‘愛’で学ぶ文字コードと文字化けの常識:プログラマーの常識をJavaで身につける(6)(1/4 ページ)
本連載は、Java言語やその文法は一通り理解しているが、「プログラマー」としては初心者、という方を対象とします。Javaコアパッケージを掘り下げることにより「プログラマーの常識」を身に付けられるように話を進めていきます。今回は、文字コードや文字化けについて。OSや携帯電話の機種の違い、メール、Webブラウザ、DB入出力、国の違いなどさまざま原因で起きる文字化けを徹底解説!
文字コードや文字化けの知識はプログラマーの常識
今回は、文字コードや文字化けなどの文字に関する常識をJavaを通して身に付けていきます。
私たちプログラマーにとって、文字や文字列を扱うことはとてもありふれたことです。ほとんどのプログラムにおいて、何らかの形で文字や文字列を扱っていることでしょう。
インターネット時代には必須の知識
コンピュータ1台で動作するプログラムを扱っている範囲では、皆さんは特に何の困難に出合うこともなく文字や文字列を扱っておられるかもしれません。ところが、ファイルやネットワークを経由したほかのコンピュータとのデータ交換を取り扱い始めた途端、文字コードや文字化けといったキーワードがあなたの前に立ちはだかる場合があります。
文字コードや文字化けといったものはある程度経験を持ったプログラマーにとっても難易度の高いもののひとつです。しかし、インターネットが普及してネットワークを経由したコンピュータ利用などが常識化した現代においては、文字コードや文字化けといった知識はプログラマーに常識として求められるようになってきたものと考えられます。
この記事では、文字コードや文字化けといったものについての全体像をお伝えすることを目標とします。また、あなたが文字コードや文字化けで困ったときの道しるべとなる、いくつかの情報源を示します。
「文字化け」は科学的な現象である
ある文字を表すデータが入力され、コンピュータ上のデータ処理やデータ表示などを経由して最終的に表示/印字などの形で出力された際に、別の文字に見えるように変わってしまった(化けてしまった)という現象は一般に「文字化け」と呼ばれます。「文字化け」は、なんだか「おばけ」みたいな語感ですが、基本的に再現性のある科学的な現象です。
 図1 「狸」が化けてしまった
図1 「狸」が化けてしまったなお、この記事では特によく現れる文字化けのみを扱います。例えば、ハードウェア的な原因や通信品質などといったものに起因する文字化けの話題などは扱いません。
立ち戻るべき文字コードの情報源
文字コードに関する一次情報源
私たちがコンピュータ関連の技術を調べていくうえで、一次情報源に立ち戻ることは、とても重要です。国際規格や国家規格として文字コードの一次情報源が提供されています。それらのうちでも、特に参照するべきものは以下となります。
▼国際標準化機構(ISO - International Organization for Standardization)による規格。
例:ISO/IEC 646
▼日本工業規格(JIS - Japanese Industrial Standards)、例:JIS X 0208:1997
これらの規格は販売されています。
また、文字コードに関連する各種情報源として、以下のものもよく参照する必要が出てきます。
▼IANA(Internet Assigned Number Authority) Charset Registry、例:シフトJISやWindows-31Jという登録名、例:シフトJISやWindows-31Jという登録名
▼IETF(Internet Engineering Task Force) RFC
このような文字コードに関するさまざまな規格や標準があるからこそ、そして、それら規格や標準をみんなで守っているからこそ、異なる複数のコンピュータ間で通信などを行うことができます。
ただし、これらの規格や標準は、文字コードに関連する各種技術に不慣れな人が参照するには、難易度が大変高いものです。正しいものでも、理解できないことには使いこなすことができません。文字コードを学ぶ場合、まずは一般書籍などから接していくことをお勧めします。なお、オススメの参考書籍は、この記事の最後のページで紹介しています。
Java言語における文字コード関連の記載
Java言語における文字コード関連情報は、以下などに記載があります。
このドキュメントに記載があるように、多くのユーザーはjava.nio.charsetパッケージを直接使用することはほとんどありません。その代わりに、java.lang.String、java.io.InputStreamReaderやjava.io.OutputStreamWriterクラスを使用します。
‘愛’で学ぶJava言語における文字と文字列
ここからは、Java言語に話題を移します。最初に基本に立ち返り、Java言語における文字と文字列とを復習しておきましょう。Java言語では、ほかのいくつかのプログラミング言語と同様に、「文字」と「文字列」は別のものとして実装されています。
| プリミティブ型 | 参照型(クラス型) | 説明 | |
|---|---|---|---|
| 文字 | char | java.lang.Character | 本来のUnicode仕様に基づく「Unicodeスカラー値」。U+0000〜U+FFFFの文字セットは、「基本多言語面(BMP)」と呼ばれ、この範囲の文字はchar1つが1文字を表す。U+FFFFよりも大きいコードポイントを持つ文字は、「補助文字」と呼ばれ、この範囲の文字はchar2つで1文字を表す(詳細はjava.lang.Characterを参照) |
| 文字列 | (※対応なし) | java.lang.String | 0個以上の文字によって構成される文字列 |
| 表1 Java言語における文字と文字列 | |||
このように、文字と文字列とはJavaでは別のものとして扱われます。そして相互に変換しながら利用していく場合が多いです。
charは文字であるとともに整数でもある
一方、連載第3回で説明したように、charはJava言語にとってプリミティブの整数型という側面を持っています。文字を扱うプログラミングを行っていくと、charを数値として処理する場合もありますので、その際にはcharが整数でもあることを思い出してください。
文字と文字列との相互変換
それでは、実際に文字と文字列との相互変換を中心に見ていきましょう。
まず、文字列を文字の配列に変換するところから見ていきます。java.lang.Stringをchar配列に変換するには、toCharArrayメソッドを用います。
|
これを実際に実行すると、下記のようになります。
実行結果
文字列[愛植岡]を文字に分解。
0番目: [愛]
1番目: [植]
2番目: [岡]
与えられた文字列が、文字の配列へと分割されていることが確認できます。ここまでは、ごく普通の出力結果ですね。これを掘り下げて、文字(char)の内容を16進表記で見てみます。プログラムを少し変更して、Integer.toHexStringにより16進表記を取得します。
|
実行結果は以下のようになります。このように16進表記を行うと、charが文字であると同時に数値であることが確認できます。
実行結果
文字列[愛植岡]を文字コードに分解。
0番目: [611b]
1番目: [690d]
2番目: [5ca1]
ここで表示された611bなどの数値を用いて、今度は文字(char)へと変換できることを確認します。Java言語の文字定数の記法として'\u611b'のような書き方があります。ここで得られた611b、690d、5ca1の値からchar配列を作成し、それから文字列を作ります。
|
確かに、元通りの文字列が得られることが確認できます。
実行結果
文字の配列から文字列を作成。
配列から作られた文字列は[愛植岡]です。
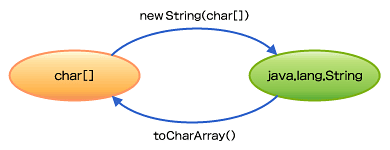 図2 文字配列と文字列の相互変換
図2 文字配列と文字列の相互変換文字コードとは? 文字エンコーディングとは?
文字コードとは、文字を数値で表現するもの
このように、Java言語では‘愛’などの文字1つずつが、611bといった数値によって表現されています。この、文字に対応する数値のことを「文字コード」と呼びます。また、文字と文字コードの対応をひとまとめにしたものを「文字エンコーディング」と呼びます。
Java言語では、UTF-16という文字エンコーディングを内部的に採用しています。‘愛’が611bになるのは、UTF-16エンコーディングによるものなのです。
では、世界中のコンピュータで‘愛’の文字コードが常に611bになるのかといえば、そうではありません。例えば、ある文字エンコーディング(シフトJISエンコーディング)では、‘愛’は88 a4 という2バイトの数値で表現されます。また、ある文字エンコーディングでは、そもそも‘愛’という文字を扱えません。
符号化文字集合と文字符号化方式
文字エンコーディングについて考える際には、「どのような文字」が「どのような数値」で表されているかを理解しておく必要があります。
文字エンコーディングに「どのような文字」が含まれているかを規定したものを「符号化文字集合」と呼びます。符号化文字集合の中にその文字が含まれていれば扱うことができ、含まれていないと扱うことができません。
また、符号化文字集合(どのような文字)に含まれている文字を、「どのような数値」で表現するのかを規定したものを「文字符号化方式」と呼びます。文字符号化方式によって、‘愛’が611bになったり、88 a4 になったり、あるいは別の数値になったりというように、ある文字を表す数値は変化します。
なお、文字エンコーディングを調べていくと、規格や標準によって、符号化文字集合と文字符号化方式とを分けて考えたり、あるいは両方をセットで考えたりするものがあります。ここは混乱しやすいポイントの1つですので、ご注意ください。なお、この記事では、符号化文字集合と文字符号化方式の両方を併せて「文字エンコーディング」と呼ぶことにします。
コラム 「文字コード? 文字エンコーディング? どっち!?」
「文字コード」という用語は、一般的なコンピュータ関連ドキュメントの前後の文脈によっては「文字エンコーディング」を指している場合があります。「文字コード」の記載が、文字の値を指しているのか、それとも「文字エンコーディング」を指しているのか、読み分けましょう。
夢の文字コード標準「Unicode」
「世界中の文字にユニークな数値を割り当てたい」という夢のような文字コード標準が、Unicodeです。世界中の文字を、1つの符号化文字集合として取り扱うことができるように、標準化団体が活動しています。
サロゲートペア【Unicodeのアキレス腱 その1】:未対応が多い
表1に記載したように、ほとんどの場合はchar1個が1文字を表します。char1個が常に1文字を表してくれるのであれば、プログラミングは簡潔になります。ところが、「補助文字」の場合には、char2個が1文字を表すようになっているので、注意が必要です。このようにchar2個で1文字を表現することを、サロゲートペア(Surrogate Pair)と呼びます。
サロゲートペアはJava言語そのものにおいて適切にサポートされています。また、最近のOSでも、サロゲートペアは適切に扱えるようになってきました。しかし、サロゲートペアに適切に対応したアプリケーションは原稿執筆時点では少数派である、というのが実情です。さらに、フォントについてもサロゲートペア対応のものを利用する必要があります。詳しくは『文字コード超研究』の460ページなどをご覧ください。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。