ネットワーク監視対象に適したモニタリングとは:エンタープライズ・モニタリングのつぼ(前編)
ITはビジネス活動の根幹を支える基盤であり、そのダウンはビジネスに大きな影響を与えるようになっています。今日では、ITインフラストラクチャーのモニタリングは必須のシステム管理タスクです。
ところが、エンタープライズ環境を支えるITインフラストラクチャーは、さまざまなソフトウェア、ハードウェアによって構成されており複雑さを増しています。このため、エンタープライズ環境を漏れなく確実にモニタリングするためには、監視対象の特性に合ったいろいろなモニタリング手法に精通していなくてはなりません。
特集:「エンタープライズ・モニタリングのつぼ」前編では、ITインフラストラクチャーを支えるネットワーク機器をモニタリングする技術について解説します。
対象からモニタリング内容を分類してみる
初めに、モニタリングの概要について解説します。
1.モニタリングとは
モニタリングはシステム管理のタスクの1つです。モニタリングを日本語に直訳すると、「監視:不都合なことの起こらぬように見張ること」(三省堂「大辞林」 第二版より)となります。ITにおけるモニタリングは、さまざまなITリソースを見張ってITリソースが健全に働いていることを確認する作業ということになります。モニタリングはシステム管理のいろいろなタスク(サービスレベル管理、キャパシティ・プランニングなど)のベースとなる、非常に重要なタスクです。
2.モニタリングの分類
モニタリングと一言にいっても、その対象によってさまざまなタイプのモニタリングが考えられます。ITリソース全体に対して、漏れのないモニタリングの設計を行うためには、監視項目をカテゴリに分けて整理することが有効です。カテゴリ分けにはいろいろなやり方がありますが、ここでは出発点として下記のような分け方を用います。
| 監視のカテゴリ | チェック内容 |
|---|---|
| 稼働 | ネットワーク/サービスの応答有無をチェック |
| 障害 | ハードウェア・エラー、ソフトウェア・エラーをチェック |
| 性能 | ネットワークのパフォーマンスの問題をチェック |
| セキュリティ | ネットワークセキュリティに関するアラートをチェック |
| 表1 モニタリングのカテゴリと対応するチェック内容 | |
なお、今回モニタリングの対象とするネットワーク機器とは、ネットワーク・インフラを構成する要素であるルーター、スイッチ、ファイアウォール、負荷分散装置などとします。 これらの機器には監視専用のエージェントプログラムを追加導入することが困難なので、ネットワーク機器に標準的に実装されている技術を利用してモニタリングすることが必要です。
以降、このカテゴリごとにネットワーク監視技術を解説していきます。
稼働監視:ネットワーク/サービスの応答有無をチェック
稼働監視はネットワークやサービスの応答性のチェックを行い、ネットワークが正常に稼働しているかどうかを監視します。稼働監視は比較的容易な仕組みによって実装できるので、初歩的な監視タスクとして利用されています。
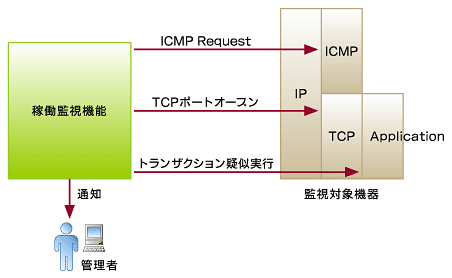 図1 監視要件によって異なる稼働監視技術
図1 監視要件によって異なる稼働監視技術稼働監視とひとまとめにしていますが、監視要件によって利用すべき技術が異なります。ここでは、ネットワークの稼働監視とサービスの稼働監視に利用できる技術を紹介します。
1.ネットワークの稼働監視
ネットワークの稼働監視に有用なプロトコルとしてICMPがあります。ICMPの実装はpingコマンドやtracerouteコマンドで親しまれています。ネットワークの疎通を確認するための最も基本的なステップとして、監視においてもICMPを活用することができます。いわゆるネットワーク・ノードとしての生き死にはICMPによって確認できます。
2.サービスの稼働監視
近年ネットワーク上に重要なアプリケーションが稼働するようになってきており、定常的なアプリケーションの稼働チェックを要求されることも多くなっています。HTTPやSMTPなどのアプリケーションのレベルで、サービスの稼働を監視することも必要です。サービスの稼働監視には、大別して下記の2通りの方法があります。昨今の監視ツールにはこのようなサービス稼働監視をサポートするものが多くなっています。監視要件のレベルに応じて、必要なサービス稼働監視の方法を選択します。
| 方法 | 内容 |
|---|---|
| TCPコネクション要求 | 該当サービスのTCPポートへコネクション要求を行い応答をチェックする。サービスが停止していればACKが返らないので、異常を判別できる |
| トランザクションの疑似実行 | 該当サービスのトランザクションを疑似的に生成して、応答(レスポンスコード、結果出力など)をチェックする。TCPコネクション要求に比べて高度なチェックが可能 |
| 表2 監視要件と稼働監視方法 | |
3.稼働監視の考慮点
稼働監視をする際には、リトライやタイムアウトのチューニングを正しく実施しておくべきです。無視できる瞬断や監視パケットロスなどで頻繁にエラーを通知して、おおかみ少年になってはいけません。
計画停止への対応も考慮すべきです。システムの計画停止中には稼働監視を停止して、無用なエラーが生じないような考慮が求められます。
監視間隔の考慮も重要です。監視を頻繁に行うとトラフィック量が増えて業務利用へ影響を与えることも考えられます。監視のきめ細かさと負荷のトレードオフがあることを念頭に置き、最適な監視間隔を決定します。
障害監視:ハードウェア・エラー、ソフトウェア・エラーをチェック
障害監視はハードウェアやソフトウェアのエラー・ログなどをチェックし、機器の正常な稼働を監視します。一般的なネットワーク機器の障害監視には、SNMPとsyslogが広く用いられています。
1.SNMP TRAPの活用
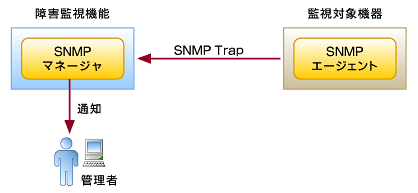 図2 SNMP TRAPによる障害監視
図2 SNMP TRAPによる障害監視SNMPはネットワーク管理のために規定されたプロトコルです(参考文献:RFC1157 A Simple Network Management Protocol(SNMP))。SNMPの管理情報をやりとりする方法には、大別してMIB取得とTRAP受信という2つがあります。障害監視には即時性が求められるため、非同期な特性を持つSNMP TRAP受信の方が機能的にマッチします。昨今の企業向けネットワーク機器の多くはSNMPに対応しており、障害情報をSNMP TRAPとしてSNMPマネージャ機能を持つ監視サーバへ通知できます。
2. syslogの活用
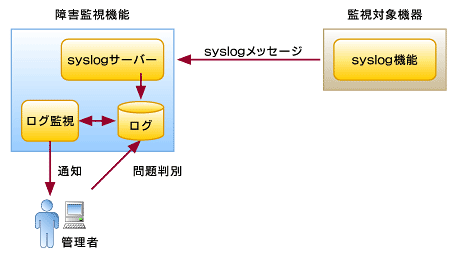 図3 syslogによる障害監視
図3 syslogによる障害監視syslogはUNIX BSDで実装されたログ機能です(参考文献:RFC3164 syslog Protocol)。OSやアプリケーションのログを、ローカルのログファイルやネットワークを隔てた別のsyslogサーバへ記録します。昨今の企業向けネットワーク機器には、重要な障害情報をsyslogサーバへ転送できるように設計されているものがあります。
syslogを用いた一般的な監視方法は、ネットワーク機器からsyslogサーバ上に出力されたログファイルを定期的にパターンマッチングして、重要なログイベントだけを管理者へ通知するという方法です。ログファイルは、問題発生時に資料としても利用できます。
3.障害監視の考慮点
SNMP、syslogともに、機器がサポートするイベントの種類が複数あります。監視するイベントの種類と対応方法を予め明確にしておくべきです。参考情報としては、MIBファイルの記述、syslogについては機器固有のメッセージガイドなどが挙げられます。
稼働監視と同じように、syslogやSNMPによるイベント転送が大量に発生すると、トラフィック量の観点で問題です。重要度に応じてイベント送信の可否を設定できるネットワーク機器もありますので、そのようなフィルタリング機能を利用して通知すべきイベントを絞り込んでおくべきです。
性能監視:ネットワークのパフォーマンスの問題をチェック
性能監視はネットワークのパフォーマンスの問題を継続的にチェックします。ネットワークの性能がサービスレベルとして管理されることも多くなってきています。サービスレベルの順守状況を把握するという観点からも、性能監視は非常に重要なタスクとなります。
1.MIBによる性能監視
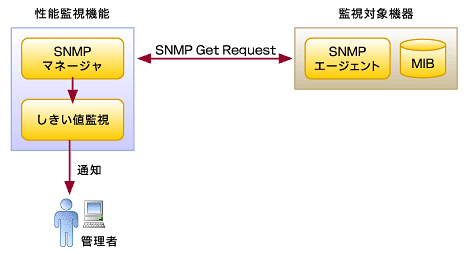 図4 MIBによる障害監視
図4 MIBによる障害監視ネットワーク機器の性能監視にはSNMPを活用することが一般的です。性能監視には定期的なカウンタのチェックが必要になるため、SNMPのやりとりのうちMIB取得を利用することが一般的です。
MIBによるネットワーク機器の監視項目には、回線利用率/エラー数/CPU/バッファなどさまざまなものがあります。監視対象の機器によってサポートされるMIBが異なるため、性能監視の設計の際には機器がサポートするMIB情報を調査する必要があります。例として、筆者がCiscoルーターを監視する際にひな型とする監視項目一覧を挙げます。
| 項目 | 単位 | MIB | 備考 |
|---|---|---|---|
| CPU使用率 | % | avgBusy5 | 過去5分の平均使用率 |
| 空きメモリ | byte | freeMem | 瞬間値 |
| 回線使用率 | % | 受信 ifInOctets * 800 / ifSpeed 送信 ifOutOctets * 800 / ifSpeed |
監視間隔の平均値 全二重の回線では受信と送信を分けて監視する |
| エラーパケット数 | 数 | 受信 ifInErrors 送信 ifOutErrors |
全二重の回線では受信と送信を分けて監視する |
| 表3 監視項目一覧の例 | |||
2.応答時間について
昨今ではアプリケーションの利用者がインターネットへも広がり、利用者の満足度がビジネスへ影響を与えることも多くなっています。このような状況において、性能項目として、利用者の視点から見た応答時間の重要性が増しています。一方、応答時間をMIBで提供しているデバイスは少ないため、この課題に対してSNMP/MIBによるアプローチには限界があります。解決策として、システム管理ツールの各ベンダは製品機能として、それぞれ工夫を凝らした応答時間の監視方法を提供しています。このうち、ネットワークレベルにおける応答時間の監視方法としては、サービス稼働監視と同様の手法で、ICMPやアプリケーションのレベルで応答時間監視を行うことができます。
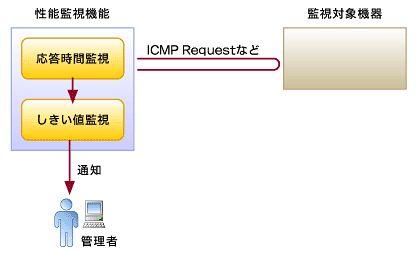 図5 性能監視と応答時間監視の概念
図5 性能監視と応答時間監視の概念3.性能監視の考慮点
ネットワーク機器の性能監視を行う際に難しいのは、閾(しきい)値の決定方法とそれへの対処方法を検討することです。CPUやメモリなどの指標に関しては、ベンダから閾値がガイドされていることがあります。Ciscoであればベストプラクティスとして以下の書籍に閾値の例が紹介されています。
参考書籍:Performance and Fault Management (Cisco Press Core Series)
一方、回線使用率、エラー率などのネットワークそのものに関する項目については、環境依存の部分が大きいので、一概に閾値を決められません。1つのアプローチとして、運用を通じて定常値を把握し、チェックすべき閾値を決定するという考え方があります。
セキュリティ監視:ネットワークセキュリティに関するアラートをチェック
ネットワークを運用するうえで、セキュリティは切り離せないテーマになっています。セキュリティ監視は、ネットワークの保全を目指してセキュリティ違反をリアルタイムに監視します。
セキュリティを守るため、現在のITインフラストラクチャーにはFirewall、侵入検知システム(IDS)、侵入防御システム(IPS)、アクセス制御システムなどなど、さまざまなセキュリティ管理製品が導入されています。これらのセキュリティ管理製品が日々生成するセキュリティアラートは企業にとって重要ですので、適切なモニタリングが必要です。
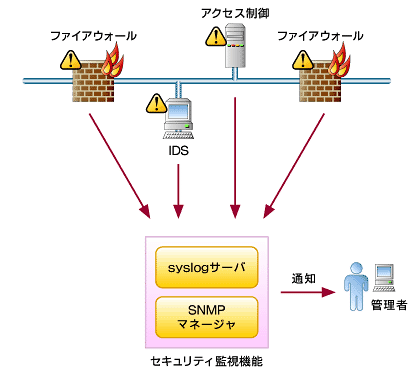 図6 セキュリティアラートの収集
図6 セキュリティアラートの収集1.侵入検知システム(IDS)による監視
IDSはコンピュータやネットワークへの侵入行為を監視して、それを管理者へ通知します。IDSは監視を行う場所により、ネットワーク型とホスト型の2つに大別することができます。ネットワーク型IDSはLANアナライザに似た技術を用い、ネットワーク上を流れるパケットから侵入行為を見つけ出します。ホスト型IDSは、ホスト上のログやネットワークインターフェイスで侵入行為を発見します。IDSは専用のコンソールやSNMPマネージャなどへ異常を通知しますので、通知部分は障害監視と同様の仕組みで対応することができます。
2. Firewallのログ監視
Firewallのログには、禁じられたポートへのアクセス違反などのセキュリティアラートが記録されます。アクセス違反を大量に生成しているIPアドレスがあれば、異常な機器として対処を検討すべきです。多くのFirewallは専用のログファイルやsyslogサーバへログ情報を記録します。ネットワーク機器のログ監視と同様に、syslogを用いてログを収集し、監視を行うことができます。
3.セキュリティ監視の考慮点
一般的にセキュリティアラートは大量に発生しがちです。例えば、DoS攻撃などのケースでは、アクセス違反のエラーが大量に発生することが容易に想像できるでしょう。セキュリティアラートを監視する際には、大量イベントへの対応を意識しておくことが必要です。対策として、ログと通知のレベル分けを検討する、フィルタリングを用いて重要なイベントのみに注目する、などが考えられます。一歩進めて、セキュリティアラートの相関分析を自動的に行う製品も出始めていますので、それらの利用も一考に価するでしょう。
後編はサーバやアプリケーションのモニタリング技術について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。