されているのに対して、非クラスタ化インデックスのリーフ・ページには、行識別子と呼ばれるデータ行へのポインタ情報が含まれていることを確認できたはずです。引き続き今回もインデックス構造を解説します。
注)本文中で特に断らない限り、SQL Serverと表記した場合はバージョン2000を指す。また、次期バージョンとなるSQL Server 2005の情報については、適宜盛り込む予定だ。
クラスタ化インデックスがあるテーブルに非クラスタ化インデックスを作成した場合
まず、クラスタ化インデックスがあるテーブルに非クラスタ化インデックスを作成した場合、どのような状態になるのかを考えてみましょう。図1のテーブルイメージで「生年月日」列に非クラスタ化インデックス、「姓」列にクラスタ化インデックスをそれぞれ定義したとします。
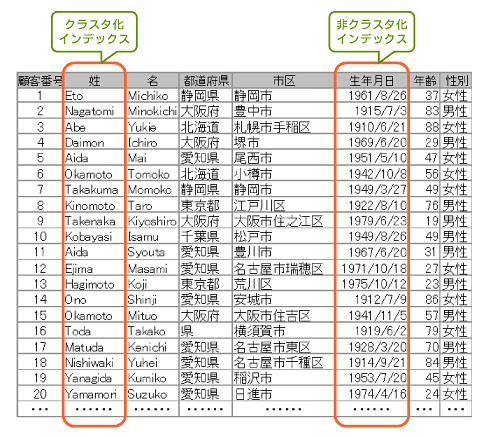 図1 基となるテーブルのデータ
図1 基となるテーブルのデータテーブルにクラスタ化インデックスが存在する場合、非クラスタ化インデックスのリーフ・レベルは物理的な行識別子の代わりにクラスタ化キー値を格納します。非クラスタ化インデックスを付けたキーの検索は、最初に非クラスタ化インデックスのページを使用した検索が行われ、次にリーフで取得したクラスタ化キー値を使用してクラスタ化インデックスの検索を行います。

ところで、図2では疑問を持たれた方がいるかもしれません。「SELECT * FROM 顧客 WHERE 生年月日 = '1951/5/10'」というクエリを実行し、非クラスタ化インデックスのリーフで「1951年5月10日」が生年月日の人として「Aida」を見つけ、それをキー値としてクラスタ化インデックスを検索していましたが、実は、同じ「Aida」という姓で「1967年6月20日」が生年月日の人もいるのです。SQL Serverはどのように重複したクラスタ化インデックスのキー値を識別するのでしょうか?
クラスタ化インデックス・キーは、非クラスタ化インデックスが参照するベース行を識別するブックマークとして使用するため、クラスタ化インデックス内の各行を一意に参照する方法が必要です。この図では描かれていませんが、クラスタ化インデックスに重複するキー値がテーブルに挿入された場合のみ、一意なインデックスとして定義されていなくても、内部的に4bytesの列を追加し、そこに一意な識別子を保持します。(次ページへ続く)
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。