進化し続けるReiserFS:Linuxファイルシステム技術解説(5)(1/2 ページ)
Linux用ジャーナリングファイルシステムとしては古参ともいえるReiserFS。そのアルゴリズムや新バージョン「Reiser4」の機能について解説する。(編集局)
ReiserFS概要
RiserFSは、Hans Reiser氏率いる開発チームにより1996年から開発が開始されたファイルシステムで、カーネル2.4.1から標準カーネルに取り込まれた。カーネル2.5からは機能強化されたバージョン4(Reiser4)が取り込まれている。
B*-Treeアルゴリズム
NAMESYS(http://www.namesys.com/)の紹介の序文に、「ReiserFSは従来のデータベースで実装されてきたB-Treeアルゴリズムをファイルシステムに実装する試み」と書かれているように、ReiserFSは開発当初よりB-Treeアルゴリズムを効率よく実装することを目指していた。
Reiser氏を中心とする開発メンバーは、このB-Treeアルゴリズムをさらにファイルシステムに適したB*-Treeとした。B*-Treeではデータオブジェクトをツリー構造の中に収め、ノードの検索に当たる部分をキャッシュに置くことで高速な検索を実現している。
大きなファイルの読み書きはハードなどの制約があるため差が出にくいが、多数のファイルがあるディレクトリで目的のファイルを探す場合などは、このアルゴリズムのメリットが得られる。
■ディスクスペースの効率的利用
ブロックファイルシステムは、各ブロックに1つのiノードが保持されるため、ブロックのサイズよりも小さいファイルを作成した場合は残りのスペースが無駄になる。
これに対して、ReiserFSではエクステントを採用しているため、ファイルサイズに合わせた領域の確保が行いやすく、ディスクの利用効率が良い。また、小さいファイルをできるだけ近くに配置することで、ディスクのシークを分散させずに効率的にファイルサーチできるようになっている。
■ジャーナリング機能
ReiserFSはジャーナリング機能も実装している。v3の初期(カーネル2.2辺りまで)の安定性はあまり高いとはいい難かったが、カーネル2.4で取り込まれたv3.6ではジャーナリング機能の強化を含め、パフォーマンス的にも安定性の面でも格段に向上している。
ジャーナリングの基本的な手順は通常のジャーナルと同様で、ファイルシステムへのアトミックな処理をトランザクションとして扱い、トランザクションがメタ・データをディスクに書き込む形式となっている。
■Reiser4
カーネル2.5から取り込まれたReiser4では、B*-Treeの見直しによるパフォーマンスの改善、セキュリティの強化、機能のコンポーネント化をさらに推し進め、プラグインという形でACL(Access Control List)や暗号ファイルのサポートといった拡張機能の取り外し機構が実装されている。また、パフォーマンス向上のために、新しいジャーナリング方式の実装を試みている。
■オブジェクト指向
Reiser氏は、「Plan9(注)でOSの名前空間の分割(オペレーティングシステム内の機能を、オブジェクト指向を取り入れて分割する考え方)にかかわってきた」と述べているように、ReiserFSでも機能を分割してインターフェイスを適切に定義することで、ソフトウェアをより機能的、効率的にするというオブジェクト化を目指している。Reiser4から実装された、機能をプラグインとして組み込めるようにするといった試みも、こうした考え方を積極的に取り入れた成果の一部といえるだろう。
注:1995年にBell研究所によってリリースされたオペレーティングシステム。
B*-Treeの設計と特徴
ReiserFSは、ファイルサイズの大小によらず高い性能を実現することと、ディスクスペースに無駄が生じない設計が目標とされている。このために、第2回で説明したように、ReiserFSは設計のベースにB-Treeを使用している。
B-Treeは、
- ルートからすべての葉までの経路の長さが等しい
- 複数の子を持つ
といった特徴によりO(log n)でサーチ可能となり、高速なファイルアクセスが保証される。
ReiserFSではさらに、このツリー構造の中にすべてのファイルシステムオブジェクトを格納するという拡張を施している。それがB*-Treeである。これにより、すべてのデータがその管理情報であるメタ・データと近い位置に格納されるため、両方の情報に高速にアクセスできる。さらに、特に小さいファイルはまとめて管理するなどの方法により、シークの分散を低減している。また、動的iノード(第3回参照)により、iノードの制限によらず柔軟に新しいファイルが作れるようになっている。
B*-Treeの構造について、もう少し詳しく見ていこう。
■キーの値
ReiserFSでは、ツリー構造の中に保存されているすべてのデータは「キー(Key)」と呼ぶ番号を持っている。もともとBalanced-Treeはキーとなる値の大小によってルートからのアクセスのバランスを常に保つ仕組みであるが、ReiserFSでも検索やソートはこのキーの値を基に行う。
■ノード、アイテム
一般的に、Balanced-Treeの枝に当たる部分を「ノード」という。子を持つノードをインターナルノード(内部節)、子を持たないノードをリーフ(葉)と呼ぶ。ReiserFSでは、すべてのノードは同じサイズになっている(注)。
注:Reiser4からは、1つのノードのサイズはページサイズである4Kbytesに統一されている。
ReiserFSでは、オブジェクトをツリー構造の中に格納する。だが、4Kbytesのノードに直接オブジェクトであるファイルを保存するとどうなるだろう? ノードサイズよりもファイルが大きい場合は分割が必要となる。反対に、ファイルが小さい場合はスペースに無駄が生じるため、それを管理する方法が必要となる。
この問題に対して、ReiserFSでは「アイテム」というファイル格納のためのデータ構造が利用される。アイテムはエクステントをベースとしたファイル管理手法で、次のようなデータ構造を持つ。
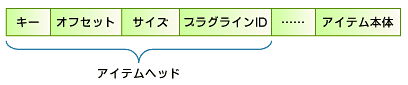 図1 アイテムのデータ構造
図1 アイテムのデータ構造図1のように、アイテムはファイルの大きさ(サイズ)を保持するだけで、実際のブロックは保持しない。そのため、ファイルの大小の制限を受けずに管理できる。
アイテムを含むノードを「フォーマットノード」とも呼ぶ。また、アイテムを持たないリーフを「非フォーマットリーフ」と呼ぶ。非フォーマットリーフは、形式化された情報を持たず、データのみを保持する。リーフのみが、このような形式を取ることができる。ReiserFSでは、ファイルの管理情報を持つアイテムをデータのコンテナ(格納庫)として、フォーマットノードに格納する。
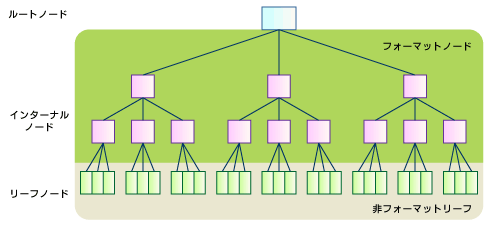 図2 ReiserFSのノード構造
図2 ReiserFSのノード構造フォーマットノードはすべてアイテムを持っており、その中のキー値によってソートされている。非フォーマットリーフはキー値を持っていないので、ソートの対象にはならない。つまり、インターナルノードがキー値を持つインデックスの役割をし、リーフがデータを保持する形式となっている。各フォーマットノードは、次のノードまたはリーフへのポインタ(ノードポインタ)を保持している。
非フォーマットリーフへのポインタには、エクステントが用いられている。エクステントの仕組みについては、第3回を参照。
- ノードポインタ
フォーマットノードへのポインタ。インターナルノードは、キー値によって区別されたサブツリーに対するポインタによって構成されている。 - エクステントポインタ
非フォーマットリーフへのポインタとして使われる。エクステントは第3回で述べたように、エクステントの開始ブロック番号とオフセットを保持している。
ReiserFSでは、常にルートノードからバランス木を下って目的のアイテムを指し示すフォーマットノードのポインタをたどり、最終的に非フォーマットリーフのデータを得る。データが新しく追加された場合は、ツリーのトップから保存にふさわしい場所が選ばれ、フォーマットノードにアイテムと非フォーマットリーフが追加される。
Reiser4のデータ構造は、正式にエクステント方式になった。表1のとおり、各ノードには複数のアイテムが格納される。
| static_stat_data | 所有者、許可、最終アクセス時間、作成時間、サイズ、リンク数 |
|---|---|
| cmpnd_dir_item | ディレクトリエントリ、リンクしているファイルのキー |
| extent pointers | エクステントデータへのポインタ |
| node pointers | アイテムを保持するノードへのポインタ |
| bodies | ファイル部分 |
| 表1 アイテムのデータ構造 | |
オリジナルのB-Treeでは通常、キーや他ノードへのポインタだけでなくデータもインターナルノードに保持する。B*-Treeは前述のとおり、実際のデータはすべてリーフノードに置き、インターナルノードをキャッシュに置くことで検索を高速化している。
ディスクの効率的利用
ReiserFSでは、大きいファイル(Large File)と4Kbytes以下のファイルで扱いが異なる。大きなファイルはディスクに分割して保存され、小さいファイルは集めて保存される。
■大きいファイルの分割
大きいファイルの分割は、ノードサイズに合わせて行う。分割されたファイルはそれぞれアイテムとして1つのノードに収められる。
ブロックアルゴリズムでは、ファイルは連続的に確保されるため、ブロックサイズと合わない大きさのファイルの場合にブロックのスペースが無駄になるというデメリットがあった。ReiserFSは上記の方法を取ることにより、スペースを効率的に利用している。ReiserFSのWebサイトによると、ブロックアルゴリズムよりも最大で80%も領域を節約できるとしている。
■小さいファイルの集積
ブロックアルゴリズムでは、ブロックサイズ以下のファイルもブロックに保存されるため、スペースに無駄が生じるというデメリットがあった。ReiserFSでは小さいファイルを複数まとめて保存する。
初期のReiserFSはPackingという手法により、多数の小さいファイルを1つのノードに詰め込んでいた。小さいファイルが削除された場合は、削除によって生じたスペースを詰める作業を行っていた。しかし、こうした作業を頻繁に行うのは逆にパフォーマンスに悪影響が出るということで、この方式は修正されている。現在は小さいファイルをできるだけ近くに配置することで、ディスクのシークを分散させず効率的にファイルをサーチできるようにしている。
パスの改善
B+Treeは、B-Treeよりも1ノード当たりの子ノード数を増やしている。子ノードの数(n)を増やすほど、リーフ(データ)までのパスの回数が減ることになり、効率的に目的のデータにアクセスできる。こうしたB+Treeの特性もReiserFSのB*-Treeに取り込まれている。
5パスから4パスへの高速化
ReiserFS v3は、図3のようにノードの最後の部分(リーフ)にBLOBs(Binary Large OBjects)と呼ばれる方法でオブジェクトを保存していた。BLOBsは、ノードよりも大きいオブジェクトがある場合は、リーフノードがこれらのオブジェクトを指す複数のポインタを持つ。しかしBLOBsが使用されるケースでは、実際はレベル1以上にパスが増えてしまうため実質的に5階層になり、パフォーマンス上の問題があった。
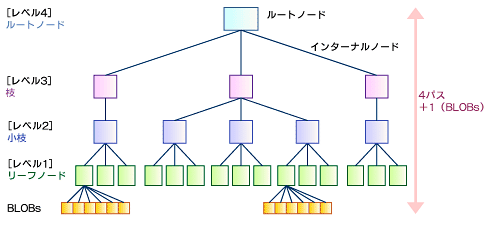 図3 ReiserFS v3のツリー構造
図3 ReiserFS v3のツリー構造Reiser4では、再度バランス木の原則に立ち返って、図4のようにレベル1まで高さでバランスをそろえる形に改善された。特にレベル1をエクステントに統一することで、ファイルのサイズを指定できるようにした。ノードの制限の中で大きなファイルを扱えるようになるため、パスの長さをレベル1の範囲に収められる。検索効率も良くなるので、パフォーマンスも向上している。
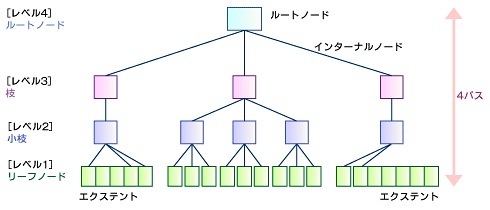 図4 Reiser4のツリー構造
図4 Reiser4のツリー構造Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。