Hadoop亄Hive専徹娐嫬傪峔抸偟偰傒傞丗Hive乗乗RDB巊偄偺偨傔偺Hadoop僈僀僪乮慜曇乯乮1/3 儁乕僕乯
Hadoop Hive偼Hadoop忋偱SQL儔僀僋側僋僄儕憖嶌偑壜擻側DWH岦偗偺僾儘僟僋僩偱偡丅SQL偵嬤偄憖嶌偑壜擻側偨傔丄HBase傛傝傕僨乕僞儀乕僗偵姷傟恊偟傫偩傒側偝傫偵偼巊偄彑庤偑偄偄偐傕偟傟傑偣傫丅杮峞偱偼偙偺Hive偺巊偄曽偲儗價儏乕傪峴偭偰偄偒傑偡丅
Hive偲偼
丂Hive偼丄僆乕僾儞僜乕僗偺戝婯柾暘嶶寁嶼僼儗乕儉儚乕僋Hadoop忋偱摦嶌偡傞僨乕僞僂僄傾僴僂僗乮Data Warehouse丗DWH乯岦偗偺僾儘僟僋僩偱偡丅
丂Hadoop偼丄僌乕僌儖偑幮撪偱棙梡偟偰偄傞GFS偲MapReduce偺僆乕僾儞僜乕僗斉偱偡丅徻嵶偼師偺婰帠傪嶲徠偟偰偔偩偝偄丅

丂Hive偼HiveQL偲偄偆SQL晽偺尵岅偱Hadoop忋偺僨乕僞傪憖嶌偱偒傑偡丅Hadoop忋偺僨乕僞儀乕僗偲偄偆偲HBase偑桳柤偱偡偑丄Hive偼HDFS偵懳偟偰傛傝儐乕僓乕僼儗儞僪儕側僀儞僞乕僼僃僀僗傪採嫙偡傞傕偺偱丄HBase偲偼崻杮揑偵懚嵼堄媊偑堎側傝傑偡丅
仠恾1丂Hadoop偲Hive偺奣擮
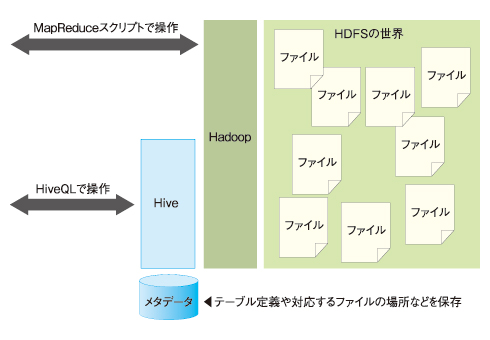 拲丗HDFS偼Hadoop偑嵦梡偟偰偄傞暘嶶僼傽僀儖僔僗僥儉丅
拲丗HDFS偼Hadoop偑嵦梡偟偰偄傞暘嶶僼傽僀儖僔僗僥儉丅丂Hive偼Facebook偱奐敪偝傟丄2008擭12寧偵惓幃偵Hadoop僾儘僕僃僋僩偵婑憽乮contribute乯偝傟傑偟偨丅
丂嵟怴僶乕僕儑儞偑0.19.1偲丄傑偩僶乕僕儑儞傕庒偔丄婡擻傕僪僉儏儊儞僩傕晄懌偟偰偄傑偡偑丄偡偱偵Facebook幮撪偱偼2000戜偺僒乕僶忋偱壱摥偟偰偄傞傛偆偱丄崱屻偺恑揥偵傕婜懸偑帩偰傞僾儘僟僋僩偱偡丅
丂幚嵺丄2寧20擔偵儕儕乕僗偝傟偨0.19.1偱偼儅僀僫乕僶乕僕儑儞傾僢僾偵傕偐偐傢傜偢丄暃栤偄崌傢偣乮僒僽僋僄儕乯傪偼偠傔丄暥帤楍偺楢寢concat( )傗愗傝弌偟substr( )側偳偺暥帤楍娭悢丄count( )傗min( )丄max( )偺廤栺娭悢側偳丄懡偔偺婡擻捛壛偑偁傝傑偟偨丅Hive偵娭偡傞婎杮揑側忣曬尮傪壓偺僐儔儉偵帵偟傑偡偺偱丄偙傟傜偺僪僉儏儊儞僩傕嶲峫偵偟偰傒偰偔偩偝偄丅
丂師儁乕僕偐傜偼丄幚嵺偵Hadoop娐嫬傪庤尦偺儅僔儞忋偵峔抸偟丄Hive偺婎杮揑側憖嶌傪帋偟偰偄偒傑偡丅
僐儔儉仧Hive偺婎杮忣曬
丂Hive偵偮偄偰偺婎杮揑側忣曬偼壓婰Web僒僀僩偵傑偲傔傜傟偰偄傑偡丅杮峞偲偁傢偣偰嶲峫偵偟偰偔偩偝偄丅
- The Apache Software Foundation撪偺Hive僾儘僕僃僋僩偺Web僒僀僩丗
丂http://hadoop.apache.org/hive/ - Hadoop Wiki撪偺Hive娭楢婰帠丗
丂http://wiki.apache.org/hadoop/Hive
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅