C#/Scala/Python/Ruby/F#でデータ処理はどう違うのか?:特集:人気言語でのデータ処理の比較(1/3 ページ)
最近のプログラミング言語は、データ処理をどう設計・実装しているのか? 5つの言語を比較しながらデータ処理の特徴を説明する。

powered by Insider.NET
2011/07/23 更新
■概要
以前、C#でのデータ処理について解説した。今回は、同様のデータ処理を、C#以外のプログラミング言語ではどうしているのか、(C#も含めて)以下の5つの言語を比較しながら説明していく。
- C#
- Scala
- Python
- Ruby
- F#
結果としてできることは似ているのだが、その内部的な実装方法は言語ごとにさまざまである。
■データ処理のおさらい
概念的には、「データ処理」というのは、Figure 1に典型例を示すように、条件選択や変換など、小さな処理単位に分けて、それをつないでいく形を取る。
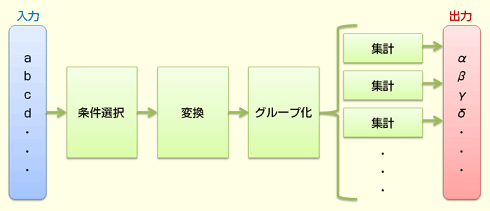 Figure 1 データ処理の概念図(典型例)
Figure 1 データ処理の概念図(典型例)緑色の四角が処理単位となる。行いたい処理によってはこれらの処理単位の順序が変わる。また、条件選択や加工などは、複数回に分けることや、グループ化後にさらに行うことも考えられる。
例えば「顧客情報の中から女性客の年齢分布を調べたい」というときには、C#ならばList 1に示すように書く。1行1行の句が、上述の処理単位になっている。
var 女性客の年齢分布 = // 出力
from c in 顧客一覧 // 入力
where c.性別 == "女" // 条件選択
group c.年齢 by c.年齢 into g // グループ化
orderby g.Key // 整列
select new { 年齢 = g.Key, 数 = g.Count() }; // 集計(Count)と変換(select)
●データ処理のポイント
データ処理のポイントについては、以前、「データ処理の直交化と汎用化」で紹介した。この内容を簡単にまとめると、以下のようになる。
- パイプライン型のデータ処理
- ループで全部まとめて1回で済まさない
- 条件選択、変換、グループ化などを分けて考える
- ストリーム処理
- いわゆるイテレータ・パターンを使って1要素ずつ処理する
- パイプラインのステージごとにバッファを持たない
- 二重ループ相当のデータ列取得が少し厄介
このような要件を満たすため、プログラミング言語ごとにさまざまな構文を持っている。Table 1に比較する。
| パイプライン化 | イテレータ・パターン | 二重ループ相当の列挙 | |
|---|---|---|---|
| C# | 拡張メソッド | イテレータ・ブロック | クエリ式 |
| Scala | トレイト | for式 | |
| Python | ジェネレータ | ジェネレータ式 | |
| Ruby | モジュール | Enumeratorクラス | |
| F# | パイプライン演算子(|>) | シーケンス式 | |
| Table 1 データ処理に向いた構文の比較表 | |||
それでは、これらの構文をそれぞれ説明していこう。
【コラム】各言語における各処理単位を表すメソッドについて
Figure 1のような処理単位を表すメソッドは、名前は違えども、多くのプログラミング言語が標準で備えている。今回紹介する5つの言語に関して、そういったメソッドの比較表をTable 2に示そう。
| C# | Scala | Python | Ruby | F# | |
|---|---|---|---|---|---|
| 条件選択 | Where | filter | filter† | select†† | filter |
| 変換 | Select | map | map† | map/collect†† | map |
| 変換(二重ループ相当) | SelectMany | flatMap | flat_map†† | collect | |
| グループ化 | GroupBy | groupBy | groupby | group_by | groupBy |
| 集計 | Aggregate | foldLeft | reduce | reduce | |
| Table 2 データ処理用のメソッド比較表 † Python 2系では、mapメソッドやfilterメソッドはストリーム的ではなく、一時バッファを作って返す(3系ならばイテレータを返す)。Python 2系でストリーム的な処理を行いたい場合、itertoolsモジュールのimapメソッドやifilterメソッドを使う。 †† Rubyの標準の(Enumerableモジュールの)mapメソッドやfilterメソッドは一時バッファを作って返す。標準では、ストリーム的に処理する手段はない(現在、追加を検討中の模様)。また、flat_mapはバージョン1.9系で利用可能。 | |||||
■パイプライン型のデータ処理
メソッド(あるいは関数)の呼び出しには、Figure 2に示すように、入れ子型とパイプライン型(メソッド・チェーン(method chain))の2とおりの書き方がある。そして、データ処理において近年好まれているのは後者のパイプライン型である。
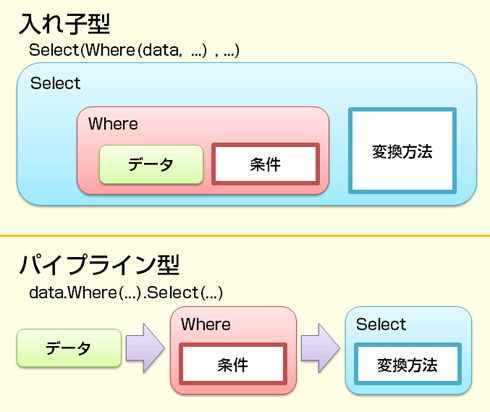 Figure 2 入れ子型とパイプライン型のデータ処理
Figure 2 入れ子型とパイプライン型のデータ処理要するに、語順としては、インスタンス・メソッドのような後置き記法の方が、静的メソッドやグローバル関数のような前置き記法よりも好まれる。しかし、「後置き記法にしたい」という理由だけでインスタンス・メソッドにしてしまっていいのだろうか。
「この目的のためだけに派生クラスを作る」という手段は汎用性に欠ける。特定の具象クラス(ListやDictionaryなど)に機能を追加することはできても、インターフェイス(IEnumerableなど)に機能(実装を持つメソッド)を追加することはできない。
* 残念ながら、Pythonのデータ処理(mapメソッドやfilterメソッド)ではパイプライン型の書き方はできず、入れ子型になる。
●C#
そもそも、publicなメンバしか参照しないような機能(特に、インターフェイスに対する何らかの処理)であれば、静的メソッドを作ることでいくらでも追加できる。そして、後から追加したいような機能のほとんどは、publicメンバ(それも特に多いのは、具象クラスのpublicメンバではなく、インターフェイスで定義されているメンバ)しか参照しない。
結局、静的メソッドを後置き記法で書ければ、すべて解決するのである。それを実現するのがC#の「拡張メソッド」*1という構文だ。List 2に示すように、静的メソッドの第1引数にthisキーワードを付けることで、静的メソッドを後置き記法で書けるようになる。
using System;
using System.Collections.Generic;
class ExtensionSample
{
public static void Run()
{
var data = new[] { 1, 2, 3, 4, 5 };
var squared = data.Select(x => x * x);
// ↑
// Extensions.Select(data, x => x * x); と同じ意味
foreach (var x in squared)
{
Console.WriteLine(x);
}
}
}
// 静的クラスである必要あり
static class Extensions
{
// public static で、第1引数に this キーワードを付ける
public static IEnumerable<U> Select<T, U>(
this IEnumerable<T> data, Func<T, U> selector)
{
foreach (var x in data)
{
yield return selector(x);
}
}
}
*1 拡張メソッドの利点は、ここで説明しているような「インターフェイスに対する処理を後置き記法にできること」と、「第三者が後から機能を追加できること」という2つの側面がある。Table 1では、拡張メソッドとの対比として「トレイト」と「モジュール」を挙げているが、これは前者視点(後置き記法)である。後者視点(後からの機能追加)も含めると、Scalaは「トレイト+暗黙的型変換」、Rubyは「モジュール+オープン・クラス」となる。
●Scala
Scalaでは、(ほかの言語でいうインターフェイスに相当する)「トレイト(trait: 特質)」が実装を持つことを認めている。
列挙可能であることを表すトレイトのIterableやIterator(C#でいうIEnumerableやIEnumerator)自身が、mapやfilterなどのデータ処理用メソッドを持っている。例えば、IteratorトレイトはList 3に示すような実装になっている。
trait Iterator[+A] extends TraversableOnce[A] {
// 抽象メソッド
def hasNext: Boolean
def next(): A
// 実装も持てる
def map[B](f: A => B): Iterator[B] = new Iterator[B] {
……省略(後述)……
}
def filter(p: A => Boolean): Iterator[A] = new Iterator[A] {
……省略(後述)……
}
……省略……
}
トレイトやクラスの作者以外の第三者が機能追加したい場合、Scalaでは暗黙的型変換(implicit conversion)を多用する。暗黙的に別のクラスに変換して、変換後のクラスのメソッドを呼ぶことで、メソッドが追加されたように見せかける。例えば、List 4のように書く。
implicit def intSquare(i : int) = new { def square() = i * i }
変換元(i)を参照する匿名型を作る。これはあまり良い例ではないが、整数に対して「square」という名前のメソッドを追加している。
●Ruby
Rubyでは、mix-in的にクラスに機能を取り込むために、「モジュール」という機能を持っている。
Rubyのモジュールは、動的言語らしく、インターフェイスのようなメンバ定義を必要としない。ダック・タイピング的に、「その名前のメソッドを持っていれば、どんな型でも受け付ける」というような仕組みで動く。
例えば、EnumerableモジュールはList 5に示すような実装を持つ。「モジュールを取り込むクラスがeachメソッドを持っている」という前提で実装を書く。
module Enumerable
def map(&blk)
ary = []
each { |x| ary.push blk[x] }
return ary
end
……省略……
end
実際には、パフォーマンス上の理由からEnumerableモジュールはC言語で実装されているが、意味的にはこうなっている。
モジュールを取り込む側は、例えば、List 6に示すような書き方をする。Enumerableモジュールが前提としているeachメソッドの実装が必須となる。
class Array
include Enumerable
def each
……省略……
end
end
Rubyでは、元々、第三者がクラスやモジュールに自由にメソッドを追加可能である(このような方針を「オープン・クラス」と呼ぶ)。型情報を後から(しかも動的に)書き換えてしまえる辺りも、動的言語ならではの方針である。
●F#
単に語順の問題なのであれば、語順をひっくり返す演算子を作ればいい。演算子を自由に定義できるF#では、それが可能なのである。
F#には「パイプライン演算子(|>)」というものがあり、List 7に示すように、関数適用の語順を入れ替えることができる。
let data = seq { 1..5 }
let squared = data |> Seq.map (fun x -> x * x)
// ↑
// Seq.map (fun x -> x * x) data と同じ意味。
for x in squared do
System.Console.WriteLine x
パイプライン演算子の定義は以下のようなものである。
let (|>) x f = f x
「|>」という記号を(キーボードで)入力しづらいのが難点ではあるが、特殊な文法ではなく、単なる演算子で実現できる点が、F#の強力さを物語っている。
続いて次のページでは、イテレータ・パターンについて説明する。

Copyright© Digital Advantage Corp. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。