ルーティングの設定は正しいか?〜route/traceroute(tracert)〜:ネットワーク・コマンドでトラブル解決(3)
IPパケットはなぜ届くか?
ネットワークの働きを一言で表現するなら、「バケツリレーの参加者の集まり」だと言えるだろう。水をバケツからバケツへと次々に受け渡し、最後には火元まで届けることができる。
ネットワークでの通信もまったく違いはない。水がIPバケット、バケツがルータやホストなど通信にかかわる機器である。IPパケットに記載された「宛先IPアドレス」を元に、ネットワークに参加する機器が次々に受け渡していくのである。
このようなネットワーク通信は「ルーティング」と呼ばれる。つまり、通信のために最適と思われる「経路」が取り決められているからこそ、実際にIPパケットをやり取りできるのだ。ネットワークにおけるルーティングとは、このような経路を把握し、あらかじめ経路の設定を行うことなのだ。
例を示そう。図1は実際のルーティングの様子だ。IPパケットをルーティングするプロトコルは、IPの下位プロトコルであるイーサネット(IEEE802.3)などの第2層(データリンク層)のプロトコルだ。ルーティングは、このデータリンク層とIPとの関係によって行われる。
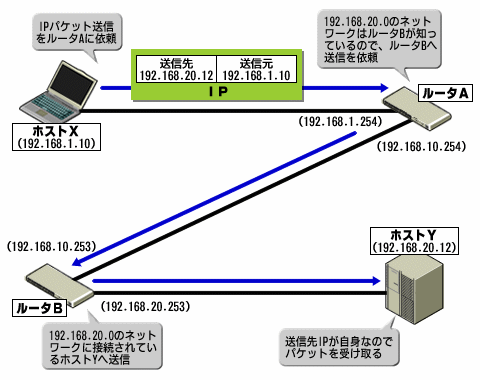 図1 ルーティングの模式図
図1 ルーティングの模式図この例では、IPパケットがホストYに届くまでに、2つのルータがパケットを転送しているのが分かるだろう。ポイントは、これらルータは目的のホストが「どのルータのネットワークに接続されているか」を互いに把握しているという点だ。例えば、ネットワーク上には宛先となり得るホストは星の数ほどある。バケツリレーで例えるなら、火元は1つではないのだ。いくつもの火元があり得るので、ある目的の火元に間違いなく水を運ぶためには、バケツリレーの参加者は「その火元に届けるためには、自分の周りの誰に渡せばよいか」を知らなくてはならない。これなくして、思い通りのところに水を届けることは不可能だ。
このようなルーティングのために必要となる「どこにどのホストが接続されているか」の情報が「ルーティングテーブル」である。ルーティングテーブルは、ルーティングを行うプログラム(ほとんどの場合はOSなどの基本機能)がメモリに展開するテーブル型のデータだ。ほぼすべての機器で保持するデータ内容は共通しているので、仮想的にこのように呼ばれている。
ルーティングテーブルの利用方法
では、ルーティングテーブルにはどのような情報が必要になるのだろうか。以下は、図1のルータBにおけるルーティングテーブルの例だ。
| 宛先IPアドレス | サブネットマスク | インターフェイス | ゲートウェイ | メトリック | |
|---|---|---|---|---|---|
| 192.168.1.0 | 255.255.255.0 | 192.168.10.253 | 192.168.10.254 | 1 | |
| 192.168.10.0 | 255.255.255.0 | 192.168.10.253 | 192.168.10.253 | 0 | |
| 192.168.20.0 | 255.255.255.0 | 192.168.20.253 | 192.168.20.253 | 0 | |
| 表1 ルータBにおけるルーティングテーブルの例 | |||||
実際にはもう少し多くのエントリーを含むのであくまで例として見ていただきたいが、図1で示したネットワークであれば、以上の3エントリーがあってようやくルーティングは正常に機能するようになる。
それぞれのエントリーが、実際の物理ネットワーク(サブネット)への経路情報を示していることは理解していただけるだろう。ルーティングテーブルとは、宛先IPアドレスへパケットを送るには、どのインターフェイス(NICなど)を用いて、どのルータ(ホスト)へ送ればよいのかを示す対応表だ。
ルータAからホストYに対するIPパケットを渡された際の動作を考えてみよう。ホストYのアドレスは「192.168.20.12」なので、ルータBはルーティングテーブルから該当する経路を探す。「192.168.20.0/24」(サブネットマスクからネットワーク番号は24ビット目までと分かる)はネットワークを示すIPアドレスだが、「192.168.20.12」はこのサブネットに必ず所属しているはずだ。そこでルータBは、インターフェイス「192.168.20.253」から「192.168.20.12」へとパケットを送信すればよいことが分かるのである。これは最も簡単な転送例だ。
一番上に「192.168.1.0」の経路情報もあるのが分かるだろうか。今度は逆にホストYからホストXへの送信を考えてみよう。ルータBはホストX「192.168.1.10」へのパケットを届けなければならない。ルーティングテーブルを見ると、ここで「192.168.1.0」が発見できる。だが、先ほどとは多少経路情報の様子が異なっている。これは、「192.168.1.0」のサブネットへは自身では直接届けられず、ほかのルータを経由しなくてはならないからだ。この経由すべきルータ(ホストの場合もある)を、「ゲートウェイ」と呼ぶ。
ルータBはインターフェイス「192.168.10.253」からゲートウェイ「192.168.10.254」に対して、つまりルータAへパケットを転送する。おそらくはルータAでも同様に、ルーティングテーブルによってホストAを把握できるはずだ。こうしてパケットは無事ホストXまで届けられる。なお、ゲートウェイがインターフェイスと同じアドレスの場合は、そのサブネット内に目的のホストは存在しているという意味になる(要するにこの場合はゲートウェイは元々必要ではない)。
自身がつながっていない物理ネットワークへの経路情報も持たなければならない点は、少々意外に思われただろうか。原則として「到達する可能性のあるサブネットへの経路情報はすべて把握」していなければならない。でなければ、そのネットワークあてのパケットをどう取り扱うか解決できないためだ。その場合はルーティングエラーとして、ICMPのDestination Unreachable/Net Unreachableエラーなどが送信元ホストへ通知されることになる。
また、「メトリック」は、多くの場合「距離」という意味だ。例えば、ルータBから見て「192.168.1.0」は、別のルータ(ルータA)を1つ越えた先にあることを意味している。0は隣接しているという意味である。ルータを1つ越えることを「ホップ(Hop)」と呼び、メトリック値を用いて「ホストXはルータBの1ホップ先にある」などと表現する。
メトリックは、おもに目的のホストまで複数の経路が存在した場合に、より短い距離、つまり効率的な経路を選択するために登録されている*1。正確な値を示していなくてもルーティングは可能だが、過度の負担がネットワークにかかる恐れもある。こうした経路評価の方法を「“コストベース”のルーティング」と呼ぶことがある。
なお、現在ではあまり行われないのだが、元々ルーティングテーブルはホストのIPアドレスを記載しておくためのテーブルだった。だがそれでは、比較的小さなネットワークであっても膨大なエントリーを登録しなければならない。そこで、サブネットマスクを用いたサブネット単位で複数のホストをまとめて登録できるルーティングテーブルが、現在では一般的になっている。これを「VLSM(Variable Length Subnet Mask)方式」と呼ぶ。
上記注釈の経路判断アルゴリズムの解説において、RIP/RIP2が「距離ベクトル型」、OSPF/BGP4が「リンク状態型」としていたが、BGP4は「パスベクタ型」のアルゴリズムを採用している。この場を借りて修正させていただく。また、「距離ベクトル型」は「ディスタンスベクタ型」、「リンク状態型」は「リンクステート型」と表記されることもある。どちらも同じ事項を指しているので、随時読み替えていただきたい
すべてのホストはルータである
こうしたルーティング機能はルータに限ったことではない。ネットワークに参加するすべてのホストにも要求される。例えば、今この記事を見ているあなたのPCにも、ルーティング機能は同じように搭載されている。ルータは専用機器として、より確実な信頼性と柔軟性、性能を備えているが、普通のPCでも最低限のルータとしての利用が可能なのだ。
ここで1つの疑問が出るだろう。「では、インターネットに接続されているこのPCでも、インターネット上のすべてのルーティング情報を把握している」のだろうか?
先ほど述べたように、ルーティングのためには到達可能な範囲のルーティング情報を知らなければならないので、インターネット上の何個所かに存在しているIX*2などのように、さまざまなネットワークが集中するルーティングポイントでは、何万?何十万ものネットワーク分のルーティングテーブルを管理しなければならない。また、社内全体のネットワークを管理するルータでも、社内のすべてのネットワークへのルーティングテーブルを必要とすることだろう。
だが、個々の機器が全体の情報を管理するというのは、たいへん煩雑な作業だ。また、こうしたルーティング設定を個人のPCごとに設定するというのは、ほぼ不可能である。そこでルーティングテーブルを簡素化するために、通常は「デフォルトゲートウェイ」を設定する。
デフォルトゲートウェイとは、「ルーティングテーブルに登録されていないサブネット/ホストへの転送に用いるゲートウェイ」だ。例えば、皆さんの使っているPCであれば、まず間違いなくPCが接続されている物理ネットワークのルータがデフォルトゲートウェイとして設定されているはずだ。そしてデフォルトゲートウェイの設定によって、目的のホストの経路情報を持つルータまでパケットが到達できれば、ルーティングは可能になる。つまり、ルータ機能ではあるのだが、ほとんどの場合は非常に簡易なルーティング機能のみを使用しているに過ぎない。
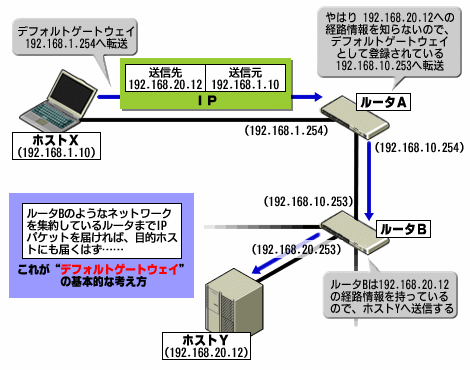 図2 デフォルトゲートウェイの利用。この例では、ホストXとルータAは「192.168.20.0」のネットワークを知らないので、デフォルトゲートウェイを利用している
図2 デフォルトゲートウェイの利用。この例では、ホストXとルータAは「192.168.20.0」のネットワークを知らないので、デフォルトゲートウェイを利用しているおもにサーバの場合になるだろうが、普通のホストでルーティングを気にしなければならないのは、インターフェイスを複数使用する場合だ。こうしたホストは「マルチホーム」などと呼ばれる。インターフェイスは、LAN接続のためのNICの場合もあれば、ほかの拠点とダイヤルアップ接続するために用いるモデムの場合もある。インターフェイスが1つであれば、デフォルトゲートウェイの設定だけで問題ないだろう。だが複数使用するのであれば、個々のインターフェイス間でルーティング(パケットの転送)を行うのかどうか、行うのならどのようなルーティングにするか、決めなければならない。
ルーティングは、普段はほとんど気にしなくても問題ない。だがほとんどのOSでは、こうした複数のネットワーク接続時に必要となるルーティングの設定方法を用意しており、WindowsやUNIXなどでは「route」コマンドがそれに相当する。
ルーティングの2つの設定方法
routeコマンドで行う設定とは「ルーティングテーブルの確認」と「ルーティングテーブルのエントリーの追加や削除」である。つまり、手動でルーティングテーブルを管理する方法だ。これを「スタティックルーティング」と呼ぶ。すでに説明したように、ルータやホストが接続されていないサブネットの情報も含めて、すべての経路を登録する必要がある。もちろん、起動後毎回実行しなければいけないわけではなく、ブート時に自動的に設定するようにもできる。
だがお分かりの通り、この設定作業は大変煩雑だ。すべてのネットワークの経路エントリーをまとめて、ルータごとにゲートウェイやメトリックを変更しなくてはならないだろう。特にルータが何台もあると、管理者の負荷は大変なものになる。
そこで、ルータ同士がルーティング情報を交換してルーティングテーブルを更新するためのプロトコルが考案された。これがRIP(Routing Information Protocol)である。現在では、VLSM方式を扱えるRIP2が多く用いられている。RIP/RIP2などによる動的なルーティングテーブル変更によるルーティング運用方法を「ダイナミックルーティング」と呼ぶ。
ダイナミックルーティングでは、ほかのルータからの経路情報を受信して自身のルーティングテーブルへ自動追加する。逆に、自身のルーティングテーブル情報も隣接するルータへ送信する。つまり、個々のルータでは隣接するサブネットの経路情報を登録/確認しておくだけでよいので、ネットワーク管理はかなり楽になる。また、メトリックを自動的に更新して最適な経路を判断できるようにすることも可能だ。ダウンしている経路はルーティングテーブルから削除されるので、ネットワークの効率化や耐障害性も向上する。多くの企業/団体の社内LANでは、現在はダイナミックルーティングによる運用が主となっている。
UNIX/Linuxにおける「routed」は、このダイナミックルーティングを実行するためのRIP/RIP2を実装したサーバ・アプリケーションだ。RIP/RIP2は大規模なネットワークには向かないが*3、イントラネットなど小規模なネットワークではよく利用されている。またWindows NT/2000では、RRAS(Routing and Remote Access Service)がRIP/RIP2を実装している。
だが。RIP/RIP2では自動的に情報が伝わるため、最終的にどのようなルーティングテーブルが作成されるのか把握は難しくなるので、その点への注意は必要だ。ダイナミックルーティングはルーティングを自動的に設定してくれる機能ではない。果たしてどのようにネットワーク全体のルーティングを行うのか、そうした設計やポリシーが基盤にあって初めて適用されるものだ。設定の手間を減らしてくれる機能だと考えてほしい。
そのほか、ルーティング全般については「連載:ルータの仕組みを学ぼう 第2回 イーサネットとルーティング」なども参考にしてほしい。
tracerouteで実際のルーティングを確認する
Windowsの「tracert」コマンド、UNIXやLinuxの「traceroute」コマンドは、あるホストから別のホストへの実際のルーティングの様子を確認してくれる。具体的にどのルータや中継ホストを通過するか確認するには便利だ。ルーティングが正常に行えていない場合には、どこで障害が起こっているか、確実に特定できる。
特に複数の経路があり得る場合、どちらの経路が実際に使用されているかはメトリックで判断されるが、ダイナミックルーティングではメトリックも常に更新されるため、実際に利用してみないとはっきりしない場合も多い。traceroute(tracert)コマンドを使うこと、これらを把握することができる。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。