
いまどきのサーババックアップ戦略入門(3)
バックアップのあり方を変える新技術
株式会社シマンテック
成田 雅和
2007/10/26
 重複データ排除
重複データ排除
データ量が年率60%以上で伸び続けているということを、この連載の冒頭で紹介したが、伸びているデータの中身の大半はメールとファイル(オフィス系ドキュメント)である。これは読者も身の回りの状況を見て実感するところであろう。メールとドキュメントは重複する部分が非常に多く、重複は平均して1つ当たり50カ所になっているともいわれる。
メールを例にしよう。何人かに同じ内容を「to」や「cc」で同報することは、メールの便利な利用方法の1つとして広く行われている。このとき、同報されたこの1通のメールは同じデータであるにもかかわらず、メールサーバ上の個人のメールボックスとして見た場合はそれぞれが異なるデータとなる。そのためすべてのデータがバックアップとして保管される。さらに、同報されたメールに添付ファイルがあり、それを各人がファイルサーバ上のホームディレクトリに保存したとすると、これらの添付ファイルは同じデータであるにもかかわらずパス名が違うので、バックアップソフトからは別データとして取り扱われる(つまり、それぞれがバックアップされる)。
また、ドキュメントについては、ファイルとして異なるデータであっても部分的に同じデータが含まれるというのはよくあることだ。何らかのドキュメントを作成する際に、既存資料を一切使用せずに新規に作成するケースはゼロではないだろうが、大抵の場合、テンプレートを利用したり、類似のドキュメントをコピーしてひな型として利用したりして、ドキュメント作成効率を上げる工夫はしているだろう。あるいは万一のファイルの破損に備え、ファイルをコピーしたうえで編集を行うということも広く行われている。このような場合、複数のドキュメントファイルに部分的に同じデータが含まれることになるが、従来のバックアップソフトはファイル内容が違うということですべてをバックアップする。
このような方法でも従来は問題なく処理できていたが、メールやドキュメントファイルの増加と1件当たりのデータサイズの増加、それによって引き起こされるコスト増と時間消費が許容できなくなりつつあるというのが現在の状況である。
重複データ排除はこういった状況に対する解決策として登場し、利用が広まりつつある新技術である。
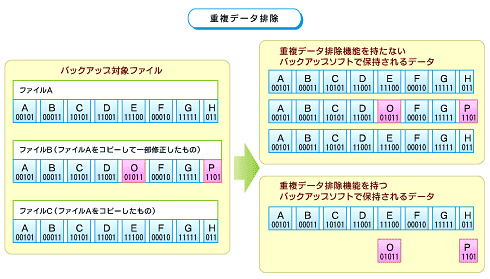 |
| 図3 重複データ排除では同一の情報を持つデータブロックを2度バックアップしない |
図にあるように重複データ排除機能がない従来のバックアップソフトでは、異なるファイルとして認識するためにすべてのデータをバックアップしてしまう。一方、重複データ排除機能があるバックアップソフトでは、基になるファイルのデータと別ファイルの変更部分のデータのみが保持されため、バックアップ先のデータ容量を大幅に削減しコストダウンを実現することが可能だ。また、重複データ排除の際に、重複の有無をバックアップクライアント側で判断する方式の場合、重複しているデータはバックアップサーバに送信しないためネットワーク上でのデータ転送量も削減される。これは遠隔地のバックアップにも都合が良い。
重複データ排除機能はハッシュ値を管理することで実現されている。ハッシュ値とは、あるデータ列に対してそのデータ内容を代表する値をいう。ハッシュ値を生成するハッシュ関数は、1)似たデータ列から似たハッシュ値が生成されない、2)異なるデータ列から同じハッシュ値が生成されない(コリジョンが起きない)という性格をもつように設計されている。数kB〜数MBのデータ列から数百ビットのハッシュ値を生成して使用することが多い。
重複データ排除機能は、このハッシュ値を比較することで実現している。ファイルをある単位で区切り、そのデータ列のハッシュ値を計算し、すでにバックアップ済のデータ列のハッシュ値と比較することで重複の有無を判断する。ハッシュ値の特性としてコリジョンは起こらないが(理論上は起こり得るが現実的には無視し得る頻度)、コリジョン発生の場合には異なるデータ内容をリストアしてしまうということなので、コリジョン対策として別の比較方法も併用される。
この機能は、ハッシュ関数の計算や一致するハッシュ値の有無の検索などの処理が、CPU性能の向上により高速化したことで利用可能となった。
負荷分散
複数のバックアップサーバを使用してバックアップを行っている環境で有効な新技術が負荷分散機能である。バックアップサーバが複数台になると、どの業務サーバをどのバックアップサーバで処理するかというジョブアサイン/ジョブスケジュールの設計が必要になる。業務サーバのデータ量の増加がバックアップサーバの処理能力を超えるほどになったり、業務サーバごとの更新量のばらつきが大きくなったりする場合、当初の設計どおりのジョブアサインが最適でなくなってしまうこともある。また、バックアップサーバを新規で追加した場合に、既存のジョブ設計をすべて変更する必要が出てしまう。
バックアップの負荷分散機能はこのような状況を解決するための機能である。バックアップサーバにバックアップ用ストレージやテープライブラリ装置を接続し、どのバックアップジョブも同じように実行できるように準備しておく。バックアップジョブを実行する際には最も負荷の低いバックアップサーバを介してバックアップを実行することができる。これによりバックアップジョブの再設計や、前のジョブが何らかの理由で想定時間以内に終了しなかったような場合でも空いているバックアップサーバを利用してジョブを実行することが可能だ。
以上、バックアップ技術の最近の進展とサーババックアップへの活用について紹介した。次回は災害対策としてのバックアップや、遠隔拠点のバックアップについて触れる予定である。
3/3 |
| Index | |
| バックアップのあり方を変える新技術 | |
| Page1 無停止バックアップ スナップショット |
|
| Page2 個別アイテムのリストア 連続データ保護(CDP) |
|
| Page3 重複データ排除 負荷分散 |
|
- Windows 10の導入、それはWindows as a Serviceの始まり (2017/7/27)
本連載では、これからWindows 10への移行を本格的に進めようとしている企業/IT管理者向けに、移行計画、展開、管理、企業向けの注目の機能について解説していきます。今回は、「サービスとしてのWindows(Windows as a Service:WaaS)」の理解を深めましょう - Windows 10への移行計画を早急に進めるべき理由 (2017/7/21)
本連載では、これからWindows 10への移行を本格的に進めようとしている企業/IT管理者に向け、移行計画、展開、管理、企業向けの注目の機能を解説していきます。第1回目は、「Windows 10に移行すべき理由」を説明します - Azure仮想マシンの最新v3シリーズは、Broadwell世代でHyper-Vのネストにも対応 (2017/7/20)
AzureのIaaSで、Azure仮想マシンの第三世代となるDv3およびEv3シリーズが利用可能になりました。また、新たにWindows Server 2016仮想マシンでは「入れ子構造の仮想化」がサポートされ、Hyper-V仮想マシンやHyper-Vコンテナの実行が可能になります - 【 New-ADUser 】コマンドレット――Active Directoryのユーザーアカウントを作成する (2017/7/19)
本連載は、Windows PowerShellコマンドレットについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、「New-ADUser」コマンドレットです
|
|
注目のテーマ





